Transformer #2 - Self Attention
0. Introduction
다른 글에서 Attention Mechanism에 대해서 알아보았습니다.
Attention Mechanism에 대해서 자세히 알아보시려면 아래 글을 읽어보시기를 추천드립니다.
Transformer #1 - Attention Mechanism
Transformer에서는 Attention 적용에 있어서 조금 더 발전된 Self Attention이라는 방법을 사용하고 있습니다.
Self Attention의 핵심 Idea는 ‘입력 Text에 존재하는 단어들 사이의 관계를 파악’ 해보자는 것입니다.
The snake is very dangerous because it has a venom.
이 문장에서 it이 snake를 가리킨다는 것을 안다면 문장에 대한 이해력이 더 좋아질 수 있겠죠.
이를 구현하고자 Query, Key, Value 개념이 소개됩니다.
Query 값은 현재 처리하고 있는 요소, 예를 들면 입력으로 들어와서 처리하려고 하는 단어에 대한 Vector입니다. 모델이 어떤 입력 요소에 주목해야 할지를 결정하기 위해서 사용됩니다.
Key 값은 입력 시퀀스의 각 요소를 나타내는 Vector이고, 이 값을 Query 값과 비교할 때 사용합니다. Query와 Key 값의 연산을 통해서 어떤 입력 요소가 현재 출력에 중요한지 결정하기 위해서 사용합니다.
마지막으로 Value 값은 Key와 Dictionary 형태로 연결되어 있으며 가중치에 따라서 실제 Weighted Sum을 계산할 때 사용합니다.
Self Attention이 기존 Attention 과의 차이점은 아래 그림과 같이 입력의 Embedding이 Wq, Wk, Wv를 거쳐서 Q, K, V Vector 값을 가진 후에 다음 처리가 이루어진다는 것입니다.
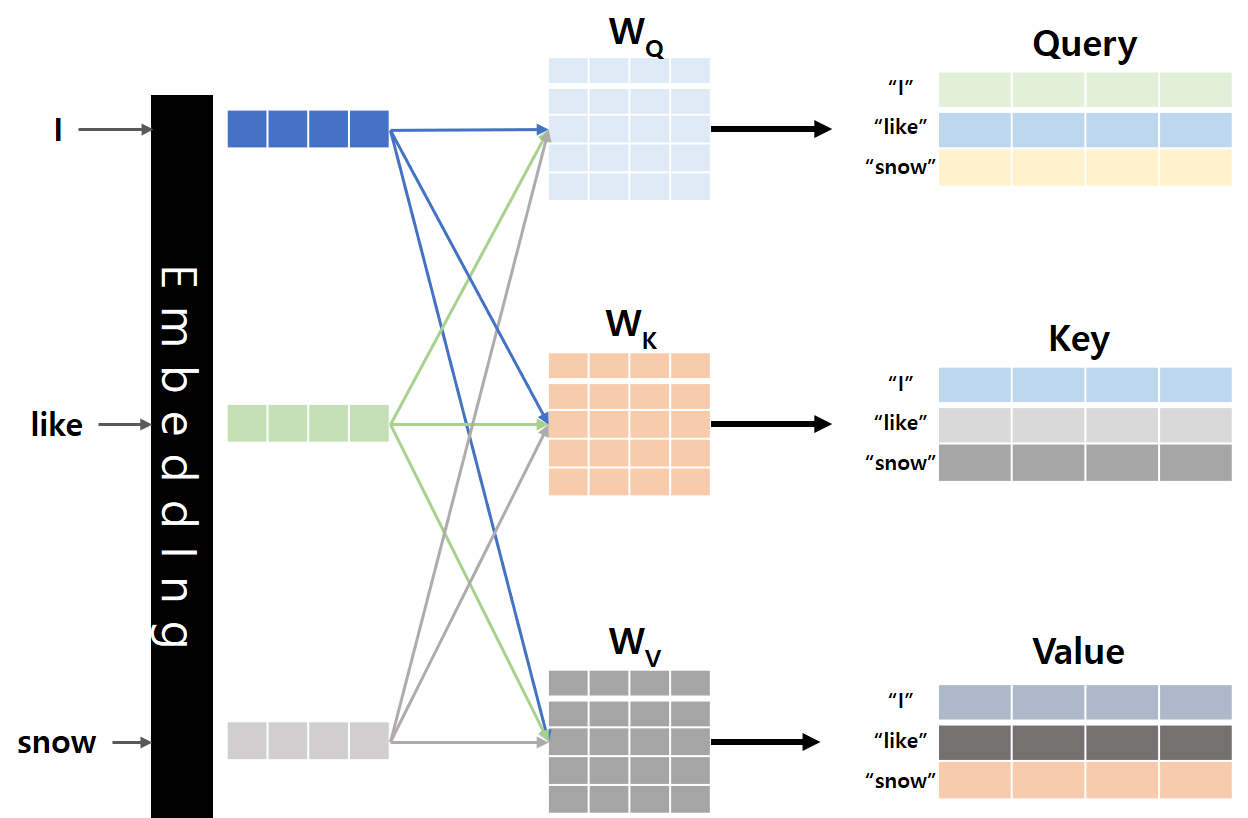
Query, Key, Value 개념이 도입된 이유에 대해서 알아본다면, Model이 좀 더 인간과 유사하게 문장을 바라볼 수 있도록 하기 위해서입니다.
인간은 특정 작업에 집중할 때 관련 정보를 선택적으로 집중하고 다른 정보는 무시해 버리는 특성이 있습니다.
Query, Key, Value는 이런 ‘주의 집중’ 특징을 Model로 구현하고자 만들어진 개념이라고 볼 수 있습니다.
Attention Mechanism의 Query, Key, Value는 입력 Text의 단어들에 대해서 중요도를 가변적으로 조정하고, 각 단어들을 동일하게 처리하는 것이 아니라
각 단어들의 중요도에 따라 다르게 처리함으로써 Model의 성능을 향상시켜줍니다.
1. Example
Self Attention이 실제 어떻게 수행되는지 예제를 통해서 알아보도록 하겠습니다.
우선, 입력 단어는 3개라고 가정하고 Embedding Size는 3이라고 해 보겠습니다.( 실제 Transformer에서는 512인 Embedding을 사용합니다. )
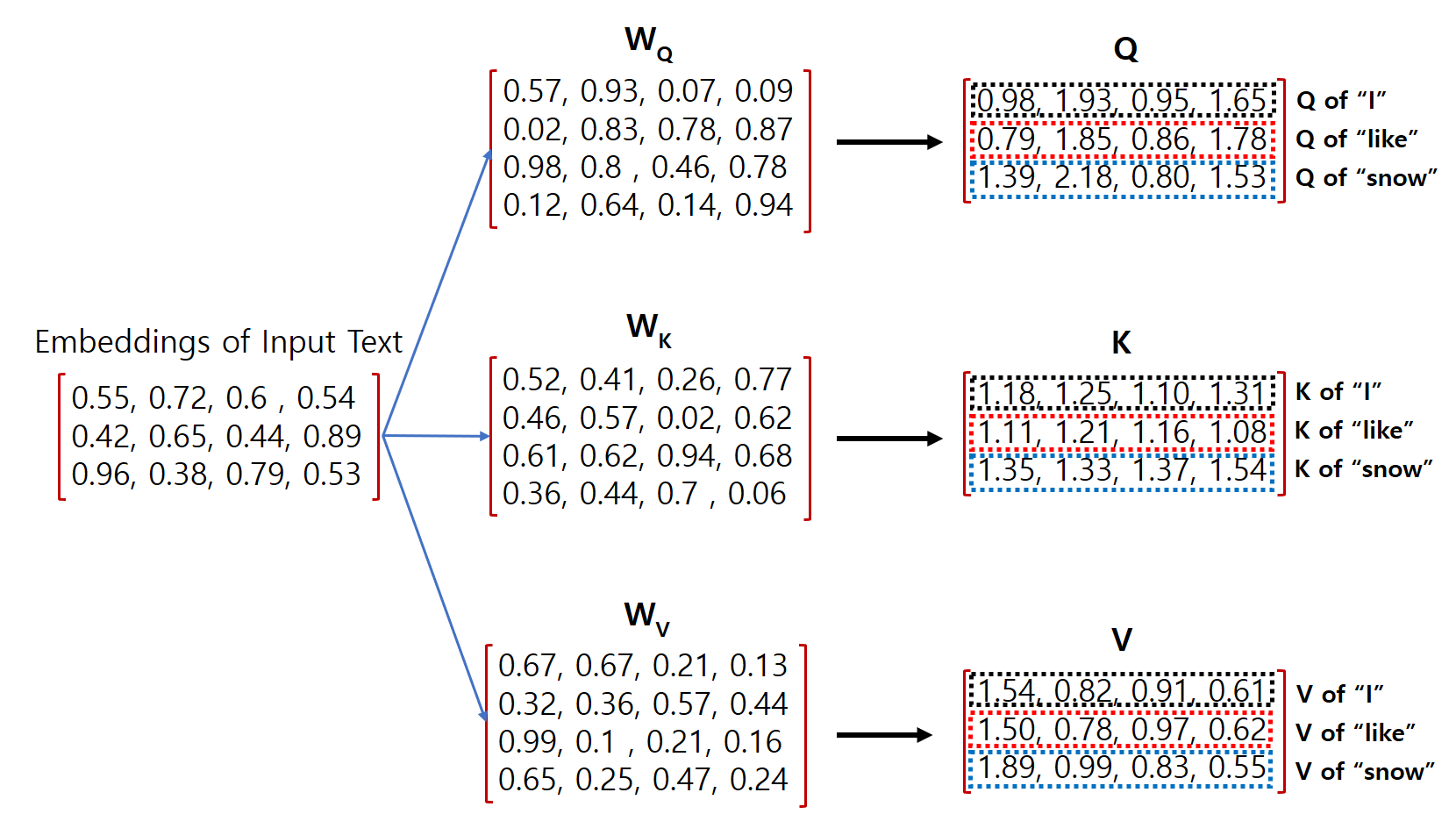
그리고, Q, K, V Vector의 Size는 4라고 가정하고, 실제 값은 아래와 같다고 해보겠습니다.

Q, K.V Size가 4가 되려면 Wq, Wk, Wv는 4x4가 되어야 하고, 실제 값은 아래와 같다고 가정해 보겠습니다.

이제, Self Attention 값을 계산할 수 있습니다.
1.0. Q.K.V Vector 계산
각 입력 단어의 Embedding과 Wq, Wk, Wv 값을 알고 있다면 다음과 같이 Matrix 형태의 계산으로 각 입력 단어의 Q, K, V Vector를 계산할 수 있습니다.
1.1. Attention Score 계산
Q, K, V 값을 구한 다음에는 각 단어의 Attention Score를 구합니다.
Attention Score는 Q 와 KT의 내적으로 구할 수 있습니다. Veoctor의 내적이란 두 Vector의 유사한 정도를 수치로 표현할 수 있는 방법입니다.

1.2. Weight 계산
앞서 구한 Attention Score에 Softmax를 취해서 가중치를 계산합니다.
이때 주의할 점은 Attention Score 행렬 전체의 값에 대한 Softmax를 취하는 것이 아니라, 각 행별로 Softmax값을 취해야 한다는 것입니다.

1.3. Self Attention 계산
마지막으로 앞에서 계산한 Weight와 V값을 곱해서 각 입력 단어의 Self Attention 값을 계산합니다.

위와 같이 계산된 최종 Self Attention Vector이고 이 값들은 Transformer 학습에 기본이 되는 값들입니다.
다음 Post에서는 Transformer의 전체적인 구조 및 학습 방법을 Encoder와 Decoder로 나눠서 알아보도록 하겠습니다.
감사합니다.