DCGAN(Deep Convolutional Generative Adversarial Networks)
DCGAN(Deep Convolutional Generative Adversarial Networks)
0. Introduction
-
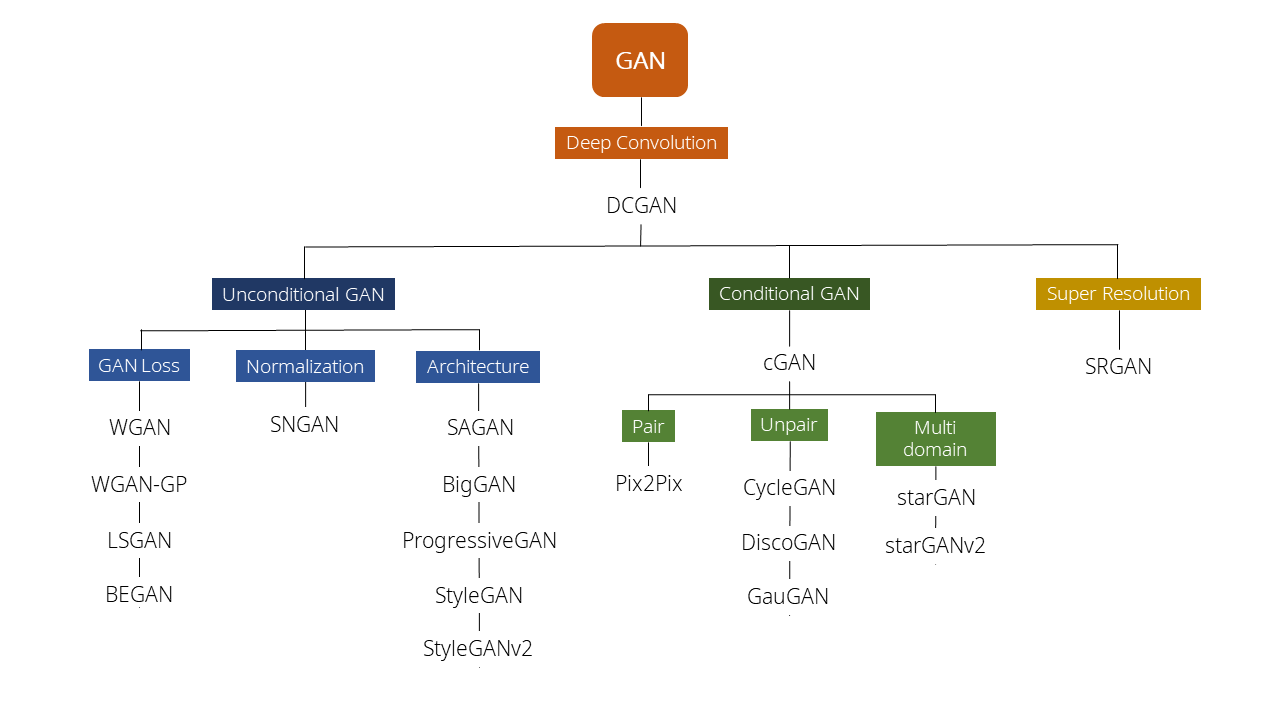
Goodfellow, Ian이 2014년에 GAN을 소개한 이후에 아래 그림과 같이, 매우 다양한 GAN 응용이 나왔습니다.
( GAN의 다양한 종류. 출처 : https://ysbsb.github.io/gan/2020/06/17/GAN-newbie-guide.html )
-
이번 Post에서는 그 중에서도 모든 GAN응용의 시작이라고 할 수 있는 DCGAN(Deep Convolutional Generative Adversarial Networks)을 살펴보도록 하겠습니다.
- DCGAN은 2016년에 Alec Radford & Luke Metz , Soumith Chintala에 의해서 발표됩니다.
-
Paper 정식 제목은 ‘UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS’이며, Paper Link는 아래를 참고하시기 바랍니다.
UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS
1. Issues of GAN
- 이 Paper에서는 기존 GAN의 몇 가지 한계점을 언급하고 있습니다.
- GANs have been known to be unstable to train, often resulting in generators that produce nonsensical outputs.
- GAN의 구조 자체가 불안정해서 Train시키기가 쉽지 않습니다.
- One constant criticism of using neural networks has been that they are black-box methods, with little understanding of what the networks do in the form of a simple human-consumable algorithm.
- Neural Net 구조가 가지는 고질적인 한계인데, 학습된 Model의 해석이 어렵습니다.
- Model이 어떤 근거로 판단을 했는지 알수 없기 때문에 흔히, Model을 ‘Black-Box’같다라고 표현합니다.
- GAN Model 성능을 정량적으로 평가하기가 어렵다.
- 기존 Sample로부터 얼마나 잘 생성되었는지 정량적으로 판단하기가 애매하고, 사람이 평가하기도 힘듭니다.
2. Purpose of DCGAN
- Generator가 단순히 Sample Data를 Memorize해서 보여주는 것이 아니라는 것을 증명
- Model의 구조가 Sample Data 대비해서 충분히 크고, Train을 충분히 많이 진행한다면 Model이 Sample Data를 모두 외워버릴 수도 있습니다.
- 이것은 Generating이라고 보기 힘들다.
- 얼핏 Overfitting과 일맥상통하는 것 같기도 하고…
- WALKING IN THE LATENT SPACE
- Latent Space의 z의 작은 변화에도 Generation 결과가 자연스럽게 이루어져야 한다. ( 이를 Paper에서는 WALKING IN THE LATENT SPACE 라고 표현했습니다. )
3. Architecture Guidelines
3.1. Overall
- GAN에서 제시한 구조에서 DCGAN으로 넘어오면서 전체적인 구조는 그대로 유지되지만 몇몇 세부적인 사항들이 바뀌었습니다.
- 저자들이 이런 구조를 확립한 방법을 Paper에서 아래와 같이 말하고 있습니다.
- after extensive model exploration we identified a family of architectures that resulted in stable training across a range of datasets and allowed for training higher resolution and deeper generative models.
- Paper에서는 있어 보이게 거창하게 말하고 있지만, 한 마디로 생노가다로 최상의 Model 구조를 알아냈다는 의미입니다.
- 근성만은 인정해줘야 할 것 같네요.
- after extensive model exploration we identified a family of architectures that resulted in stable training across a range of datasets and allowed for training higher resolution and deeper generative models.
3.2. Modification Points
- DCGAN에서 제안한 기존 GAN의 성능을 향상 시킬 수 있는 방법들은 다음과 같습니다.
1. G / D에서 Pooling Layer대신 D에는 strided convolutions, G에는 fractional-strided convolutions 사용
2. Batch Normalization 사용
3. FC(Fully Connected) Hidden Layer를 모두 삭제
4. G에서 마지막 Layer를 제외하고 Activation Function을 RELU사용. 마지막 Layer는 tanh 사용
5. D에서는 모든 Layer의 Activation Function을 LeakyRELU 사용
- 수정 내용들에 대해서 하나씩 살펴보도록 하겠습니다.
3.2.1. Add Convolution Layer
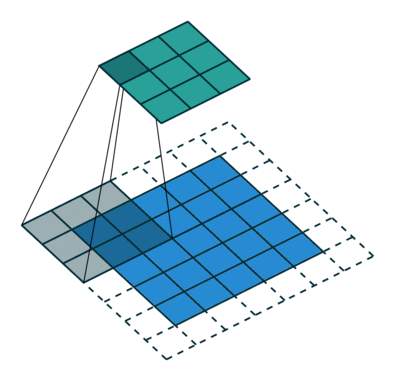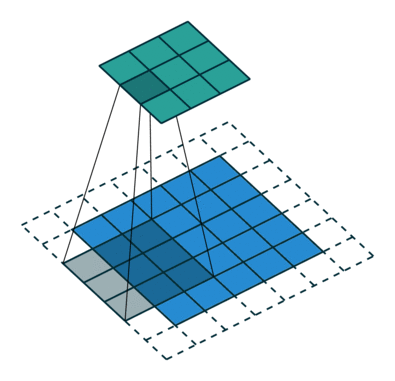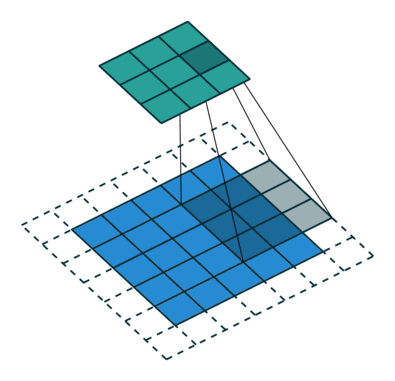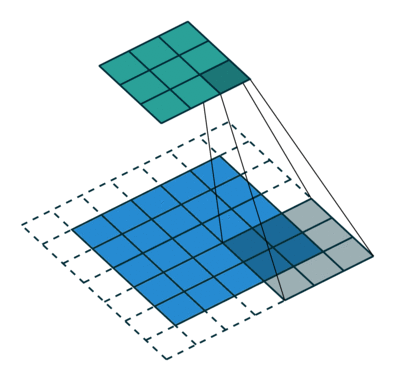
- 우선, Pooling Layer대신 사용한 strided convolutions과 fractional-strided convolutions에 대해서 알아보겠습니다.
- strided convolutions과 fractional-strided convolutions은 Convolution 방식 중의 하나지만, 기존 CNN에 적용되었던 Convolution은 Kernel을 거치면서 Size가 점점 줄어드는데 비해서 strided convolutions과 fractional-strided convolutions은 특정 연산을 거치면서 Size가 증가하는 차이가 있습니다.
- 아래는 strided convolutions을 설명한 것이며, 한 마디로 strided convolutions은 stride 만큼 이동하는 Convolution입니다.
- fractional-strided convolutions은 Transposed Convolution이라고 하는데(Deconvolution이라고 하는 곳도 있는데 이는 정확한 개념이 아닙니다. Transposed Convolution과 Deconvolution의 차이는 여기를 참조. ), DCGAN의 Generator에서 사용하는 방식은 정확하게 말하면, Transposed Convolution입니다.

-
Transposed Convolution에 대한 자세한 내용은 아래 Link의 글을 한 번 읽어보시기 바랍니다.
CS231n의 Transposed Convolution은 Deconvolution에 가까운 Transposed Convolution이다
- Transposed Convolution은 Tensorflow에서 Conv2DTranspose()라는 함수로 구현되어 있습니다.
-
다양한 Convolution 방식들에 대한 설명은 아래 Link를 참조하시면 많은 정보를 얻을 수 있습니다.
An Introduction to different Types of Convolutions in Deep Learning
3.2.2. Apply Batch Normalization
- Batch Normalization은 2015년에 발표된 Paper, Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift에서 소개된 개념이며, 성능이 좋아서 요즘 대부분의 Neural Network에 적용되고 있습니다.
- Paper Link( http://proceedings.mlr.press/v37/ioffe15.pdf )
- Batch Normalization의 목적은 Gradient Vanishing / Gradient Exploding을 방지하기 위함입니다.
- Batch Normalization가 나오기 이전에도 Activation Function을 ReLU를 사용한다던지, Weight Initialization을 할 때, He or Xavier initialization을 사용하곤 했습니다.
- Batch Normalization은 이런 간접적인 방식과는 다르게 Training 과정에 직접적으로 관여하면서 Gradient Vanishing / Gradient Exploding을 억제합니다.
-
자세한 설명은 아래 Link를 참조해 주시기 바랍니다.
A Gentle Introduction to Batch Normalization for Deep Neural Networks
3.2.3. Others
- 나머지 변경 내용들에 대해서 추가적인 설명은 생략하겠습니다.
- 내용을 보시면 특별하게 설명이 필요한 사항은 없을 것 같습니다.
- 다시 한 번 말씀드리지만, 왜 Fully Connected를 없애고, strided convolutions과 fractional-strided convolutions를 사용했으며, 특정 위치에만 Batch Normalization을 사용하고 Activation Function을 위치에 따라 다르게 사용했는지에 대한 이론적 배경은 전혀 없고, 단순히 노가다를 통해 결과를 관찰하여서 알아낸 결과들입니다.
3.2.4. Overall Architecture
- 위에서 언급한 내용을 적용한 Generator의 전체적인 Architecture는 다음과 같습니다.
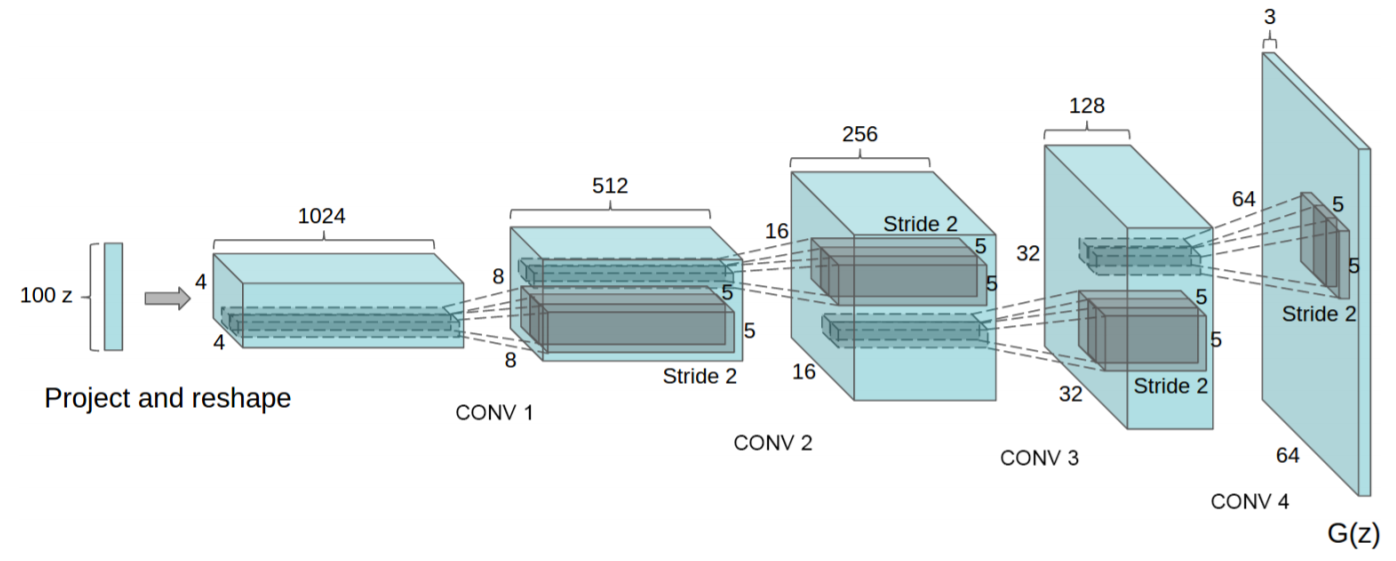
- 최초에 z에서 64x64의 Image가 되어가는 과정에서 fractional-strided convolutions가 적용되었으며, Fully Connected Layer나 Pooling Layer가 사용되지 않았습니다.
4. Result
4.1. Image Generation
- 아래의 Bedroom Image들은 모두 1 Epoch Training 후에 DCGAN으로 생성된 Image라고 합니다.

- 아래의 Bedroom Image들은 5 Epoch Training 후에 DCGAN으로 생성된 Image라고 합니다.

- 딱 봐도 Quality가 훌륭합니다.
- Paper에서 말하기를 이론적으로는 Generator가 Sample Data를 Memorize 할 수 있지만, 낮은 Learning Rate와 Mini Batch를 적용함으로써 실험적으로 그것이 불가능하다고 말하고 있습니다.
4.2. WALKING IN THE LATENT SPACE
- Paper에서 DCGAN의 목표중의 하나가 z의 작은 변화에도 Smooth하게(Walking) 결과가 변화하도록 하는 것이다라고 했습니다.

- 위의 사진은 왼쪽의 원본 Image에서 오른쪽의 Generated Image로 점점 변화하는 것을 나타낸 것입니다.
- 벽이 있던 곳이 어느새 창문이 생기고, 전등이 있던 곳이 창문이 생기기도 합니다.
4.3. Black Box 극복
- DCGAN의 Discriminator의 Feature를 시각화해서 Model이 어떻게 동작하는지를 좀 더 명확하게 알 수 있게 되었습니다.

4.4. VECTOR ARITHMETIC ON IMAGE
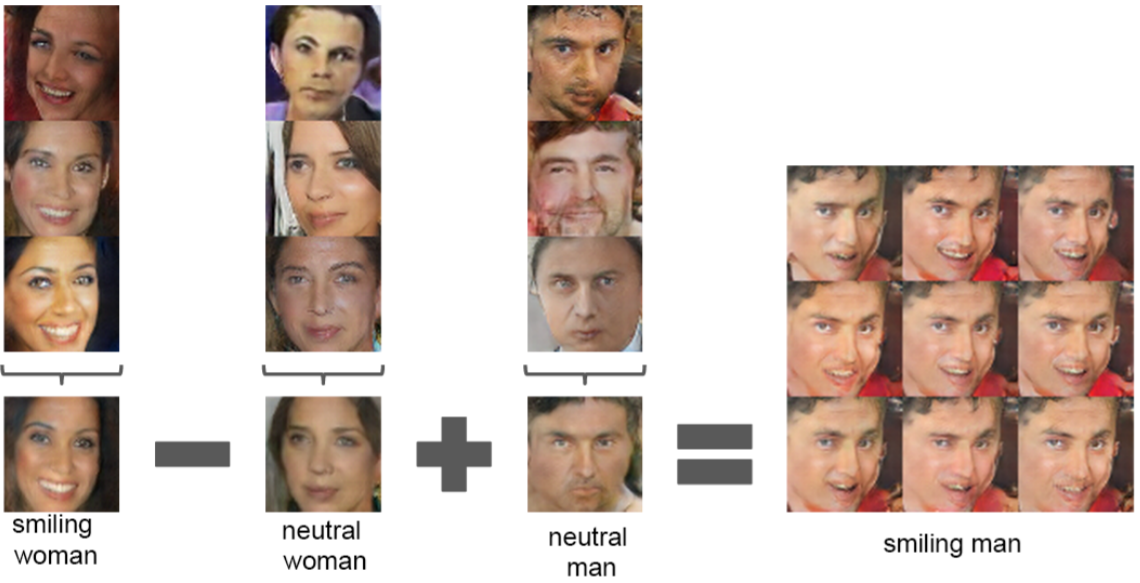
- Paper에서는 DCGAN을 하면서 NLP에서 사용된 Word2Vec의 특성을 Image에서도 사용할 수 있었다고 합니다.
- 예를 들어, Word2Vec에서 vector(”King”) - vector(”Man”) + vector(”Woman”) = Queen 이 되는 것처럼, Image에서도 이와 유사한 VECTOR ARITHMETIC 연산을 할 수 있었다고 하네요.

- 이번 Post에서는 DCGAN Paper Review를 해 보았습니다.
- 다음에는 DCGAN의 실제 Code를 살펴보도록 하겠습니다.