Transformer #1 - Attention Mechanism
0. Background
Attention Mechanism이 나오기 전에는 Seq2Seq Model이 주로 사용되었습니다.
Seq2Seq Model은 당시에는 훌륭한 Idea였지만, 치명적인 문제점을 가지고 있었습니다.
그 어떤 입력값이 들어오더라도 최종적으로 출력은 고정된 길이의 Vector(Hidden State)가 나온다는 것입니다.
입력 문장이 짧으면 별문제가 안되겠지만, 입력 문장이 길어질수록 그 안에 담긴 내용들, 특히 앞쪽의 단어들은 거의 제대로 표현할 수 없다는 문제가 있었습니다.
Attention Mechanism은 이 문제를 개선하기 위해서, Seq2Seq 구조의 각 RNN Cell들의 출력(Hidden State)도 Decoder의 입력으로 사용하자는 Idea에서 출발합니다.
이렇게 하면, 문장이 길어져도 앞쪽의 Data들도 제대로 Decoder의 입력으로 사용할 수 있다는 것입니다.
짧게 이야기했지만, Attention Mechanism에 대해서 잘 설명해 주신 내용들이 너무 많기 때문에 여기에서 줄이고,
저는 실제로 어떻게 Attention 값들이 계산되는지에 좀 더 집중해 보도록 하겠습니다.
1. Overall Structure
아래 그림은 Attention Mechanism의 Encoder / Decoder를 포함한 전체 구조를 나타낸 그림입니다.
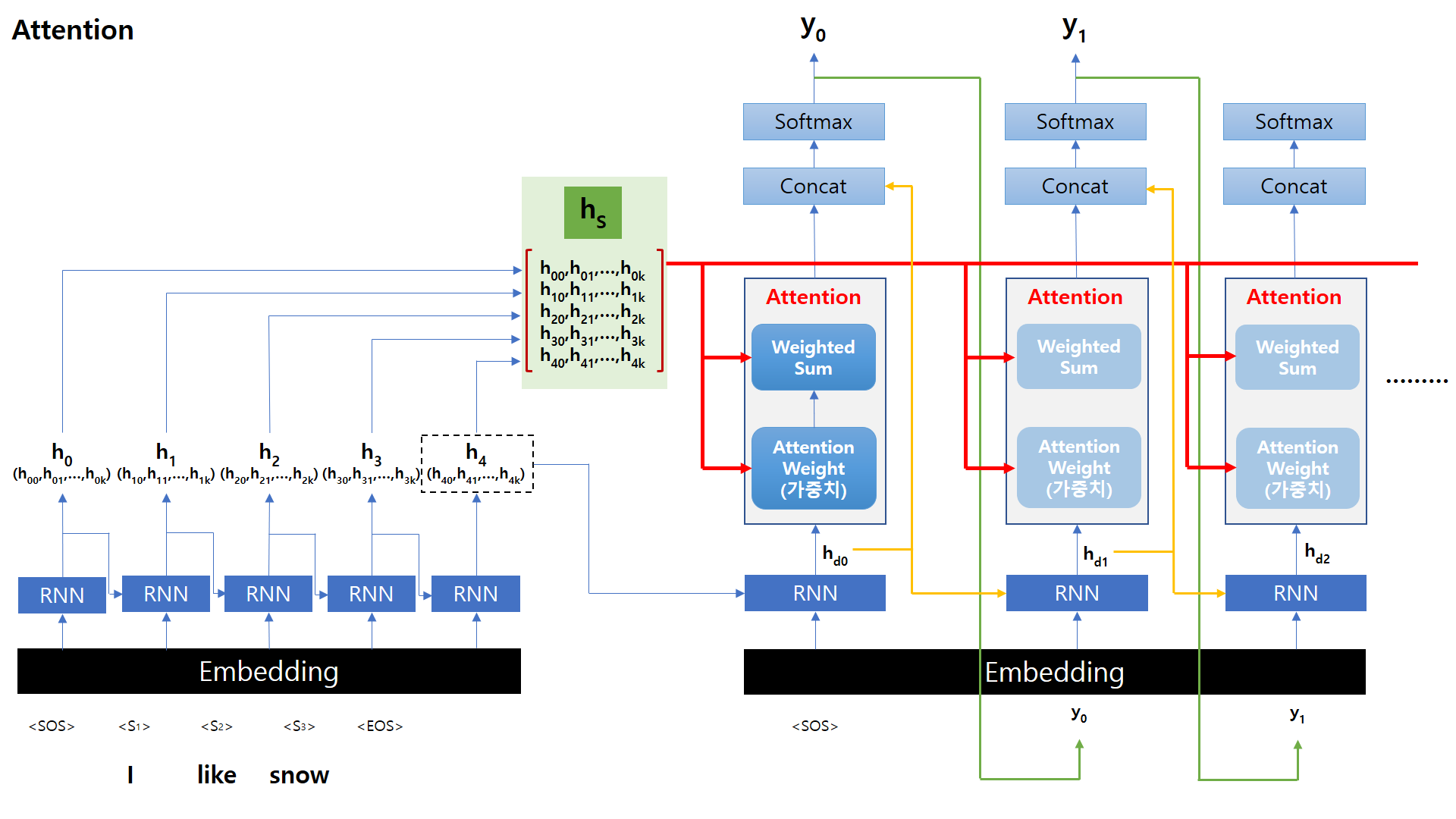
Encoder의 입력부터 Attention 값을 어떻게 Decoder에서 사용하는지에 대해서 하나씩 알아보도록 하겠습니다.
2. Encoder
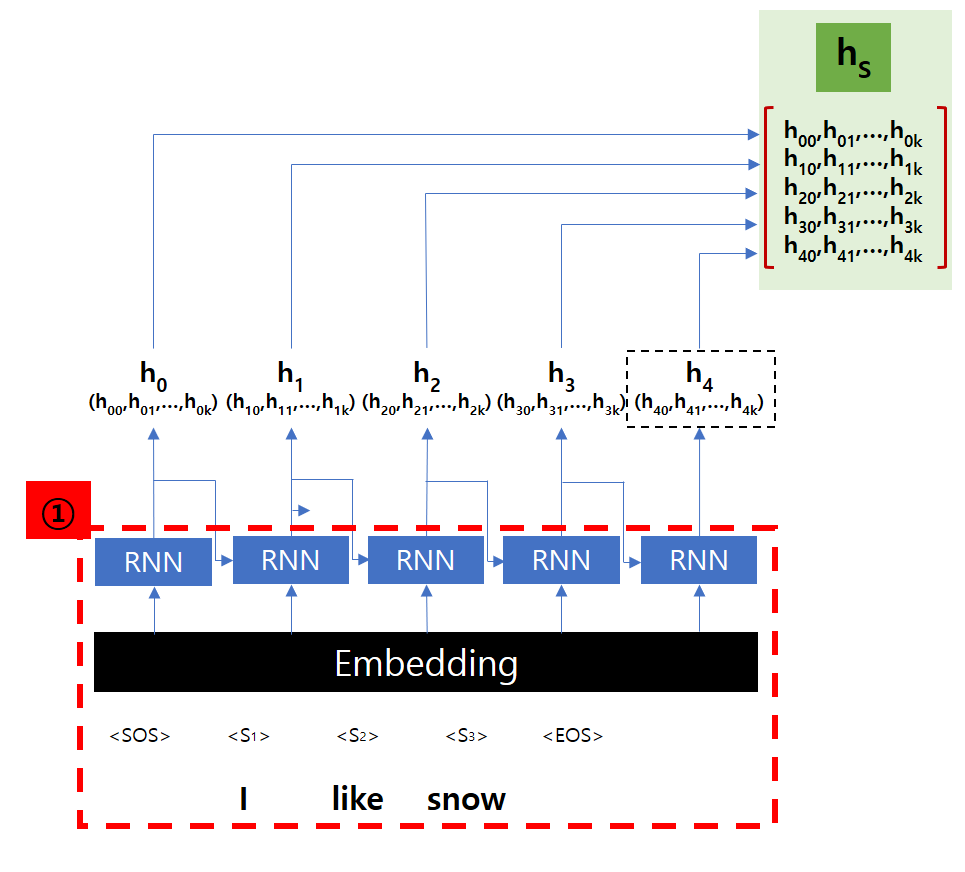
입력으로 “I like snow”라는 문장을 사용해 보도록 하겠습니다. 우선 Tokenizer를 거치면서
이후에 Embedding Layer를 거치면서 각 Token은 Vector 형태로 변환됩니다.
여담으로, Attention을 사용하는 구조에서는 이 Embedding Layer가 아주 중요한데,
Attention 값을 계산하기 위해서 단어 간의 유사도를 측정해야 하는데, 이 계산을 Embedding Layer의 출력값을 기반으로 하기 때문입니다.
Embedding Layer의 출력 Vector 크기는 Embedding Layer의 종류에 따라 달라지겠지요.
Embedding Layer의 출력은 RNN Cell의 입력으로 들어갑니다.
RNN or LSTM에 관한 내용은 아래 글을 참조해 주세요.
Token을 받은 RNN Cell은 Hidden State H를 출력합니다. Hidden State 크기 k는 RNN Cell의 설계에 따라 달라집니다.
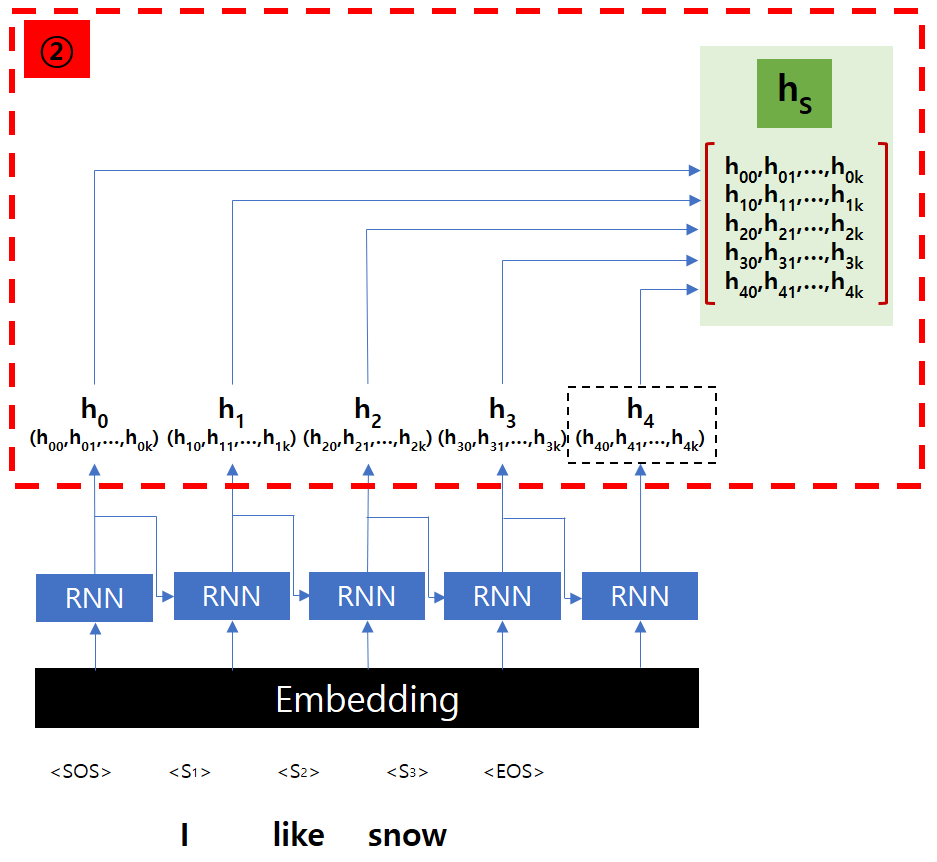
Seq2Seq 구조에서는 이 Hidden State hk 값을 다음 Cell의 입력으로만 사용하겠지만, Attention 구조에서는 이 값들을 Decoder에서 사용하기 위해서 하나로 모읍니다.(hs)
여기서 한 가지 알아두면 좋은 것은 hn은 h0~hn-1까지의 정보를 모두 포함하고 있다는 점입니다.
당연하겠지만, 이전의 Hidden State가 모두 누적되어 현재의 RNN Cell의 입력으로 들어오기 때문입니다.
Encoder에서는 각 RNN Cell의 Hidden State를 모으는 것이 가장 큰 역할입니다.
3. Decoder
Decoder에서 Attention을 어떻게 사용하는지 알아보겠습니다.
Decoder의 변경사항은 RNN Cell 위에 Attention Layer가 추가되었다는 점입니다.
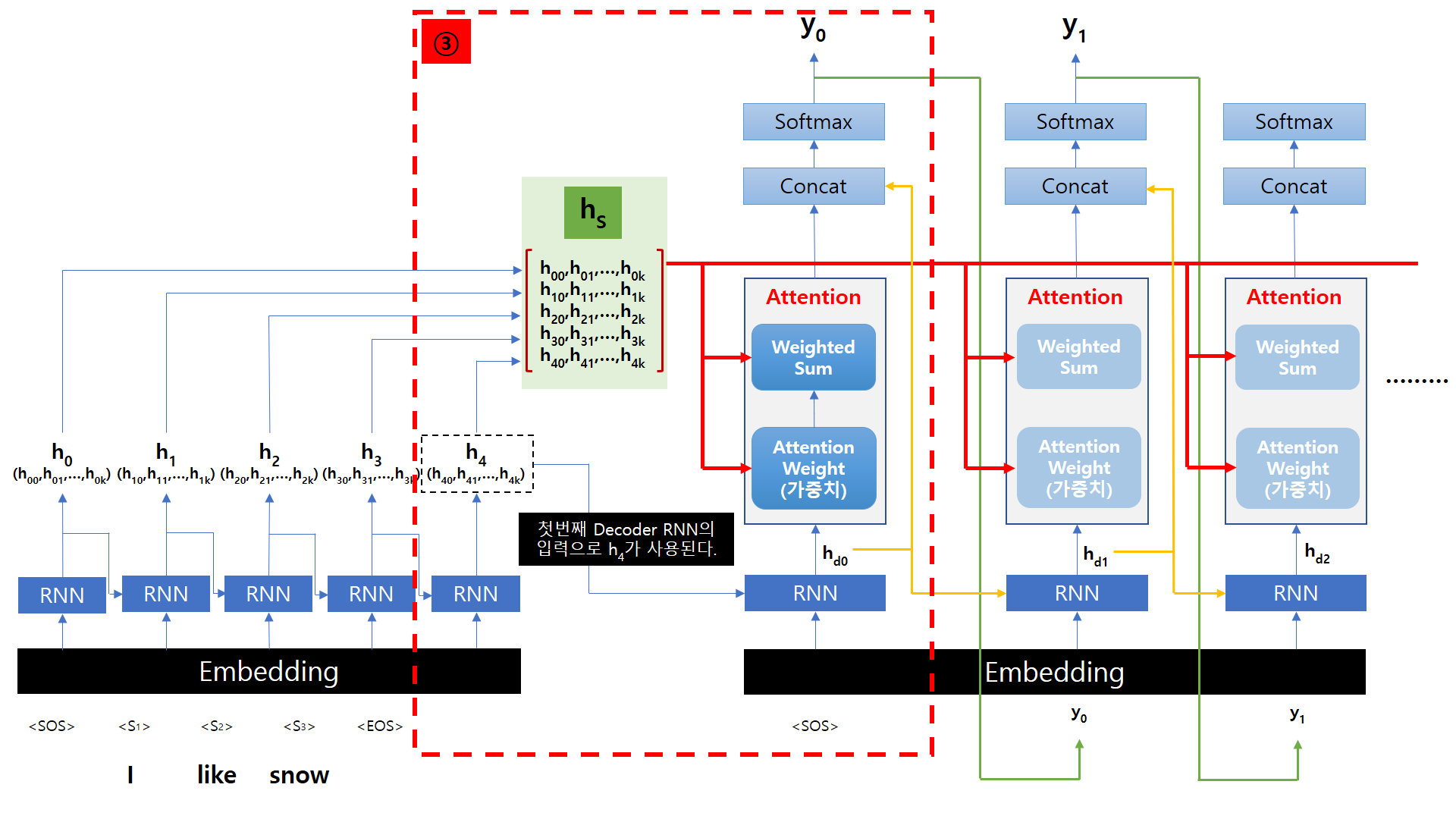
Attention Layer에서는 Attention Weight와 Weighted Sum을 계산해서 출력하고, 각 단계에서 모두 Encoder에서 넘어온 hs 값을 사용하게 됩니다.
Decoder 첫 번째 RNN의 입력은 Encoder와 동일하게 Tokenizer를 거쳐서 Embedding Layer를 지난 Vector 값과
Encoder 마지막 Hidden State인 h4 값을 입력을 받습니다.
이 2개의 값을 받은 RNN Cell은 hd0라는 값을 출력으로 내보냅니다.
3.0. Attention Weight
Attention Weight는 hd0 값과 Encoder의 출력값, hs 값과의 내적(Dot Product or Inner Product) 값을 이용해서 구합니다.
우선, 내적이라는 값이 가지는 의미부터 알아야 할 것 같습니다.
Vector의 내적은 수식으로 아래와 같고, 의미하는 것은 한마디로 두 Vector가 얼마나 비슷한가를 나타내는 값입니다.
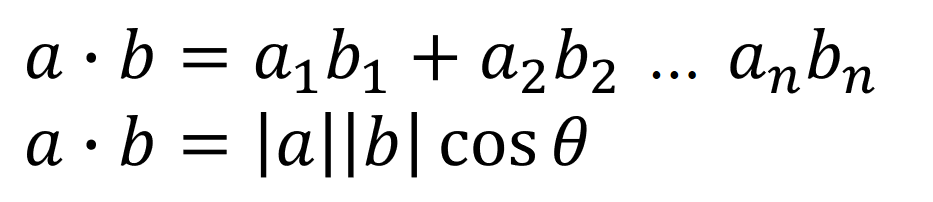
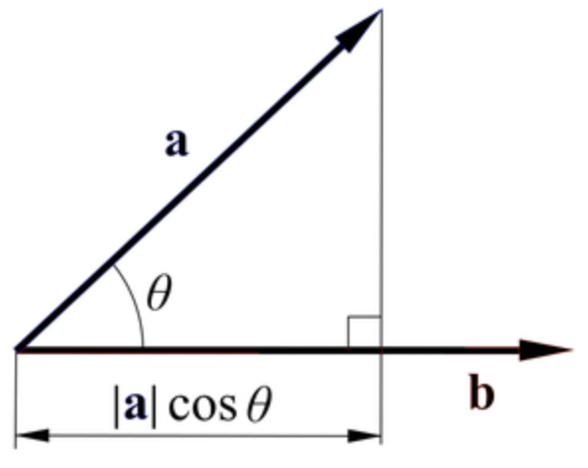
Encoder의 출력값 hs 값과의 내적을 구한다는 의미는 현재 Decoder에서 나온 단어 Embedding Vector가 입력의 어떤 단어와 가장 연관이 높은지 확인해서 주의(Attention)를 기울이겠다는 의미입니다.
이것이 가능하려면 Embedding Layer가 연관성 있는 단어를 얼마나 비슷하게 Embedding 해주느냐가 관건이 되는 것입니다.

위 그림과 같이 먼저 Encoder의 출력값 hs 값과 hd0와 각각 내적을 구합니다. 내적은 Scalar 값이 기 때문에
결과는 Encoder 입력 단어 수만큼의 Scalar 값을 가진 Vector로 나옵니다. 이 값을 Attention Score라고 부릅니다.
내적은 음수가 나올 수도 있기 때문에 확률 값으로 변환하기 위해서 Softmax를 취합니다.
이 값이 Attention Weight가 되고, 이 값을 이용해서 Weighted Sum을 구합니다.
3.1. Weighted Sum
아래 그림과 같이 Encoder의 출력값 hs 값에 방금 구한 Attention Weight를 개별적으로 곱합니다.
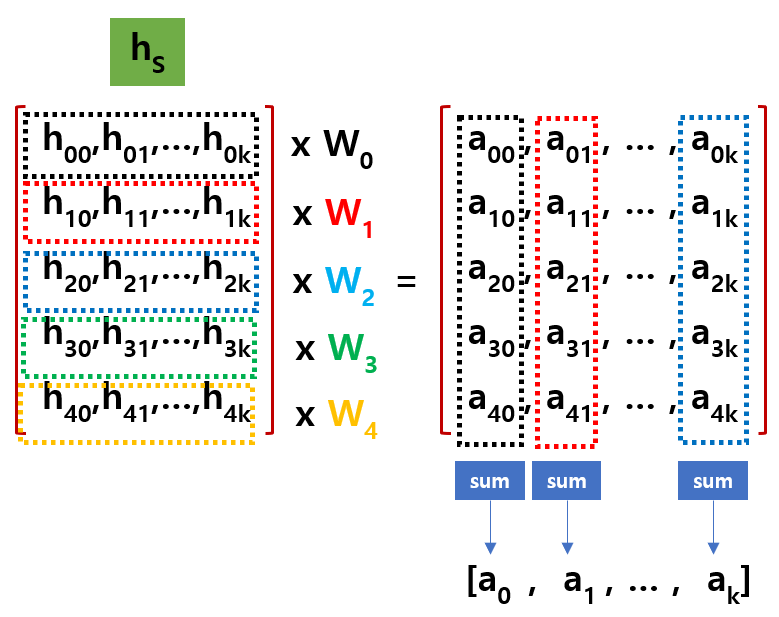
그 결과를 Column 방향으로 Sum 한 값이 Weighted Sum이 됩니다.
Weighted Sum이 Attention Layer의 출력값이 되고, Weighted Sum와 hd0를 Concat 해서 Softmax에 넣으면 최종적으로 출력 단어를 결정합니다.
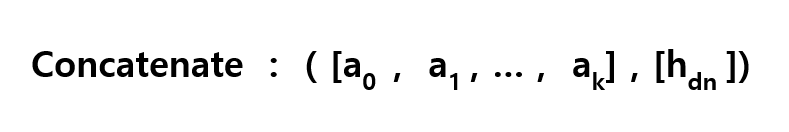
4. Example
실제 값으로 계산을 한 번 해 보도록 하겠습니다.
아래 그림과 같이 임의로 Encoder의 출력값 hs 값과 Decoder 첫 번째 RNN Cell의 출력값 hd0가 있다고 가정해 보겠습니다.

앞서 설명한 방법대로 hs와 hd0를 각각 내적을 구한 값이 Attention Socre가 되겠습니다.
Attention Socre를 Softmax 값을 취한 것이 가중치 W입니다.

가중치 W를 Encoder의 출력값 hs 원소에 개별적으로 곱한 후, 아래 그림과 같이 합을 구하면 이 값이 Weighted Sum이 됩니다.

Weighted Sum과 hd0 값을 Concatenate 한 값을 Softmax에 넣어서 최종적으로 값을 뽑아내게 되는 것입니다.

이번 Post에서는 Attention Mechnism에 대해서 알아보았습니다.
다음에는 Transformer에 관련 내용을 다루도록 하겠습니다.