Kaggle Competition - Rainforest Connection Species Audio Detection #1
Kaggle Competition - Rainforest Connection Species Audio Detection - Revision #01
0. Intro
-
이번 Post에서는 3달 전에 Kaggle에 올라온 Competition중 하나인, ‘Rainforest Connection Species Audio Detection’ Competition에 도전해 보도록 하겠습니다.
-
이 Competition의 Link는 여기를 참조하세요.
-
간단하게 설명하자면, 1분 길이의 Sound File이 제공되고 각 File에 대한 정보도 제공해 줍니다.
File 정보에는 1분의 Sound File에서 어느 위치부터 어느 위치까지의 소리가 어떤 종류 동물의 소리인지 표시되어 있습니다.
-
총 24가지 종류의 새와 개구리 소리가 구분되어 있으며, Sound Data Format은 FLAC File과 TFRecord File, 2가지 Format으로 제공됩니다.
-
앞으로 몇 번의 Post에 걸쳐 다양한 방법으로 이 Competition에 도전해 보도록 하겠습니다.
1. Look Through Data
- 우선 제공된 Dataset을 살펴보기로 하겠습니다.

-
전체 Data Size가 57.23 GB이고, 3개의 Folder와 3개의 File들로 구성되어 있네요.
- Test Folder에는 최종적으로 우리가 Predict 해야할 Sound File들이 들어있습니다.
- 전부 몇개나 있는지 볼까요
import librosa
import numpy as np
import csv
from tqdm.notebook import tqdm
import pickle
from skimage.transform import resize
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
import librosa.display
import colorednoise as cn
from sklearn.model_selection import StratifiedKFold
from tensorflow.keras.models import Sequential
from tensorflow.keras.applications import ResNet50
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Dropout,GlobalAveragePooling2D,BatchNormalization,Conv2D,MaxPooling2D
from tensorflow.keras import optimizers
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
import glob
from sklearn.model_selection import train_test_split
import lightgbm as lgb
SR = 48000
TestFileNames = glob.glob( '../rfcx-species-audio-detection/test/*.flac' )
print( len( TestFileNames ) )
print( TestFileNames[0] )
1992
../rfcx-species-audio-detection/test\000316da7.flac
-
총 1992개의 Sound File이 있고, 우리 Model로 이 소리가 무슨 새 혹은 개구리의 소리인지 맞추는 것이 이 Competition의 목표입니다.
-
train Folder와 tfrecords Folder에는 모두 Train용 Data가 들어가 있는데, train Folder에는 FLAC Format의 Data File이 있고, tfrecords folder에는 TFRecord Format의 Data File이 들어가 있습니다.
-
익숙한 Format의 File들을 이용하면 됩니다.
-
저는 FLAC Format을 이용하도록 하겠습니다.
-
그리고 Train에 있어서 가장 중요한 정보를 가지고 있는 ‘train_tp.csv’ File에 대해서 알아보도록 하겠습니다.
with open('../rfcx-species-audio-detection/train_tp.csv') as f:
reader = csv.reader(f)
data = list(reader)
print(len(data))
1217
train_tp = pd.read_csv("../rfcx-species-audio-detection/train_tp.csv")
train_tp.head()
| recording_id | species_id | songtype_id | t_min | f_min | t_max | f_max | |
|---|---|---|---|---|---|---|---|
| 0 | 003bec244 | 14 | 1 | 44.5440 | 2531.250 | 45.1307 | 5531.25 |
| 1 | 006ab765f | 23 | 1 | 39.9615 | 7235.160 | 46.0452 | 11283.40 |
| 2 | 007f87ba2 | 12 | 1 | 39.1360 | 562.500 | 42.2720 | 3281.25 |
| 3 | 0099c367b | 17 | 4 | 51.4206 | 1464.260 | 55.1996 | 4565.04 |
| 4 | 009b760e6 | 10 | 1 | 50.0854 | 947.461 | 52.5293 | 10852.70 |
-
이 File에는 제목 한 줄을 제외한 총 1216개의 정보가 포함되어 있으며, 각 Row에는 위와 같이 6개의 Column으로 이루어진 값들이 포함되어 있습니다.
-
‘recording_id’는 FLAC File이름이며, 고유 값입니다.
‘species_id’이 바로 Target값입니다.
‘t_min’과 ‘t_max’는 해당 FLAC File에서 ‘species_id’가 소리를 내는 구간을 나타내며,단위는 sec입니다.
-
Train File 하나를 읽어볼까요?
-
Python에서 Audio File을 다룰때는 Librosa라는 Package가 많이 쓰이고 있습니다.
저도 이 Package를 이용하도록 하겠습니다.
wav , sr = librosa.load("../rfcx-species-audio-detection/train/"+data[2][0]+".flac" , sr=None)
import IPython.display as ipd
ipd.Audio(wav, rate=sr)
-
Train FLAC File들의 길이는 모두 1분으로 동일합니다. 다행이네요.
-
t_min과 t_max를 읽어서 우리가 구분해야할 소리가 나오는 부분만 살펴보도록 하겠습니다.
t_min = float(train_tp.iloc[1]['t_min']) * sr
t_max = float(train_tp.iloc[1]['t_max']) * sr
slice = wav[int(t_min) : int(t_max)]
ipd.Audio(slice, rate=sr)
-
Feature로 사용할 때는 각 FLAC File마다 해당 부분만 떼어서 사용해야 할 것 같습니다.
-
t_max와 t_min의 차이, 즉, 나중에 Train에 사용할 구간들의 길이에 대해서 확인해 보겠습니다.
-
이것을 하는 이유는 나중에 얼마만큼씩 잘라서 사용해야 좋을지 확인하기 위해서입니다.
train_tp['dur'] = train_tp['t_max'] - train_tp['t_min']
train_tp['dur'].describe()
count 1216.000000
mean 2.537119
std 1.903589
min 0.272000
25% 1.093300
50% 1.856000
75% 3.344000
max 7.923900
Name: dur, dtype: float64
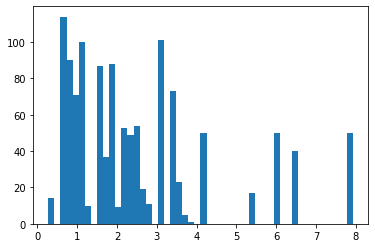
plt.hist( train_tp['dur'] , bins = 50)
(array([ 14., 0., 114., 90., 71., 100., 10., 0., 87., 37., 88.,
9., 53., 49., 54., 19., 11., 0., 101., 0., 73., 23.,
5., 1., 0., 50., 0., 0., 0., 0., 0., 0., 0.,
17., 0., 0., 0., 50., 0., 0., 40., 0., 0., 0.,
0., 0., 0., 0., 0., 50.]),
array([0.272 , 0.425038, 0.578076, 0.731114, 0.884152, 1.03719 ,
1.190228, 1.343266, 1.496304, 1.649342, 1.80238 , 1.955418,
2.108456, 2.261494, 2.414532, 2.56757 , 2.720608, 2.873646,
3.026684, 3.179722, 3.33276 , 3.485798, 3.638836, 3.791874,
3.944912, 4.09795 , 4.250988, 4.404026, 4.557064, 4.710102,
4.86314 , 5.016178, 5.169216, 5.322254, 5.475292, 5.62833 ,
5.781368, 5.934406, 6.087444, 6.240482, 6.39352 , 6.546558,
6.699596, 6.852634, 7.005672, 7.15871 , 7.311748, 7.464786,
7.617824, 7.770862, 7.9239 ]),
<a list of 50 Patch objects>)
-
대부분이 4초보다 짧고, 좀 길면 8초까지 있네요.
-
Train Data 전체를 Cover하려면 6초 정도가 가장 적당하겠네요.
2. Features of Sound & Audio Data
-
자, 이제 Data도 대충 살펴보았고, 이제 어떻게 Train할 건지 생각해 봐야 할 것 같습니다.
-
Feature를 어떻게 Extracr할 것인가가 가장 중요할 것 같은데요, Sound Data는 대부분 MFCC와 MEL Spectogram을 Feature로 많이 사용하는 것 같더라구요.
-
MFCC를 포함한 다양한 Sound Data의 Feature Extaction에 관련된 내용은 아래 Blog를 참조해 주시기 바랍니다.
-
아래 Blog도 꽤 좋은 내용을 담고 있습니다.
3. MFCC & MEL Spectogram
-
MFCC와 MEL Spec.을 이제 구해보도록 하겠습니다.
-
이미 MFCC와 MEL Spec.을 구하기 위한 훌륭한 Package가 있습니다. 앞에서도 잠깐 언급했지만, Librosa라는 Package가 매우 훌륭합니다.
-
자세한 Doc.은 아래 Link를 참조해 주시기 바랍니다.
Librosa
- Feature extraction 항목에 보시면 Sound로 부터 다양한 Feature를 Extract할 수 있는 다양한 함수들이 준비되어 있습니다.
- 저는 여기서 MEL Spec.(melspectrogram)과 MFCC(mfcc)를 사용하도록 하겠습니다.
4. Feature Extraction
-
Librosa의 함수를 이용하여 Feature Extraction을 해 보겠습니다.
-
전체적인 흐름은 아래와 같이, MEL Spec.과 MFCC의 평균값으로 각 Train Data의 Feature를 만들 것입니다.

- 우선 전체 Data에서 각 영역의 최대 / 최소 Frequency를 알아보도록 하죠. 이 값을 알아야 이후에 MEL Spec.과 MFCC를 구할 수 있습니다.
fmin = 24000
fmax = 0
for i in range(1, len(data)):
if fmin > float(data[i][4]):
fmin = float(data[i][4])
if fmax < float(data[i][6]):
fmax = float(data[i][6])
# Margin을 조금 줍니다.
fmin = int(fmin * 0.9)
fmax = int(fmax * 1.1)
print('Minimum frequency: ' + str(fmin) + ', maximum frequency: ' + str(fmax))
Minimum frequency: 84, maximum frequency: 15056
fft = 2048
hop = 512
WINDOWS_SIZE = 6
sr = 48000
length = WINDOWS_SIZE * sr
NUM_CLASS = 24
- 이제, MFCC와 MEL Spec.을 Extract해서 File로 저장해 놓도록 하겠습니다.
TRAIN = pd.DataFrame()
print('Starting Feature Extracting...')
for i in tqdm( range(1, len(data))):
wav, sr = librosa.load('../rfcx-species-audio-detection/train/' + data[i][0] + '.flac', sr=None)
t_min = float(data[i][3]) * sr
t_max = float(data[i][5]) * sr
# 시작과 끝의 중점을 중심으로 전체 길이가 6초로 일정하게 만든다.
center = np.round((t_min + t_max) / 2)
beginning = center - length / 2
if beginning < 0:
beginning = 0
ending = beginning + length
if ending > len(wav):
ending = len(wav)
beginning = ending - length
slice = wav[int(beginning):int(ending)]
# MEL Spec. Feature
mel_spec = librosa.feature.melspectrogram(slice, n_fft=fft, hop_length=hop, sr=sr, fmin=fmin, fmax=fmax, power=1.5)
melscaled = np.mean(mel_spec.T,axis=0)
melscaled = list(melscaled.T)
# MFCC Feature
mfcc = librosa.feature.mfcc(slice , sr=sr , n_mfcc = 40)
mfccsscaled = np.mean(mfcc.T,axis=0)
mfccsscaled = list(mfccsscaled.T)
tmp = melscaled + mfccsscaled
tmp = pd.DataFrame(tmp).T
TRAIN = pd.concat([TRAIN,tmp])
Starting Feature Extracting...
- 이제 Feature에 맞는 Label도 따로 뽑아내겠습니다.
- 그래야 나중에 Train할 때 사용할 수 있으니깐요.
Label = []
for i in tqdm( range(1, len(data))):
Label.append( data[i][1] )
Label
['14',
'23',
'12',
'17',
'10',
'8',
'0',
'18',
'15',
'1',
...]
- 원하는 대로 잘 만들어 졌는지 한 번 볼까요?
TRAIN.head()
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 158 | 159 | 160 | 161 | 162 | 163 | 164 | 165 | 166 | 167 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.034562 | 0.011758 | 0.008450 | 0.023155 | 0.021589 | 0.005748 | 0.003271 | 0.003472 | 0.002780 | 0.002468 | ... | -0.916265 | -1.098225 | -2.676772 | -1.896342 | 0.270768 | -2.226133 | -0.259369 | 0.513921 | 0.795100 | -0.277169 |
| 0 | 0.326220 | 0.302937 | 0.145184 | 0.073245 | 0.043459 | 0.021372 | 0.013206 | 0.017474 | 0.020128 | 0.018785 | ... | -3.458029 | -2.858149 | -3.494677 | -1.924518 | -2.351852 | -1.965279 | -1.336849 | -2.033947 | -0.016453 | -0.177412 |
| 0 | 0.165520 | 0.198534 | 0.202551 | 0.172053 | 0.103592 | 0.057968 | 0.034055 | 0.024015 | 0.024043 | 0.022022 | ... | -7.113028 | -1.479504 | 2.198930 | 2.616116 | 3.768363 | -2.565371 | -8.847826 | -1.028994 | 7.390729 | -0.466450 |
| 0 | 0.036173 | 0.041161 | 0.011874 | 0.007293 | 0.007921 | 0.008111 | 0.005517 | 0.003888 | 0.003161 | 0.003231 | ... | 0.038490 | -4.215221 | 0.132852 | 0.432737 | -1.416698 | -0.349015 | -2.514560 | -0.969835 | 2.091542 | -2.319309 |
| 0 | 0.027391 | 0.025106 | 0.021964 | 0.019909 | 0.019068 | 0.016489 | 0.012955 | 0.012114 | 0.012478 | 0.013255 | ... | -1.107634 | 0.938184 | 1.522288 | -0.468707 | -0.549454 | -1.000291 | 2.265465 | 0.910263 | -0.981540 | 0.002835 |
5 rows × 168 columns
TRAIN.shape
(1216, 168)
TRAIN.to_csv("MFCC_MEL_Spec_Mean_Train_csv" , index=False)
- 이제 Train Data와 이에 해당하는 Label 모두 준비되었으니, LightGBM를 준비하도록 하겠습니다.
5. Train
-
저는 LightGBM을 이용하도록 하겠습니다.
-
제가 LightGBM을 선호하는 이유는 Tree Base라서 Train Data의 특별한 전처리도 필요없고, 대용량의 Tabular Data 처리에 최적화되어 있기 때문입니다.
-
Train Data와 Validation Data를 6:4의 비율로 나누도록 하겠습니다.
X_train,X_test,y_train,y_test = train_test_split( TRAIN , Label , test_size=0.4 , random_state=27)
- LightGBM에 사용하기 위해 약간의 처리를 합니다.
#Converting the dataset in proper LGB format
LGB_Train_Data = lgb.Dataset(X_train, label=y_train)
# Val
LGB_Test_Data = lgb.Dataset(X_test, label = y_test)
-
가장 중요한 Hyper Parameter Setting을 하도록 하겠습니다.
-
아래 값들은 일단 기본적인 값들로 설정하였고, 나중에 Tunning하면 됩니다.
params={}
params['learning_rate']=0.03
params['num_iterations']=10000
params['boosting_type']='gbdt' #GradientBoostingDecisionTree
params['objective']='multiclass' #Multi-class target feature
params['metric']='multi_logloss' #metric for multi-class
params['num_class']=24 #no.of unique values in the target class not inclusive of the end value
- 자, 이제 모든 준비가 끝났습니다. Train을 시작해 보겠습니다.
#training the model
Model = lgb.train(params ,
LGB_Train_Data ,
10000,
LGB_Test_Data ,
verbose_eval=10,
early_stopping_rounds = 500
) #training the model on 100 epocs
C:\Users\csyi\AppData\Local\Continuum\anaconda3\lib\site-packages\lightgbm\engine.py:148: UserWarning: Found `num_iterations` in params. Will use it instead of argument
warnings.warn("Found `{}` in params. Will use it instead of argument".format(alias))
Training until validation scores don't improve for 500 rounds
[10] valid_0's multi_logloss: 2.73311
[20] valid_0's multi_logloss: 2.50195
[30] valid_0's multi_logloss: 2.34626
[40] valid_0's multi_logloss: 2.23263
[50] valid_0's multi_logloss: 2.15191
[60] valid_0's multi_logloss: 2.08371
[70] valid_0's multi_logloss: 2.03414
[80] valid_0's multi_logloss: 1.99057
[90] valid_0's multi_logloss: 1.95019
[100] valid_0's multi_logloss: 1.91641
[110] valid_0's multi_logloss: 1.88726
[120] valid_0's multi_logloss: 1.86712
[130] valid_0's multi_logloss: 1.85241
[140] valid_0's multi_logloss: 1.84384
[150] valid_0's multi_logloss: 1.83451
[160] valid_0's multi_logloss: 1.82917
[170] valid_0's multi_logloss: 1.82655
[180] valid_0's multi_logloss: 1.82385
[190] valid_0's multi_logloss: 1.82632
[200] valid_0's multi_logloss: 1.8294
[210] valid_0's multi_logloss: 1.83588
[220] valid_0's multi_logloss: 1.84367
[230] valid_0's multi_logloss: 1.84795
[240] valid_0's multi_logloss: 1.85654
[250] valid_0's multi_logloss: 1.8652
[260] valid_0's multi_logloss: 1.87783
[270] valid_0's multi_logloss: 1.89209
[280] valid_0's multi_logloss: 1.90651
[290] valid_0's multi_logloss: 1.91928
[300] valid_0's multi_logloss: 1.92866
[310] valid_0's multi_logloss: 1.94303
[320] valid_0's multi_logloss: 1.95658
[330] valid_0's multi_logloss: 1.97317
[340] valid_0's multi_logloss: 1.98953
[350] valid_0's multi_logloss: 2.0086
[360] valid_0's multi_logloss: 2.02363
[370] valid_0's multi_logloss: 2.04138
[380] valid_0's multi_logloss: 2.05692
[390] valid_0's multi_logloss: 2.07291
[400] valid_0's multi_logloss: 2.09063
[410] valid_0's multi_logloss: 2.10799
[420] valid_0's multi_logloss: 2.12491
[430] valid_0's multi_logloss: 2.14385
[440] valid_0's multi_logloss: 2.16186
[450] valid_0's multi_logloss: 2.17973
[460] valid_0's multi_logloss: 2.19931
[470] valid_0's multi_logloss: 2.21659
[480] valid_0's multi_logloss: 2.23474
[490] valid_0's multi_logloss: 2.25269
[500] valid_0's multi_logloss: 2.2692
[510] valid_0's multi_logloss: 2.28067
[520] valid_0's multi_logloss: 2.29046
[530] valid_0's multi_logloss: 2.30034
[540] valid_0's multi_logloss: 2.30904
[550] valid_0's multi_logloss: 2.31594
[560] valid_0's multi_logloss: 2.32332
[570] valid_0's multi_logloss: 2.32974
[580] valid_0's multi_logloss: 2.33579
[590] valid_0's multi_logloss: 2.34151
[600] valid_0's multi_logloss: 2.34632
[610] valid_0's multi_logloss: 2.35019
[620] valid_0's multi_logloss: 2.35459
[630] valid_0's multi_logloss: 2.35936
[640] valid_0's multi_logloss: 2.36239
[650] valid_0's multi_logloss: 2.36519
[660] valid_0's multi_logloss: 2.36738
[670] valid_0's multi_logloss: 2.36999
Early stopping, best iteration is:
[179] valid_0's multi_logloss: 1.82373
6. Predict
-
학습 완료된 Model이 생겼으니, 이제 마지막으로 주최측에서 제공한 Test File들이 어떤 종류의 소리를 담고 있는지 Predict해서 제출하기만 하면 됩니다.
-
Predict해야 할 File들을 살펴보도록 하겠습니다.
-
‘test’ Folder안에 있고, 총 1992개의 Sound File이 있습니다.
-
좋습니다. 자, 이제 각각 하나씩 전부 Trained Model에 집어넣고 결과를 모아서 제출하면 됩니다.
-
Test File들도 모두 길이가 1분씩입니다.
-
우리가 Train시킨 Model은 6초 길이의 Sound File에서 MFCC & MEL Spec.을 전처리한 Data를 받아서 출력하는 기능을 합니다.
-
즉, Predict를 하려면, Test File에 대해서 동일한 전처리를 거친 Data를 Model의 입력으로 넣어줘야 합니다.
-
조금 귀찮지만, 그렇게 해줘야 합니다.
- Test File들의 위치와 개수를 확인해 봅시다.
TestFileNames = glob.glob( '../rfcx-species-audio-detection/test/*.flac' )
print( len( TestFileNames ) )
print( TestFileNames[0] )
1992
../rfcx-species-audio-detection/test\000316da7.flac
- 좋습니다. 우리가 기대하던 그대로 입니다.
-
Submission File은 24개 각 Class의 확률을 적어주어야 합니다.
-
아래와 같이 Column Name을 구성해 주고, 해당 확률을 적어주면 됩니다.
submission = pd.DataFrame( columns=['s0', 's1', 's2', 's3', 's4', 's5', 's6', 's7', 's8', 's9', 's10',
's11', 's12', 's13', 's14', 's15', 's16', 's17', 's18', 's19', 's20',
's21', 's22', 's23'] )
recording_id = []
for filename in tqdm(TestFileNames):
pred = []
id = filename.replace("../rfcx-species-audio-detection/test\\" , "")
id = id.replace(".flac" , "")
recording_id.append( id )
wav, sr = librosa.load(filename, sr=None)
# 6초 단위로 끊어서 변환후 전처리를 거쳐 Model에 입력시킵니다.
segments = len(wav) / length
segments = int(np.ceil(segments))
for i in range(0, segments):
# Last segment going from the end
if (i + 1) * length > len(wav):
slice = wav[len(wav) - length:len(wav)]
else:
slice = wav[i * length:(i + 1) * length]
mel_spec = librosa.feature.melspectrogram(slice, n_fft=fft, hop_length=hop, sr=sr, fmin=fmin, fmax=fmax, power=1.5)
mel_spec = librosa.feature.melspectrogram(slice, n_fft=fft, hop_length=hop, sr=sr, fmin=fmin, fmax=fmax, power=1.5)
melscaled = np.mean(mel_spec.T,axis=0)
melscaled = list(melscaled.T)
mfcc = librosa.feature.mfcc(slice , sr=sr , n_mfcc = 40)
mfccsscaled = np.mean(mfcc.T,axis=0)
mfccsscaled = list(mfccsscaled.T)
tmp = melscaled + mfccsscaled
tmp = np.array(tmp).reshape(1,-1)
pred.append( Model.predict( tmp ) )
pred = np.array( pred ).reshape(10,24)
pred = list(np.max( pred , axis=0))
a_series = pd.Series(pred, index = submission.columns)
submission = submission.append(a_series, ignore_index=True)
- 완료 되었습니다. 이제 Column 순서 정리하고 File로 저장해서 제출해 보도록 하겠습니다.
submission.head()
| s0 | s1 | s2 | s3 | s4 | s5 | s6 | s7 | s8 | s9 | ... | s14 | s15 | s16 | s17 | s18 | s19 | s20 | s21 | s22 | s23 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.022533 | 0.018128 | 0.024431 | 0.698671 | 0.022352 | 0.121563 | 0.053104 | 0.023634 | 0.018857 | 0.028449 | ... | 0.030755 | 0.027548 | 0.023639 | 0.036652 | 0.182670 | 0.062465 | 0.702695 | 0.026496 | 0.247210 | 0.121671 |
| 1 | 0.007562 | 0.007608 | 0.006683 | 0.017434 | 0.013696 | 0.007921 | 0.007938 | 0.008398 | 0.006666 | 0.010170 | ... | 0.018974 | 0.010512 | 0.967143 | 0.298409 | 0.012959 | 0.007101 | 0.025084 | 0.006906 | 0.043390 | 0.019229 |
| 2 | 0.387472 | 0.008364 | 0.019871 | 0.048506 | 0.016856 | 0.112532 | 0.023723 | 0.041035 | 0.008675 | 0.076355 | ... | 0.011186 | 0.012448 | 0.010874 | 0.037880 | 0.014036 | 0.126050 | 0.319106 | 0.010441 | 0.376539 | 0.023874 |
| 3 | 0.921778 | 0.003868 | 0.011993 | 0.006110 | 0.029487 | 0.013983 | 0.006285 | 0.009679 | 0.006292 | 0.004410 | ... | 0.027170 | 0.004521 | 0.004625 | 0.052609 | 0.063325 | 0.007683 | 0.003120 | 0.011065 | 0.004546 | 0.057416 |
| 4 | 0.021822 | 0.019401 | 0.037472 | 0.093516 | 0.021219 | 0.461508 | 0.086660 | 0.088066 | 0.017920 | 0.314157 | ... | 0.154907 | 0.038912 | 0.022421 | 0.189408 | 0.260326 | 0.129512 | 0.326650 | 0.020201 | 0.085881 | 0.052635 |
5 rows × 24 columns
submission['recording_id'] = recording_id
submission = submission[ ['recording_id','s0', 's1', 's2', 's3', 's4', 's5', 's6', 's7', 's8', 's9', 's10',
's11', 's12', 's13', 's14', 's15', 's16', 's17', 's18', 's19', 's20',
's21', 's22', 's23'] ]
submission.to_csv("submission_MEL_Spec_Mean.csv" , index=False)
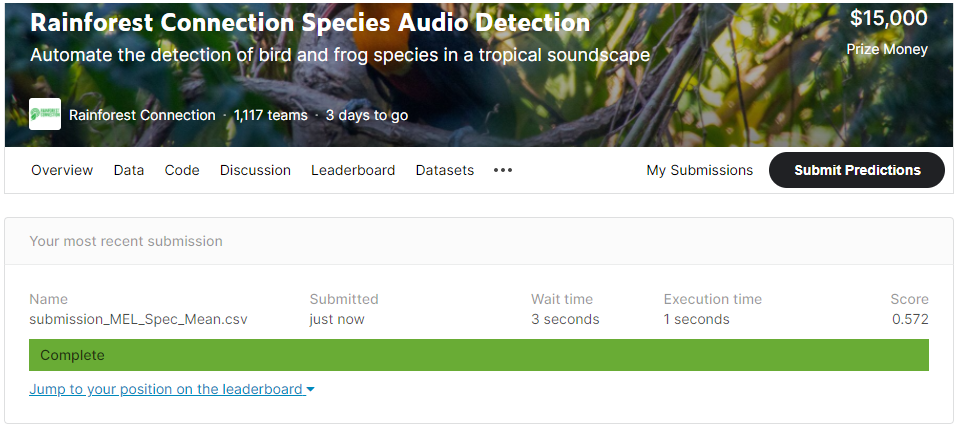
- 자, 이제 다 됐습니다. 제출해 보도록 하죠.
-
점수는 0.572
Baseline 점수로 적절한 것 같네요.
이제부터 다른 방법으로 도전해 보도록 하겠습니다.