Custom Generator
Custom Generator
Custom Generator
-
Model Training시에 Train Data를 넣어주는 방법중에 DataGenerator라는 것을 사용합니다.
-
현재 DataGenerator는 Image Data에 특화된 기능들이 많은데, 이를 다양한 Data에 사용할 수 있는 Custom Generator에 관해서 알아보도록 하겠습니다.
0. Training on Keras
Keras는 Model을 Train 하기 위해서 다음 3가지의 함수를 제공합니다.
- .fit
- .fit_generator
- .train_on_batch
위 3개의 함수가 궁극적으로 하는 일은 User가 정의한 Model을 Train 시킨다는 점에서는 동일하지만, 동작 방식은 조금씩 다릅니다.
각각에 대해서 한 번 알아보도록 하겠습니다.
1. fit
- 기본적인 fit 함수의 사용법은 다음과 같습니다.
model.fit( trainX, trainY, batch_size=32, epochs=50 )
- 위 fit 함수가 의미하는 것은 trainX에 Train Data가, trainY에 그에 해당하는 Label 값들이 들어 있으며, trainX로부터 Train Data를 가져오고, 한 번에 가져오는 Train Data는 32회의 양만큼 가져옵니다. 이 동작을 총 50회 반복합니다. 즉, trainX를 총 50회 반복해서 학습하는 것입니다.
-
fit 함수는 기본적으로 다음과 같은 가정을 하고 동작을 합니다.
1) Train에 사용할 Data( trainX ) 전체가 모두 RAM에 Load되어 있다.
2) Data Augmentation이 적용되지 않는다. 즉, Raw Data 그대로 Train에 이용된다.
2. fit_generator
-
fit 함수는 전체 Dataset이 작고 Simple한 Dataset에 사용하기 좋습니다.
-
그러나 실제로 다루는 Dataset은 그런 형태가 거의 없습니다. 전체 Dataset Size가 매우 커서 전체 Data를 한번에 모두 RAM에 Load한다는 것은 거의 불가능하고, Augmentation이 거의 필수로 필요합니다.
# initialize the number of epochs and batch size
EPOCHS = 100
BS = 32
# construct the training image generator for data augmentation
aug = ImageDataGenerator(rotation_range=20,
zoom_range=0.15,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.15,
horizontal_flip=True,
fill_mode="nearest")
# train the network
H = model.fit_generator(aug.flow(trainX, trainY, batch_size=BS),
validation_data=(testX, testY),
steps_per_epoch=len(trainX) // BS,
epochs=EPOCHS)
- 위의 Code는 ImageDataGenerator를 사용하는 Example Code입니다.
- ImageDataGenerator 객체를 만들고, Image에 적합한 다양한 Augmentation 기능을 초기화합니다.
-
ImageDataGenerator의 다양한 Augmentation Parameter는 아래 Link를 참조해 주세요.
-
Data Augmentation의 장점은 Train Data를 그대로 사용하지 않고, 약간의 변형을 가한 Data를 Train에 사용하므로,
Overfitting이 줄어들고, Model의 Generalization 성능이 좋아집니다.
-
이제 DataGenerator를 사용하면, 이제 더 이상 fit 함수는 사용할 수 없고, fit_generator를 사용해야 합니다.
( 주의 : TF 2.0 부터는 fit_generator가 없어지고 동일한 기능을 fit에서도 지원하다고 하네요. )
-
Datagenerator를 사용하는 경우에 Model Train의 순서는 다음과 같습니다.
1) Keras Model이 Generator를 Call합니다. ( 위의 경우에는 aug.flow )
2) Generator는 Batch Size만 Dataset을 만들어서 fit_generator에 넘겨줍니다.
3) fit_generator는 Generator가 넘겨준 Dataset으로 Train을 하고 Weight를 Update합니다.
4) 이 동작을 Epoch 만큼 반복합니다.
3. train_on_batch
train_on_batch는 아래와 같이 사용합니다.
model.train_on_batch(batchX, batchY)
train_on_batch는 Batch Size를 특정하지 않은 Dataset을 받아서 Weight를 명시적으로 Update합니다.
train_on_batch를 사용하는 경우는, 기존에 사용하던 Model에 추가적인 Dataset이 입수되어서 이 Dataset을 기존 Model에 반영해야 하는 경우입니다.
4. Example of ImageDataGenerator
- ImageDataGenerator를 실제 사용할 때의 Example Code를 한 번 살펴보도록 하겠습니다.
data_generator = ImageDataGenerator(height_shift_range=0.3,
width_shift_range=0.3,
rescale=1./255)
-
ImageDataGenerator 객체를 하나 만듭니다.
-
이 Generator 객체는 몇 가지 Image Data Augmentation을 수행하도록 설정되어 있습니다.
train_gen = data_generator.flow_from_directory("./MEL_Spectogram_Feature_PNG/",
target_size = (RESNET_IMAGE_RESIZE, RESNET_IMAGE_RESIZE),
batch_size = BATCH_SIZE,
class_mode = 'categorical'
)
-
이 부분은 Generator가 어디서 Dataset을 읽어올지를 설정하는 부분입니다.
-
크게 3가지의 flow 계열 함수가 있습니다. ( https://keras.io/api/preprocessing/image/ )
- flow
- Numpy Array로 부터 Dataset을 만들어 냅니다.
- flow_from_dataframe
- Pandas Dataframe으로부터 Dataset을 만들어냅니다.
- 이 Dataframe에는 실제 Data가 들어있는 것이 아니고, Image File이 존재하는 Path 정보와 Label이 들어가 있습니다.
- flow_from_directory
- Directory로부터 바로 Image File을 읽어옵니다.
- 위 Code와 같이 Image File이 존재하는 Path를 Parameter로 넘겨줍니다.
-
flow_from_directory 함수는 Label을 구분할 때, 지정해준 Directory Name을 바탕으로 자동으로 Label을 생성해 줍니다.
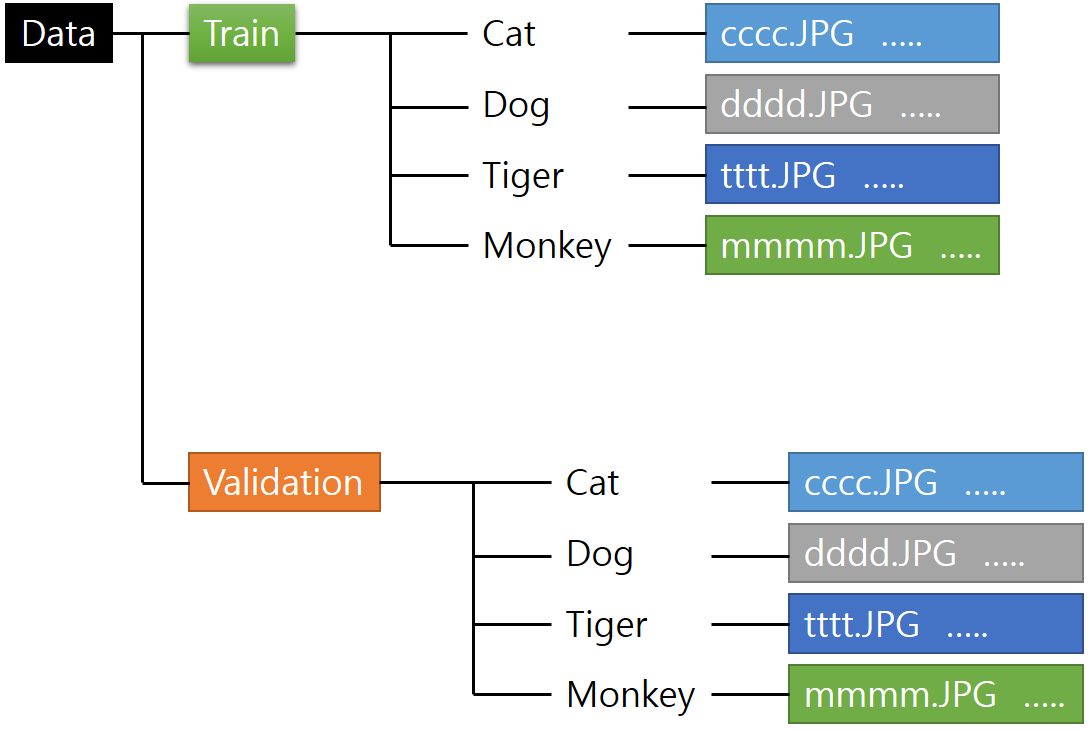
예를 들어 아래와 같은 Directory 구조를 가지고 있다고 한다면,
- flow
-
각 Directory Name을 기준으로 Label을 자동으로 생성해 주기 때문에, Cat / Dog / Tiger / Monkey를 알아서 숫자 Label로 변형해서 Train에 적용됩니다.
-
어떤 Flow 함수를 사용할지는 가지고 있는 Train Data의 종류와 형태에 맞게 선택해서 사용하면 됩니다.
history = model.fit_generator(
train_gen,
steps_per_epoch = 200,
epochs = NUM_EPOCHS,
callbacks=[cb_checkpointer, cb_early_stopper],
verbose=1
)
-
자, 이제 준비는 모두 끝났고, 실제 fit_generator 함수를 사용해 보겠습니다.
-
위와 같이 Generator를 Parameter로 넘겨주고, 필요한 Parameter를 설정하면 알아서 Train을 합니다.
-
Generator 참 편리하죠?
5. Custom Generator
-
ImageDataGenerator의 간단한 사용법을 알아보았습니다. Image 처리에 굉장히 특화되어 있고 강력하고 유용합니다.
-
하지만, Image 이외의 다른 형태의 Data라면 어떻게 해야 할까요?
-
2차원 형태의 Data이지만 Image는 아니어서 ImageDataGenerator의 강력한 기능을 사용할 수 없다면 ?
-
ImageDataGenerator가 제공하는 기본적인 Data Augmentation이 아닌, 자신만의 Custom Augmentation Algorithm을 적용하려면 ?
-
Custom Generator가 이런 기능을 제공해 줍니다.
6. Custom Generator Class
-
Custom Generator는 Sequence Class를 상속받아서 만듭니다.
-
아래 Code는 제가 실제로 사용한 Custom Generator입니다.
-
특정 Directory에 있는 Sound File들을 Batch Size만큼 읽어서 MEL Spec. Feature를 뽑아서 Return해 주는 Code입니다.
class DataGenerator(tf.keras.utils.Sequence):
'Generates data for Keras'
def __init__(self,
list_IDs,
labels,
batch_size=32,
dim=(256,1876),
n_channels=1,
t_min=[],
t_max=[],
recording_id=[],
n_classes=24,
shuffle=True):
'Initialization'
self.dim = dim
self.batch_size = batch_size
self.labels = labels
self.list_IDs = list_IDs
self.n_channels = n_channels
self.t_min = t_min
self.t_max = t_max
self.recording_id = recording_id
self.n_classes = n_classes
self.shuffle = shuffle
self.n = 0
self.max = self.__len__()
self.on_epoch_end()
def __len__(self):
'Denotes the number of batches per epoch'
return int(np.floor(len(self.list_IDs) / self.batch_size))
-
우선, init()에는 필요한 여러가지 변수들 초기화 해주면 됩니다.
batch_size , labels , recording_id , n_classes 등과 같은 변수들은 중요하겠죠?
그 외의 값들은 구현에 따라서 필요에 의해 추가해 주시면 됩니다.
def __getitem__(self, index):
'Generate one batch of data'
# Generate indexes of the batch
indexes = self.indexes[index*self.batch_size:(index+1)*self.batch_size]
# Find list of IDs
list_IDs_temp = [self.list_IDs[k] for k in indexes]
# Generate data
X, y = self.__data_generation(list_IDs_temp)
return X, y
-
getitem()은 __next__에 의해서 Call되는 함수입니다.
fit_generator는 이 함수를 통해 Generator로부터 Data를 받습니다.
보시면 아시겠지만, 실제 Return할 Data를 만들어 내는 것은 이후에 살펴볼 __data_generation()입니다.
def on_epoch_end(self):
'Updates indexes after each epoch'
self.indexes = np.arange(len(self.list_IDs))
if self.shuffle == True:
np.random.shuffle(self.indexes)
def __next__(self):
if self.n >= self.max:
self.n = 0
result = self.__getitem__(self.n)
self.n += 1
return result
-
on_epoch_end()는 이름에 알 수 있듯이, Epoch마다 Call되는 함수이며, Index를 섞는 역할을 합니다.
-
그리고, 중요한 next() 함수인데, fit에서 이 함수를 Call해서 Data를 받아갑니다.
def __data_generation(self, list_IDs_temp):
'Generates data containing batch_size samples' # X : (n_samples, *dim, n_channels)
# Initialization
X = np.empty((self.batch_size, *self.dim, self.n_channels))
y = np.empty((self.batch_size), dtype=int)
# Generate data
for i, ID in enumerate(list_IDs_temp):
# Store sample
wav, sr = librosa.load('./rfcx-species-audio-detection/train/' + recording_id[ID] + '.flac', sr=None)
t_start = self.t_min[ID] * sr
t_end = self.t_max[ID] * sr
# Positioning sound slice
center = np.round((t_start + t_end) / 2)
beginning = center - length / 2
if beginning < 0:
beginning = 0
ending = beginning + length
if ending > len(wav):
ending = len(wav)
beginning = ending - length
slice = wav[int(beginning):int(ending)]
aug_slice = transform( slice )
mel_spec = librosa.feature.melspectrogram(aug_slice, n_fft=fft, hop_length=hop, sr=sr, fmin=F_MIN, fmax=F_MAX, power=2)
mel_spec = librosa.core.amplitude_to_db(np.abs(mel_spec))
mel_spec = mel_spec - np.min(mel_spec)
mel_spec = mel_spec / np.max(mel_spec)
stacked = resize(mel_spec , (self.dim[0], self.dim[1], self.n_channels))
X[i,] = stacked
# Store class
y[i] = self.labels[ID]
return X, tf.keras.utils.to_categorical(y, num_classes=self.n_classes)
-
실제 Data를 Disk로부터 읽어서 Augmentation을 하고 Shape에 맞게 변형해서 Return해주는 __data_generation() 입니다.
-
librosa.load()로 실제 Sound File을 읽어서, 미리 설정된 길이만큼을 잘라냅니다.
-
그후에 transform()이라는 Augmentation 함수를 통해서 Data Augmentation을 수행합니다.
-
이 함수는 원하는 다양한 Augmentation Algorithm을 사용하시면 됩니다.
-
그 후에 실제 Train에 사용할 Model의 입력 Dimension에 맞게 변형을 거친 후에 Label과 함께 Batch Size만큼 모아서 Return해 주면 됩니다.
-
Custom Generator를 만드는 방법을 알아보았는데, 글을 읽으신 분들께 조금이나마 도움이 되었으면 합니다.