Transformer #3 - Overall
안녕하세요, 이번 Post에서는 Transformer의 전체 구조를 개괄적으로 알아보도록 하겠습니다.
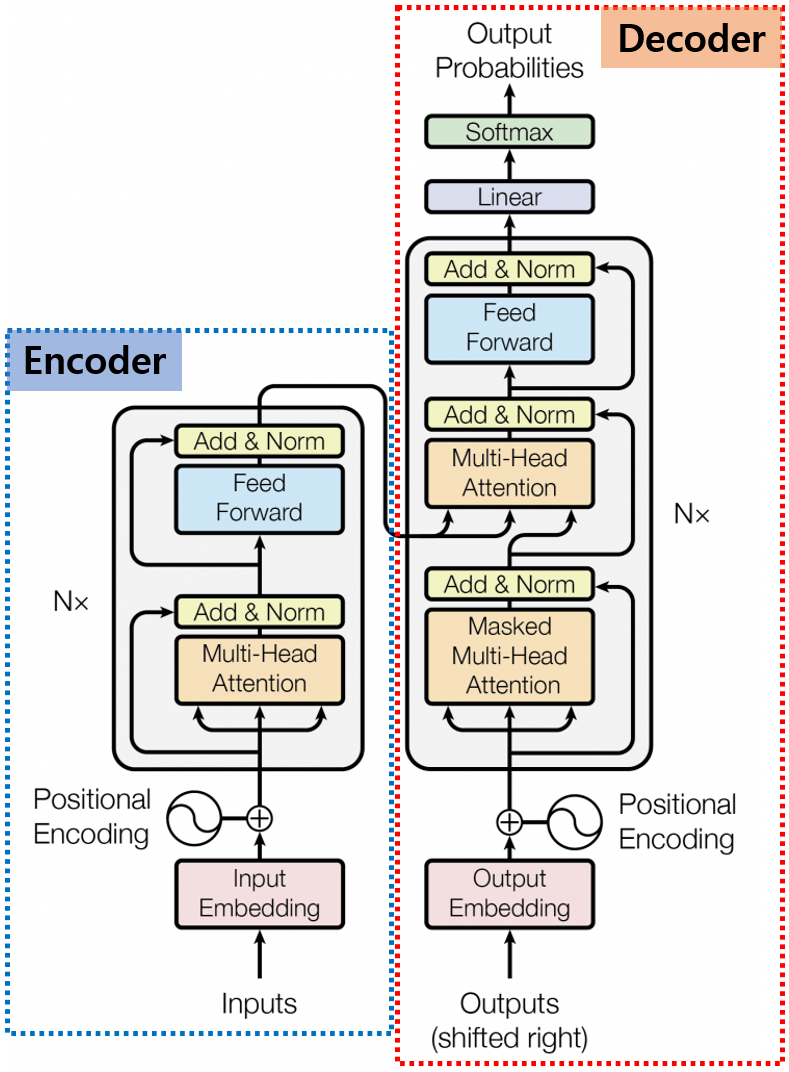
Transformer의 전체 구조의 위와 같습니다. 왼쪽이 Encoder의 구조이고, 오른쪽이 Decoder입니다.
0. Encoder
먼저 Encoder의 구조에 대해서 간략하게 살펴보겠습니다.
0.0. Tokenizer
가장 아래쪽에 Inputs이 있습니다. Transformer에서 Input은 단어들로 이루어진 문장이 되겠죠.
이 그림에서는 생략되어 있는데, Input Embedding Layer에 문장 전체가 들어갈 수는 없기 때문에 그전에 tokenizer를 이용하여, 문장들을 Token 단위로 나눕니다.
Transformer에서는 주로 WordPiece Tokenizer를 사용하여 문장을 Token으로 나눕니다.
0.1. Input Embedding Layer
Tokenizer로 Token으로 분리된 입력 문장은 Embedding Layer로 들어갑니다.
Embedding Layer의 역할은 Token을 의미론적 정보를 보존한 채 Vector로 변환하는 역할을 합니다.
이후 이 Vector를 이용하여 다양한 작업을 하게 됩니다.
0.2. Positional Encoding
Seq2Seq 구조(Link 주소)에서는 구조적인 영향으로 입력 단어의 위치에 대한 정보가 자동으로 포함됩니다.
하지만, Transformer 구조에서는 한 번에 모든 단어를 처리하기 때문에 입력 시퀀스의 순서 정보를 고려하지 않는다는 한계가 있습니다.
따라서 같은 단어들이라도 문장 내에서의 위치에 따라 다른 의미를 가질 수 있는 자연어 처리 작업에서는 순서 정보를 Model에 제공하는 것이 중요합니다.
이러한 이유로 Positional Encoding이 필요합니다.
0.3. Multi Head Attention
앞서 알아본 Self Attention에서는 Q, K, V Vector를 만들 때 단어의 Embedding에 Wk, Wq, Wv를 곱해서 값을 만들어 냈습니다.
이때, Wk, Wq, Wv를 여러 개 만들어서 하나의 단어에 대해서 여러 개의 Q, K, V Vector를 만들겠다는 것이 Multi-Head Attention의 핵심 아이디어입니다.
이렇게 하면 주목해야 하는 단어가 무엇인지를 더 잘 파악할 수 있고, 더불어 각 단어가 갖고 있는 문맥적 특성을 더 잘 표현할 수 있다는 장점도 있습니다.
0.4. Add & Norm Layer
Multi Head Attention Layer를 통과하기 전의 Input을 Residual Connection으로 받아서 Gradient 소실 문제와 학습 안정화에 도움을 줍니다.
또한, Layer Normalization을 함으로써 Gradient 분포를 관리하여 학습 속도를 향상시켜 줍니다.
0.5. Feed Forward Layer
2개의 Fully Connected Layer로 구성되어 있으며, 하나는 ReLU를 거치고 나머지는 하나는 Activation Function이 없는 선형 Fully Connected Layer입니다.
Feed Forward Layer는 비선형 변환과 Mapping을 통해 Model이 복잡한 언어적 패턴을 학습하는 데 도움을 줍니다.
1. Decoder
Transformer 모델의 Encoder는 주어진 문장을 처리를 한 번에 모두 합니다.
Tokenizer , Input Embedding, Positional Encoding 모두 전체 문장 단위로 한 번에 처리합니다.
하지만, Decoder는 자기 회귀적 특성을 가지고 있습니다.
자기 회귀적 특성이란 Sequence마다 이전 단계에서 생성된 단어를 현재 단계의 입력으로 사용해서 다음 단어를 예측하며 단어의 Sequence를 하나씩 확장한다는 의미입니다.
이런 Decoder의 자기 회귀적 특성 때문에 Decoder의 각 부분은 Encoder의 각 부분과 약간 다른 동작이 필요합니다.
1.1. Output Embedding Layer
Decoder에서 사용하는 Embedding Layer는 Encoder에서 사용하는 Embedding Layer와 출력 Dimension은 동일하지만,
Decoder의 자기 회귀적인 특성 때문에 Encoder의 Embedding Layer와는 조금 다른 특성을 가집니다.
1.2. Positional Encoding
Encoder의 Positional Encoding은 문장 전체 Token에 대해서 상숫값의 Positional Encoding을 적용하지만,
Decoder의 자기 회귀적인 특성 때문에 이전 단계에서 생성된 출력 Token의 위치 정보만 Positional Encoding 값을 적용하고, 이후 단어에 대한 값은 Masking 처리해야 합니다.
1.3. Masked Multi-Head Attention
기본적으로 Encoder에서 사용하는 Multi-Head Self Attention 구조를 사용하지만, Train 시에는 다음에 올 정답 Data와 Model이 예측한 Data의 오차를 이용해서 Train을 진행합니다.
이를 위해서 전체 Data의 Attention Score를 모두 사용하지 않고, 다음 예측에 사용할 Data만 사용하고 나머지는 Masking 한 후 Train 시킨다.
1.4. Multi-Head Attention
일반적인 Self Attention 구조와 동일하나, 그림에서도 알 수 있듯이 Encoder에서 넘어오는 값 중 일부를 입력으로 사용합니다.
입력되는 Q, K, V 값 중에 Q는 Decoder의 값을 사용하고, K, V는 Encoder에서 넘어오는 값을 사용합니다.
Encoder의 정보를 사용하겠다는 의미입니다.
이번 Post에서는 Transformer의 전체적인 구조와 각 항목의 특징을 개괄적으로 알아보았습니다.
이후의 Post에서 각 항목의 동작 방법을 자세하게 알아보도록 하겠습니다.
감사합니다.