Transformer #4 - Encoder Detail
안녕하세요, 이번 Post에서는 Transformer의 Encoder에 대해서 자세히 알아보도록 하겠습니다.
Transformer Encoder의 각 부분을 구체적으로 하나씩 알아보도록 하겠습니다.
0. Tokenizer & Input Embedding Layer
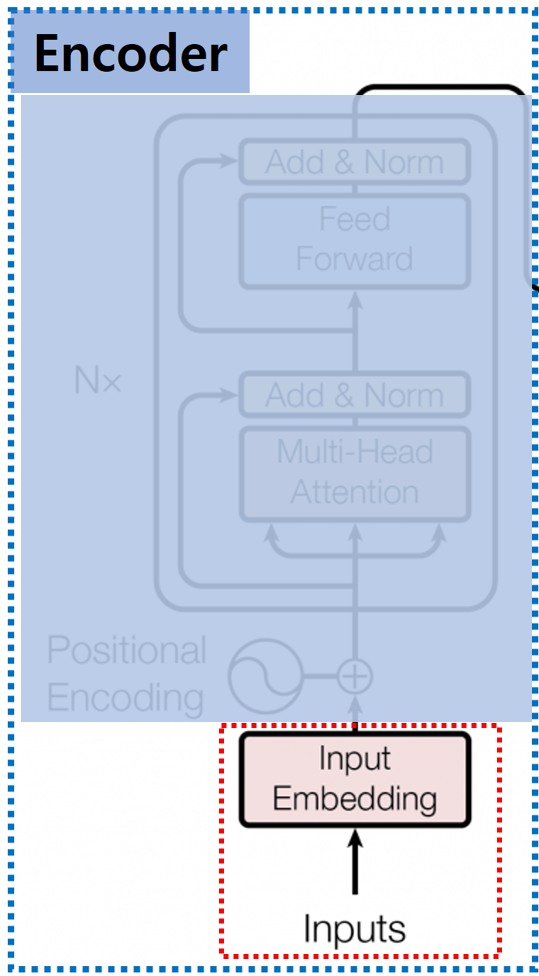
Embedding Layer에 문장 그대로 입력할 수 없기 때문에 문장을 Model이 사용할 수 있는 Vector 형태로 변환해야 합니다.
Tokenizer를 이용해 문장을 Token 단위로 나누고, 나눈 Token을 Embedding Layer에 입력하여 Model이 이해할 수 있는 Vector 형태로 만듭니다.
Transformer는 WordPiece Tokenizer를 사용하여 Token을 나누며, Transformer의 Embedding Layer는 각 Token을 512 크기의 Vector로 출력합니다.
1. Positional Encoding
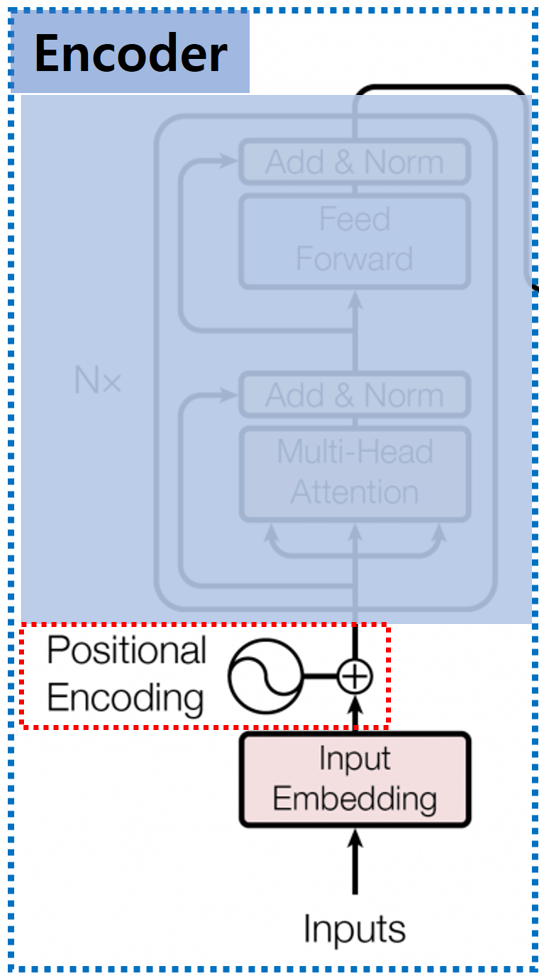
Transformer는 이전의 RNN / LSTM을 이용한 Sequential Model과 다르게, 입력을 한 번에 처리하기 때문에 얻는 장점도 있지만 그로 인해 생기는 문제도 있습니다.
대표적인 각 입력 단어의 위치에 대한 정보를 입력할 수 없다는 것입니다. Sequential Model에서는 단어를 한 번에 하나씩 입력하기 때문에
자연스럽게 입력 순서 정보, 즉, 위치 정보가 포함되게 됩니다.
하지만, Transformer에서는 한 번에 입력을 처리하게 때문에 각 단어가 입력 문장에서의 위치 정보를 잃게 됩니다.
이를 해결하기 위해서 논문에서 제시한 방법이 Positional Encoding입니다.
Positional Encoding은 삼각함수 Sin / Cos을 이용해서 각 입력값의 위치 정보를 Embedding 값에 더해주는 방식입니다.
Positional Encoding 값 P.E.(i, j)는 아래의 수식과 같이 계산합니다.
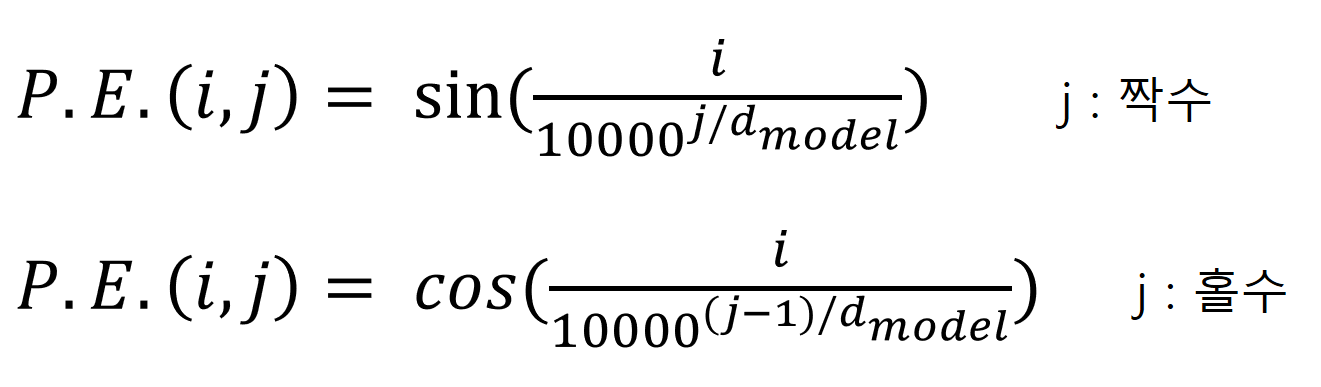
여기서 i 값은 i 번째 단어, 즉, 입력 단어의 순서이고, j 값은 Embedding 값의 원소 위치이며, i, j는 0부터 시작합니다. dmodel은 Transformer의 차원의 크기로 논문에서는 512입니다.
실제로 P.E. 값은 아래와 같은 형태를 나타냅니다.
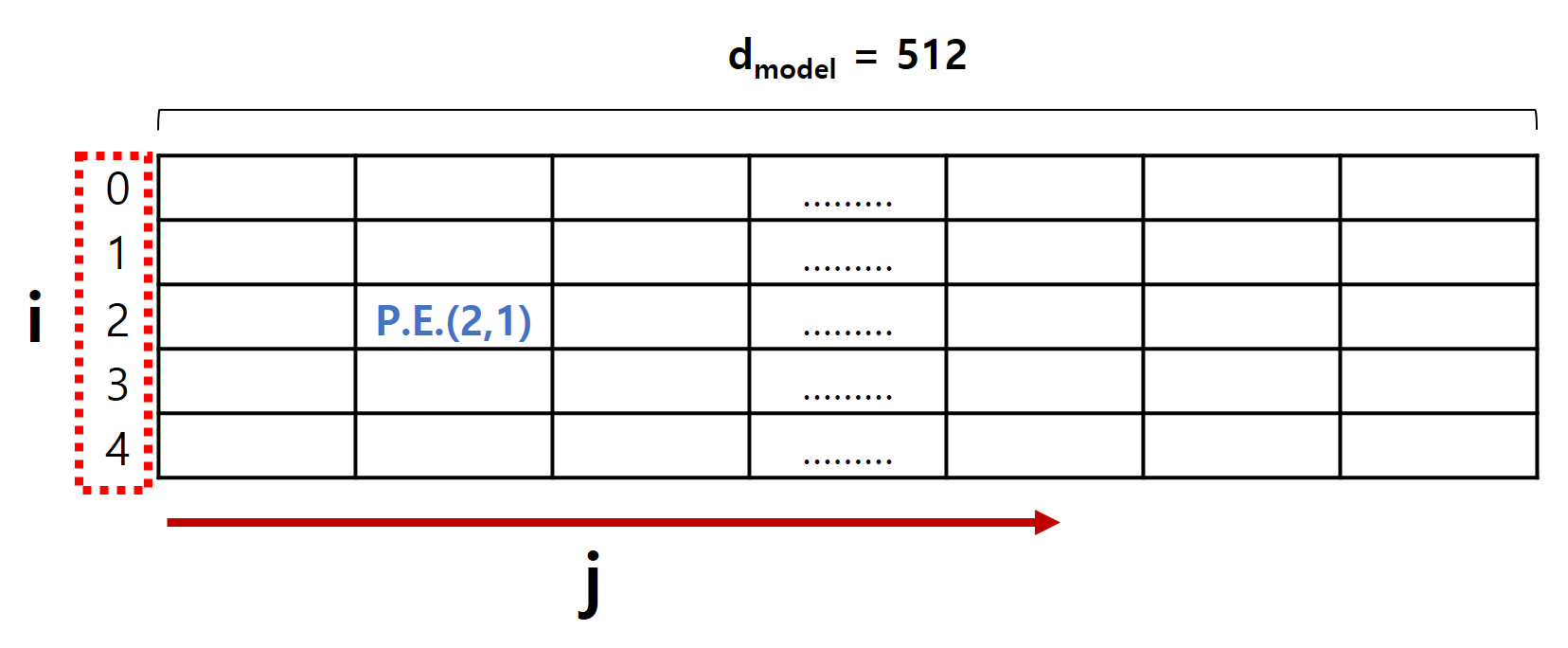
계산식을 자세히 보시면, P.E. 값은 학습하는 값들이 없이 모두 미리 계산 가능한 상수들입니다.
계산한 P.E. 값들과 Embedding Layer에서 나온 출력값을 Summation 해서 다음 단계로 넘깁니다.
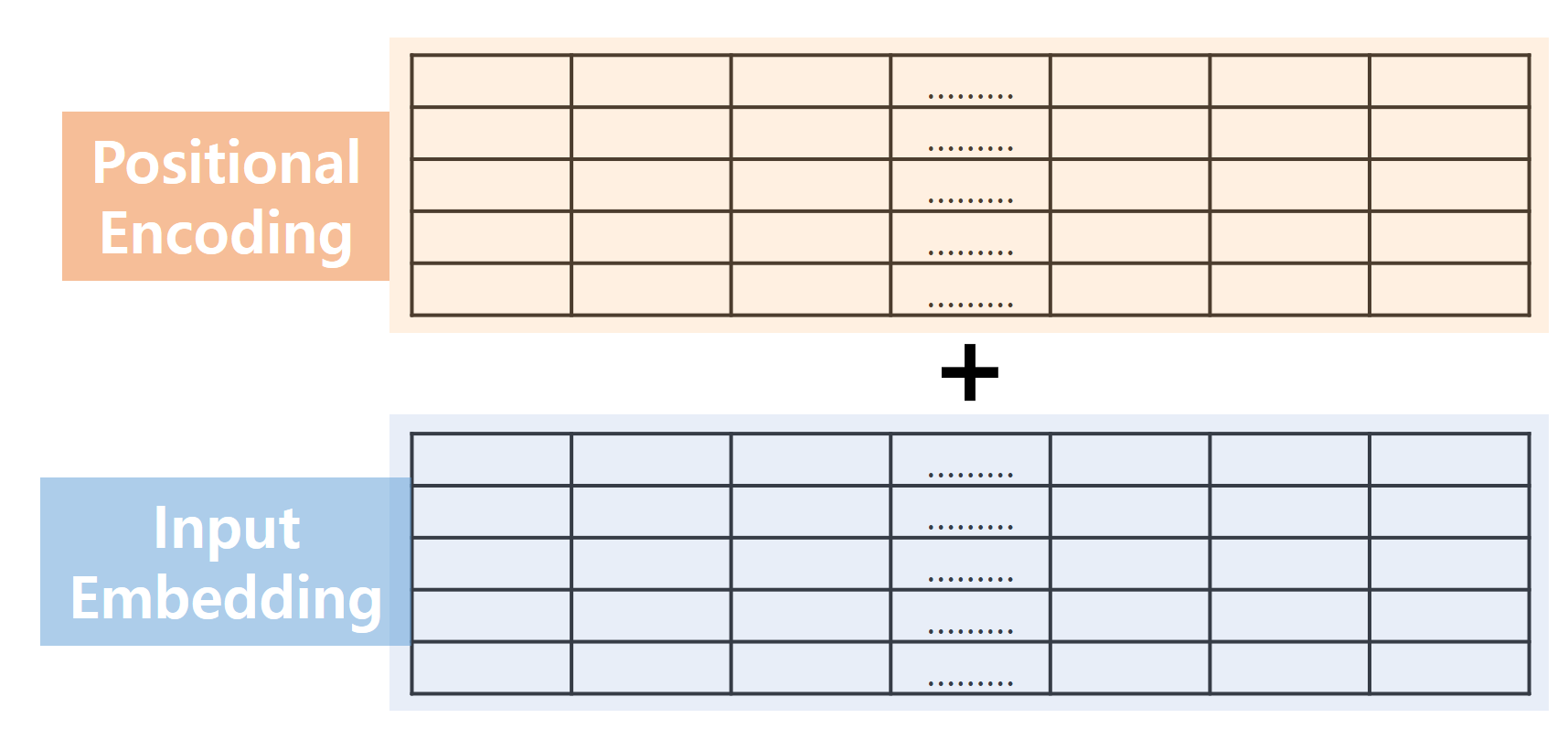
Concatenate 하지 않고 Summation 한 이유는 여러 가지 있겠지만 차원 크기 / 계산 용이성 등 여러 가지 고려해서 Summation을 선택한 것으로 생각됩니다.
2. Multi-Head Attention
Positional Encoding을 거친 값들의 Attention 값을 구해야 합니다. Transformer에서는 앞서 살펴본 Self Attention 구조를 확장한 Multi-Head Attention 구조를 사용합니다.
기존 Self Attention 구조와 차이점은 무엇인지 살펴보겠습니다.
2.0. Introduction
앞서 알아본 Self Attention에서는 Q, K, V Vector를 만들 때 단어의 Embedding에 Wk, Wq, Wv를 곱해서 값을 만들어 냈습니다.
이때, Wk, Wq, Wv를 여러 개 만들어서 하나의 단어에 대해서 여러 개의 Q, K, V Vector를 만들겠다는 것이 Multi-Head Attention의 핵심 아이디어입니다.
이렇게 하면 주목해야 하는 단어가 무엇인지를 더 잘 파악할 수 있고, 더불어 각 단어가 갖고 있는 문맥적 특성을 더 잘 표현할 수 있다는 장점도 있습니다.
최종적으로는 여러 개의 Wk, Wq, Wv에서 나온 Attention 값을 Concat 하고 W0라고 하는 값을 곱해서 Z0(Blended Vector)를 계산한 후에 여기에 개별적으로 Fully Connected 해서 Z를 출력하는 과정을 거칩니다.
이와 같은 연산을 하기 위해서는 입력 Vector(각 단어들의 Embedding)고 Z0, Z는 모두 같은 차원이 되어야 합니다.
Positional Encoding을 수행하면 Backpropagation 할 때 정보가 사라지는 경우가 있으므로 Residual Connection으로 이를 보완해 줍니다.
입력 Vector와 최종 출력 Z가 동일한 차원을 가지고 있기 때문에 Encoder를 여러 개 붙이는 것도 가능합니다.
2.1. Multi-Head Attention
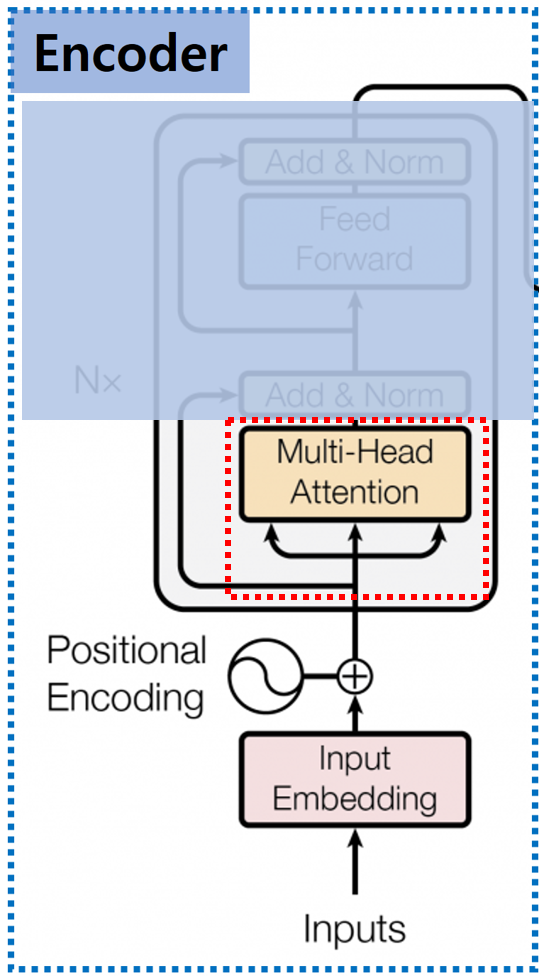
그럼, Multi-Head Attention이 실제로 어떻게 계산되는지 한 번 알아보도록 하겠습니다.
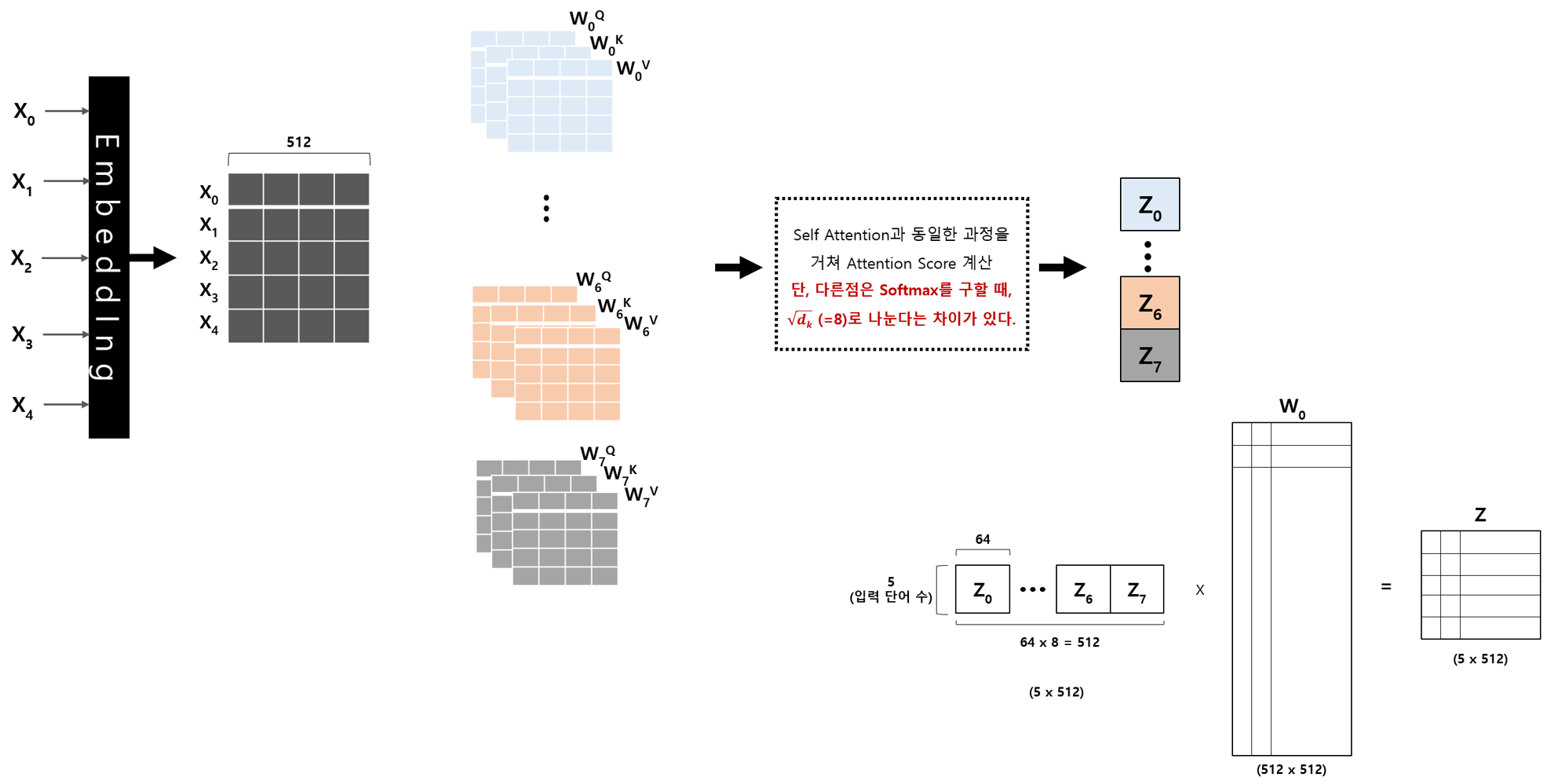
먼저 아래 그림이 전체적인 Multi-Head Attention의 흐름도입니다.
입력은 5개의 단어라고 가정하고, 최종적으로 얻는 것은 Z Vector입니다.
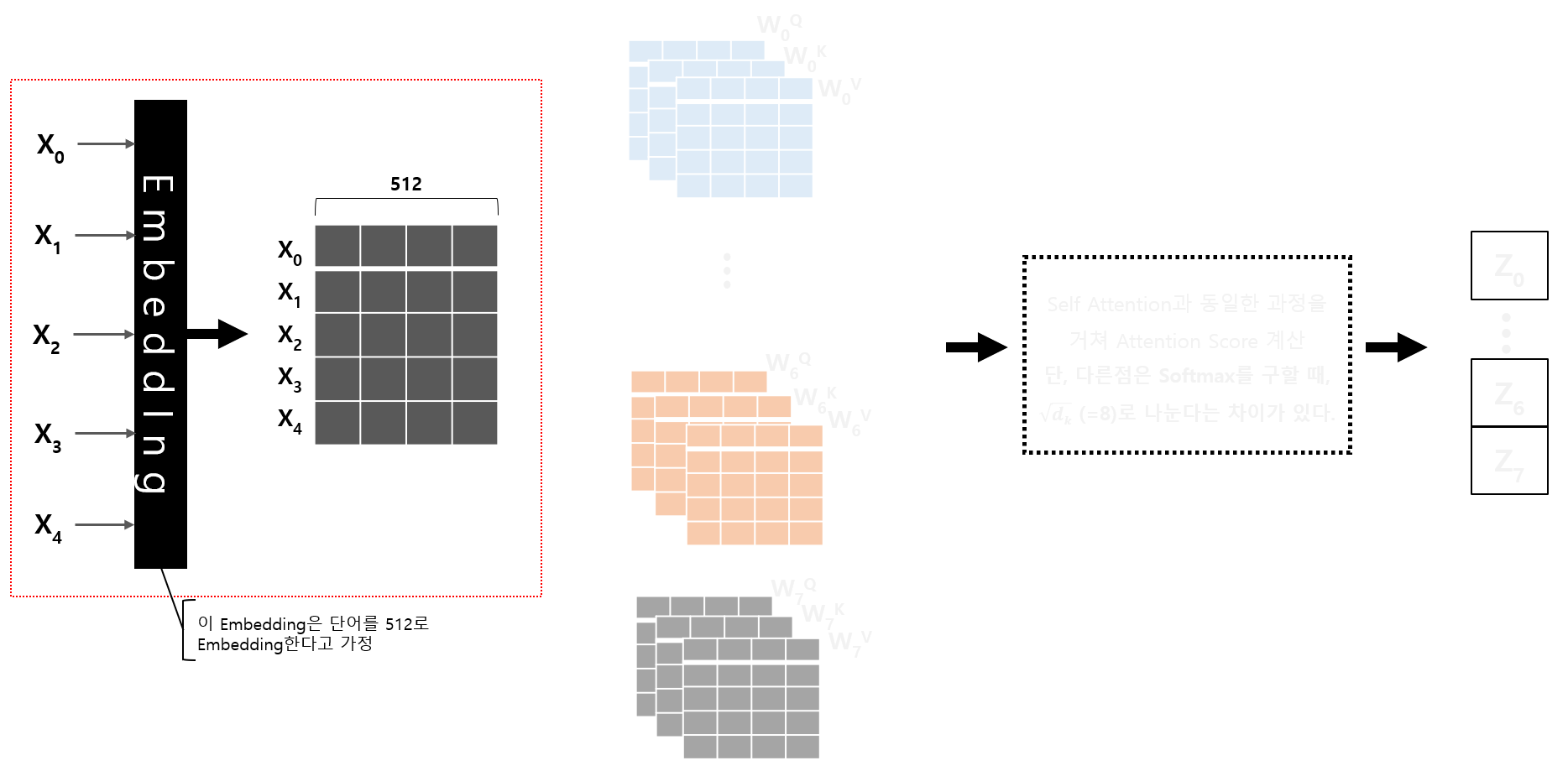
먼저 아래 그림과 같이 입력 단어 5개를 각각 Embedding Layer를 통과시킵니다.
이 Embedding Layer는 각 단어를 512로 Embedding 한다고 가정해 보겠습니다.
5개 단어가 각각 512로 Embedding 되고, 모두 합쳐서 (5 x 512) 크기의 Vector가 생깁니다.
이전 Self Attention에서는 각 단어의 Embedding Vector에 하나의 WK, WQ, WV를 곱해서 Q,K,V 값을 계산하였으나
Multi Head Attention에서는 WK, WQ, WV 행렬이 Head 수(논문에서는 Head를 8로 설정했습니다.)만큼 만들고,
Embedding Vector를 각각의 WK, WQ, WV에 곱합니다.
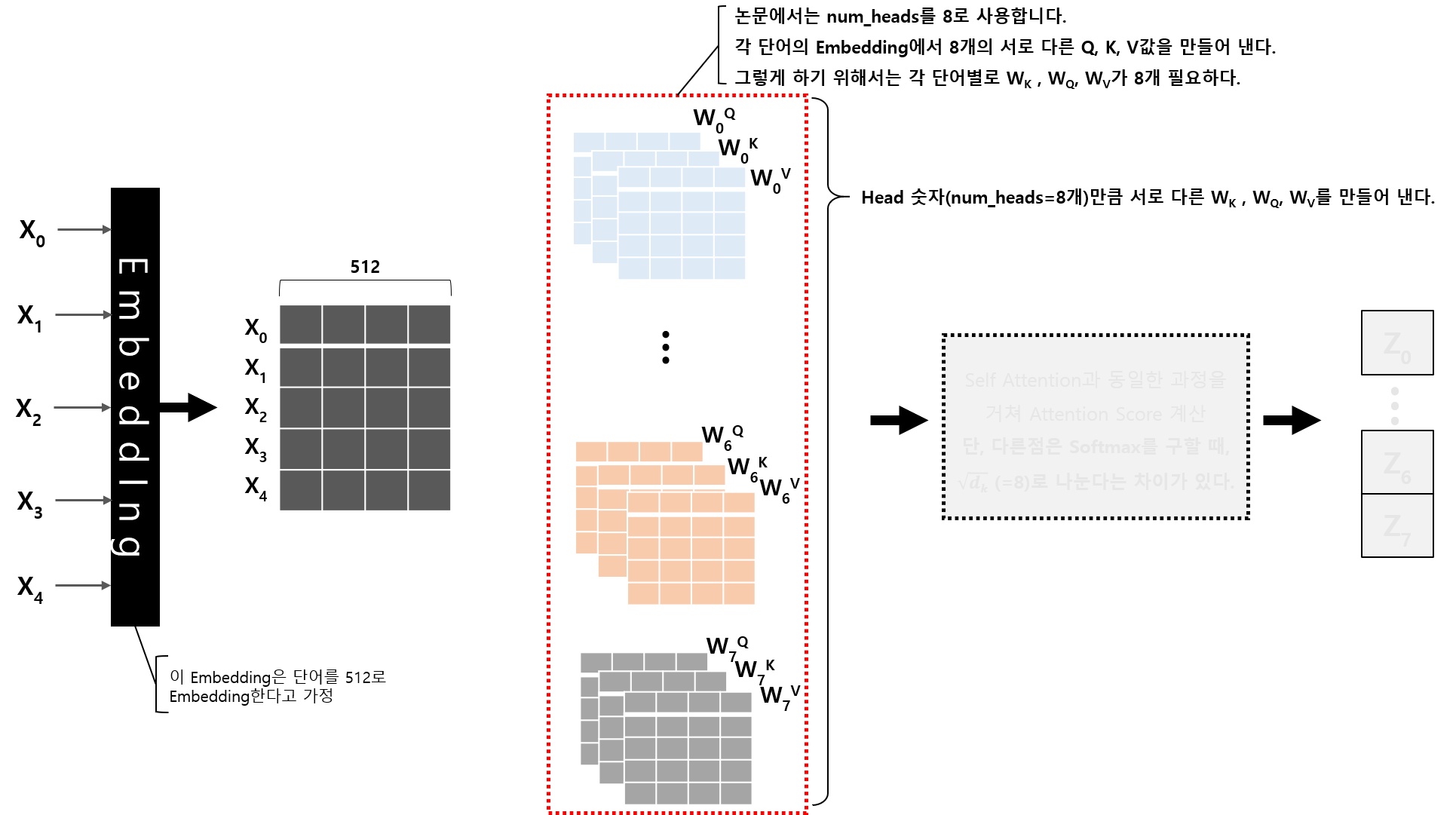
WK, WQ, WV가 하나인 Self Attention에서는 최종 결과가 하나의 Vector로 나오지만,
WK, WQ, WV가 Head 수만큼 있는 Multi-Head Attention의 경우에는 최종 결과 Vector의 수는 Head 수만큼 나올 것입니다.
각각의 WnK, WnQ, WnV와 Embedding Vector를 곱한 후에는 Self Attention과 동일한 계산 방식으로 진행합니다.
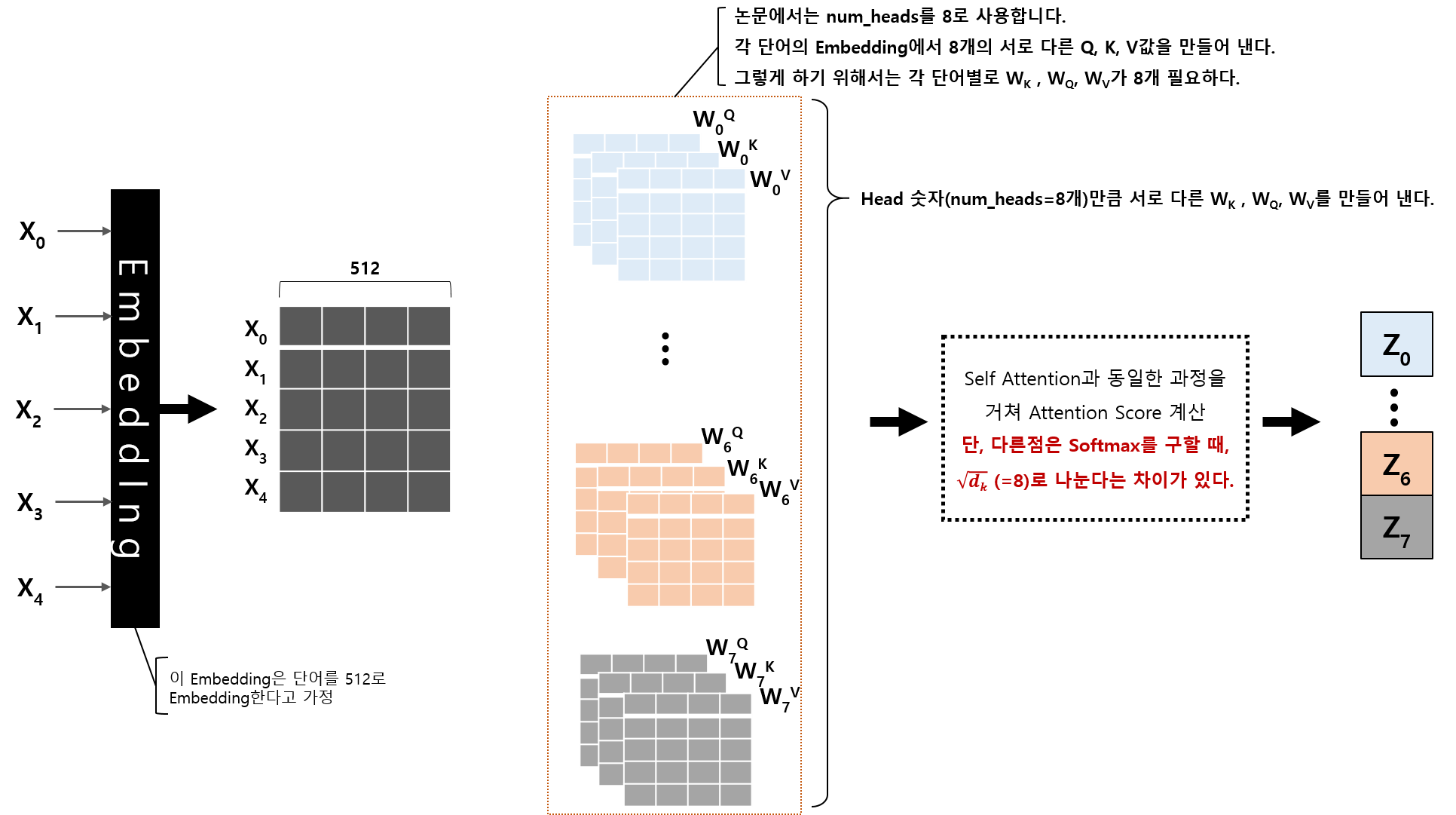
다만, 차이가 있다면 Softmax 값을 계산할 때, k의 Dimension의 제곱근으로 나누어 준다는 점입니다.
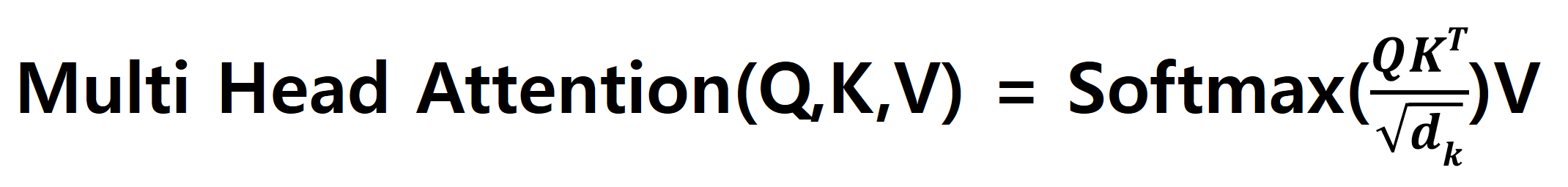
Softmax 결과와 Vn 값을 곱해서 Z0~Zn ( n : Number of Head, 8 )을 구합니다.
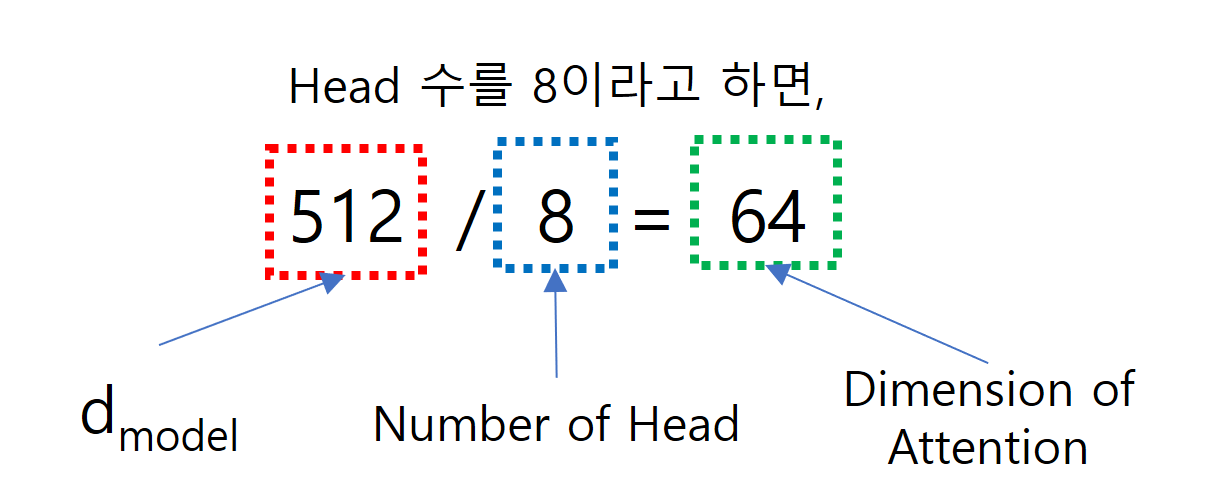
각각의 Zn의 Dimension은 (입력 단어 수 x Dimension of Attention)이 되는데, Dimension of Attention은
dmodel / Number of Head로 구할 수 있고, dmodel은 Embedding의 출력의 크기를 말하며, 여기서는 512입니다.
Dimension of Attention은 512 / 8 = 64가 되고, Zn의 Dimension은 (5 x 64)가 됩니다.
여기까지는 Self Attention을 여러 번 한 것과 동일한 순서입니다.
이 계산을 Number of Head 만큼 반복하기 때문에, Z0 ~ Z7까지 8개의 출력이 나옵니다.
Multi Head Attention에서는 추가적으로 몇 개의 과정이 더 있습니다.
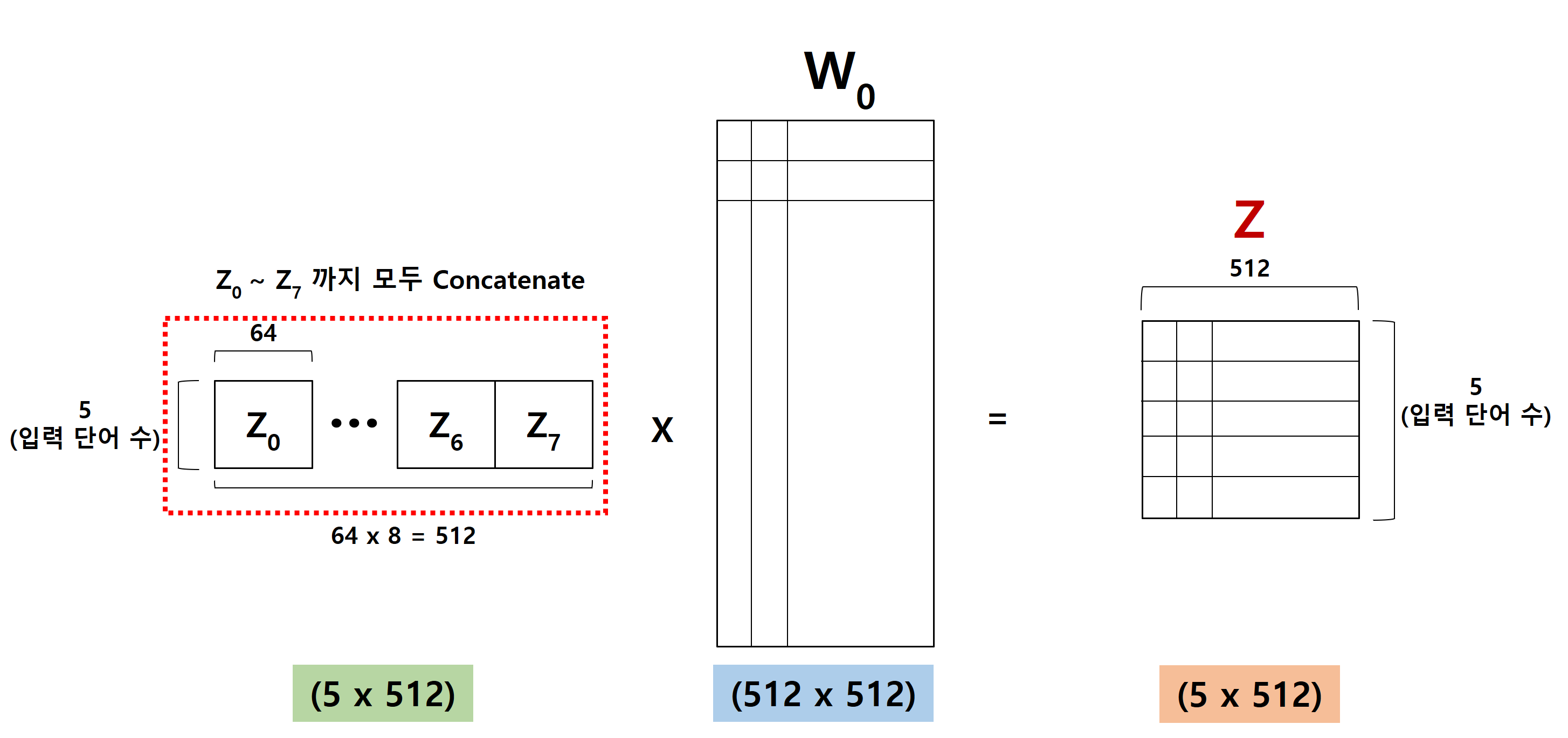
위 그림에서 보듯이, Z0~Z7까지 Concatenate 합니다.
그러면, 위와 같이 (5 x 512) 크기의 하나의 Vector가 생깁니다.
여기에 W0라는 행렬을 곱해서 최종 결과를 얻습니다.
여기까지의 과정이 Multi Head Attention 입력에서부터 최종 출력을 얻는 과정입니다.
원래 Embedding의 출력이 (5 x 512)인데, 출력의 Dimension도 동일하다는 것을 알 수 있습니다.
이와 같이 설계한 이유는 Encoder / Decoder에서 동일한 Block을 6개씩 쌓는 구조를 가지고 있는데
입/출력 Dimension이 동일해야 Block을 쌓는 구조를 만들 수 있기 때문입니다.
3. Add & Norm
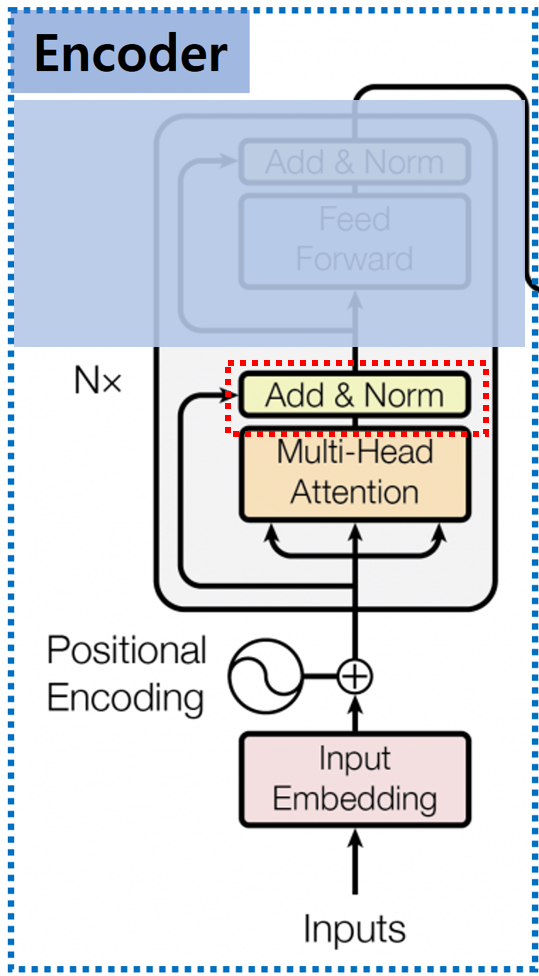
Multi-Head Attention Layer를 거친 출력값은 Add & Normalizaton Layer의 입력으로 들어가게 됩니다.
3.0. Add Layer
Add Layer의 입력은 Multi-Head Attention Layer를 거친 출력값 Z와 Multi-Head Layer 입력값, Positional Encoding을 거치 값을 원소별로 더합니다.
일종의 Residual Connection의 개념이며, Multi-Head Attention의 입력 Dimension과 출력 Dimension이 같기 때문에 원소별 Add가 가능합니다.
3.1. Layer Normalization
Neural Network에는 과적합을 피하기 위해서 Batch Normalization / Layer Normalization, 이렇게 2가지 방식의 Normalization 방식을 사용합니다.
그중에서 이 단계에서는 Layer Normalization 방식을 적용합니다.
입력의 각 원소들의 평균과 편차로 표준화하는 과정입니다.
4. Feed Forward
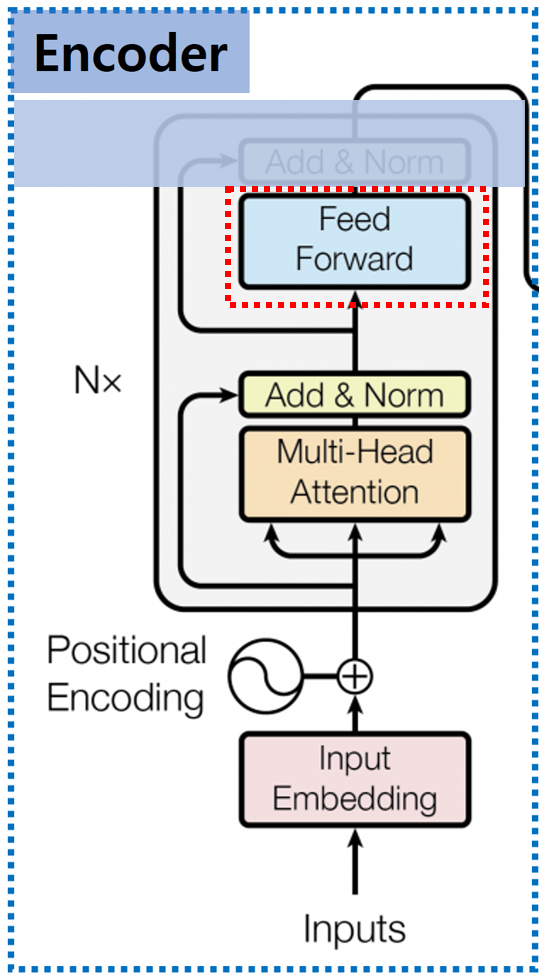
Add & Norm을 거친 값들은 Feed Forward Layer로 들어오게 됩니다.
이 Layer는 ‘Position-Wise Feed Forward’라고 불리며, 여기서 Position의 의미는 각 Token, 입력값을 의미합니다.
즉, 각 단어별로 서로 다른 Fully Connected Layer(Dense Layer)를 적용한다는 의미입니다.
2개의 Fully Connected Layer로 구성되며, 첫 번째 Fully Connected Layer의 Activation Function은 ReLU를 사용하고 두 번째 Fully Connected Layer는 Activation Function을 사용하지 않습니다.
수식으로 나타나면 다음과 같습니다.
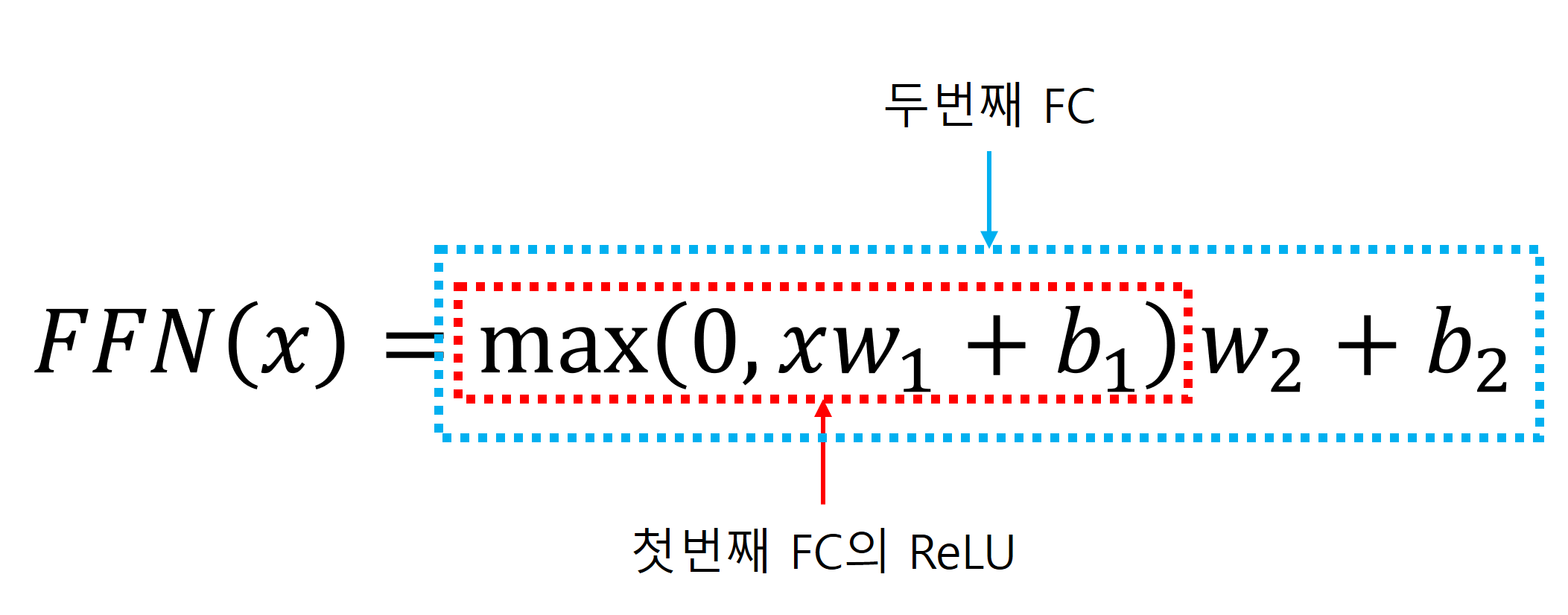
ReLU와 같은 비선형 Activation Function을 통과시킴으로써 Model의 비선형 관계 학습 능력과 일반화 능력의 향상이 목적이라고 생각합니다.
5. Add & Norm
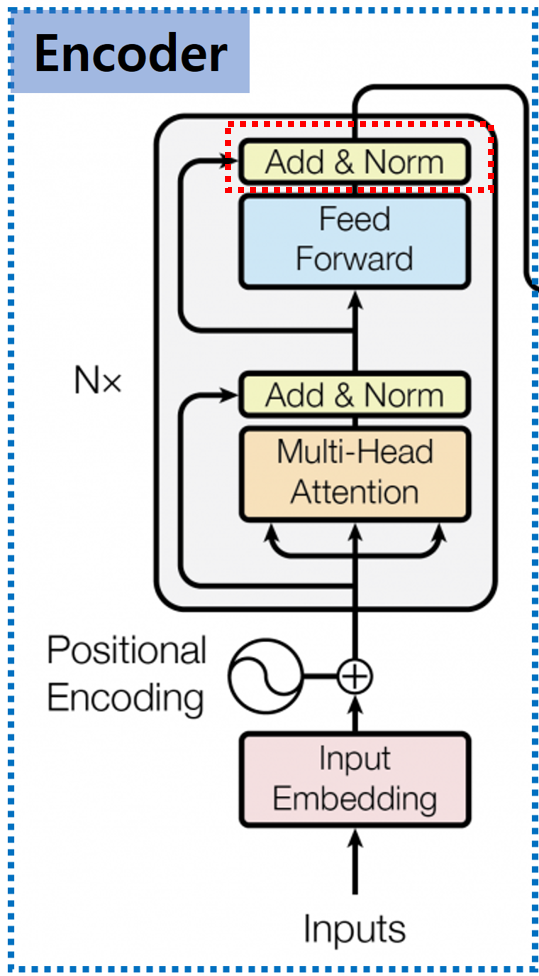
Feed Forward 거치 값들은 다시 한번 Add & Norm Layer를 거칩니다. 여기서 Add & Norm Layer는 이전에 설명한 Add & Norm Layer와 동일합니다.
6. 반복
Transformer의 Encoder는 Multi-Head Attention 구조를 총 Nx 번 반복하는데 논문에서는 6번 반복하는 구조를 제안했습니다.
이처럼 Layer를 Stack 할 수 있는 이유는 Input / Output Dimension이 동일하기 때문입니다.
이번 Post에서는 Transformer의 Encoder 구조에 대해서 자세히 다뤄보았습니다.
다음이 Transformer의 마지막 Post인 Decoder가 될 것 같네요.
감사합니다.