Dog & Cat Classification Exercise #01
CNN Exercise #01 - 개와 고양이 사진 분류하기
- Exercise #00에서는 Dropout 과 Data Augmentation으로 정확도를 올리는 방법을 사용해 보았습니다.
- 이번에는 다른 사람이 Train 시켜 놓은 훌륭한 Pre-Trained Model을 이용하여 정확도를 더 끌어올려 보겠습니다.
- 앞 Exercise와 마찬가지로 이번에도 Keras를 사용하도록 하겠습니다.
import keras
keras.__version__
Using TensorFlow backend.
'2.2.4'
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
0. Load Pre-Trained Model
- 이번 Exercise에서 사용할 Pre-Trained Model은 VGG16입니다.
- VGG16은 구조가 간단하고 ImageNet 데이터셋에 널리 사용되는 Conv. Net입니다.
- VGG16은 조금 오래되었고 최고 수준의 성능에는 못미치며 최근의 다른 모델보다는 조금 무겁습니다.
-
하지만 이 모델의 구조가 이전에 보았던 것과 비슷해서 새로운 개념을 도입하지 않고 이해하기 쉽기 때문에 선택하였습니다.
- CNN의 전반적인 설명과 다른 Pre-Trained Model에 대해서 알아보시려면 아래 Link의 Post를 참고하시기 바랍니다.
- VGG16 Model은 아래와 같이 구성되어 있습니다.
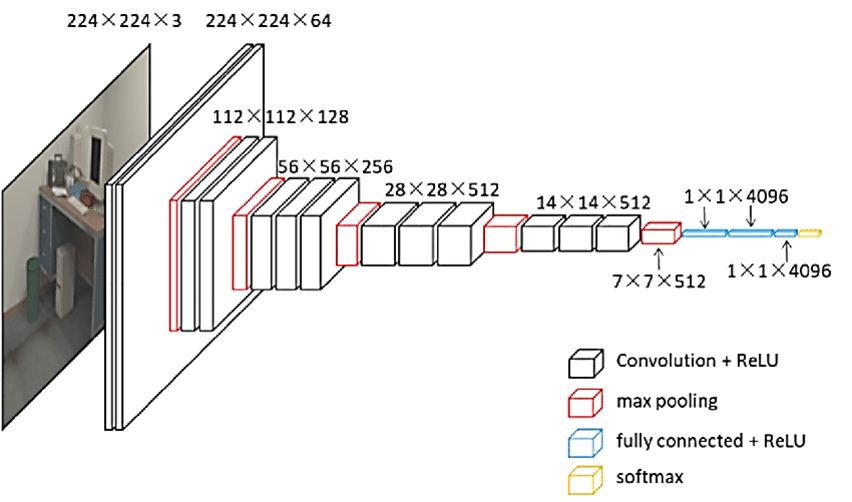
- Keras에서 VGG Model을 Load하는 것은 매우 쉽습니다.
- 아래와 같은 Code를 이용해서 VGG16 Model을 Load할 수 있습니다.
-
include_top=False은 최종 Layer인 Softmax Layer를 빼고 사용하겠다는 의미입니다. - 다른 Pre-Trained Model도 비슷하지만, 마지막 Softmax Layer는 그 앞 Layer들이 추출한 Image들의 Feature를 단순히 분류하는 기능입니다.
- 앞 Layer들이 ImageNet의 Data들의 Feature들을 Extract하였다면, 마지막 Softmax Layer는 ImageNet을 분류하는 Classifier가 됩니다.
- 이는 VGG16 Model을 우리 Model에서 Feature만 Extract하고, 이미지의 분류는 우리가 정의한 Classifier를 사용하겠다는 의미입니다.
from keras.applications import VGG16
conv_base = VGG16(weights='imagenet',
include_top=False,
input_shape=(150, 150, 3))
WARNING:tensorflow:From C:\Users\Moon\Anaconda3\lib\site-packages\keras\backend\tensorflow_backend.py:74: The name tf.get_default_graph is deprecated. Please use tf.compat.v1.get_default_graph instead.
WARNING:tensorflow:From C:\Users\Moon\Anaconda3\lib\site-packages\keras\backend\tensorflow_backend.py:517: The name tf.placeholder is deprecated. Please use tf.compat.v1.placeholder instead.
WARNING:tensorflow:From C:\Users\Moon\Anaconda3\lib\site-packages\keras\backend\tensorflow_backend.py:4138: The name tf.random_uniform is deprecated. Please use tf.random.uniform instead.
WARNING:tensorflow:From C:\Users\Moon\Anaconda3\lib\site-packages\keras\backend\tensorflow_backend.py:3976: The name tf.nn.max_pool is deprecated. Please use tf.nn.max_pool2d instead.
WARNING:tensorflow:From C:\Users\Moon\Anaconda3\lib\site-packages\keras\backend\tensorflow_backend.py:174: The name tf.get_default_session is deprecated. Please use tf.compat.v1.get_default_session instead.
WARNING:tensorflow:From C:\Users\Moon\Anaconda3\lib\site-packages\keras\backend\tensorflow_backend.py:181: The name tf.ConfigProto is deprecated. Please use tf.compat.v1.ConfigProto instead.
- VGG16 Model의 구조와 Parameter수는 아래와 같습니다.
conv_base.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 150, 150, 3) 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 150, 150, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 150, 150, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 75, 75, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 75, 75, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 75, 75, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 37, 37, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 37, 37, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 37, 37, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 37, 37, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 18, 18, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 18, 18, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 18, 18, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 18, 18, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 9, 9, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 4, 4, 512) 0
=================================================================
Total params: 14,714,688
Trainable params: 14,714,688
Non-trainable params: 0
_________________________________________________________________
1. Train Model
- 사전 훈련된 네트워크를 사용하는 크게 두 가지 방법이 있습니다.
- 특성 추출 ( Feature Extract )
- 이 방법은 앞서 말씀드린 Pre-Trained Model을 Feature Extractor로 사용하는 방법입니다.
- 첫번째 사용 방법은 기존 Model에서 마지막 Softmax Layer만 없애고, 새롭게 Classifier를 추가하는 방법입니다.
- 최종 Softmax Layer만 새롭게 학습하기 때문에 빠른 시간내에 적용할 수 있습니다.
- 두번째 사용 방법은 Data Augmentation을 이용하여 Ovetfitting을 피하는 방법입니다.
- 미세 조정 ( Fine Tune )
- Pre-Trained Model의 마지막 Softmax Layer만 따로 학습하는 것이 아니라, Softmax Layer를 포함한 그 직전의 Conv. Layer도 학습하는 방법입니다.
- 주어진 문제에 조금 더 밀접하게 재사용 모델의 표현을 일부 조정하기 때문에 미세 조정이라고 부른다.
- 특성 추출 ( Feature Extract )
1.1. 방법 #01-01
- 기존 VGG Model에서 Top(Softmax)만 제외합니다. 이를 conv_base라고 부르겠습니다.
- Train Data(2000개)를 conv_base Model에 넣어서 Feature들을 Extract 합니다.
- conv_base에 Train Data를 Predict하여 Feature들을 모읍니다. ( 2000 x 4 x 4 x 512 )
- 전체 Data는 2000개 이고, VGG16의 최종 Output이 4 x 4 x 512 입니다.
- 이것을 (2000 x 8192 )로 Reshape한 후에, FC에 연결하여 Binary Classification 합니다.
Feature Extract
- Feature Extract은 Pre-Trained Model을 사용해 새로운 Dataset에서 Feature을 뽑아내는 것을 말합니다.
-
뽑아낸 Feature을 사용하여 New Classifier를 Train 시킵니다.
- Conv.Net은 Image Classification를 위해 크게 두 부분으로 구성됩니다.
- 연속된 Conv. Layer와 Pooling Layer로 시작해서 완전 연결 분류기로 구성됩니다.
- 첫 번째 부분을 모델의 합성곱 기반층(convolutional base)이라고 부르겠습니다.
- Conv.Net의 경우 Fearue Extract는 사전에 훈련된 Model의 합성곱 기반층을 선택해 새로운 데이터를 통과시키고 그 출력으로 새로운 분류기를 훈련합니다.
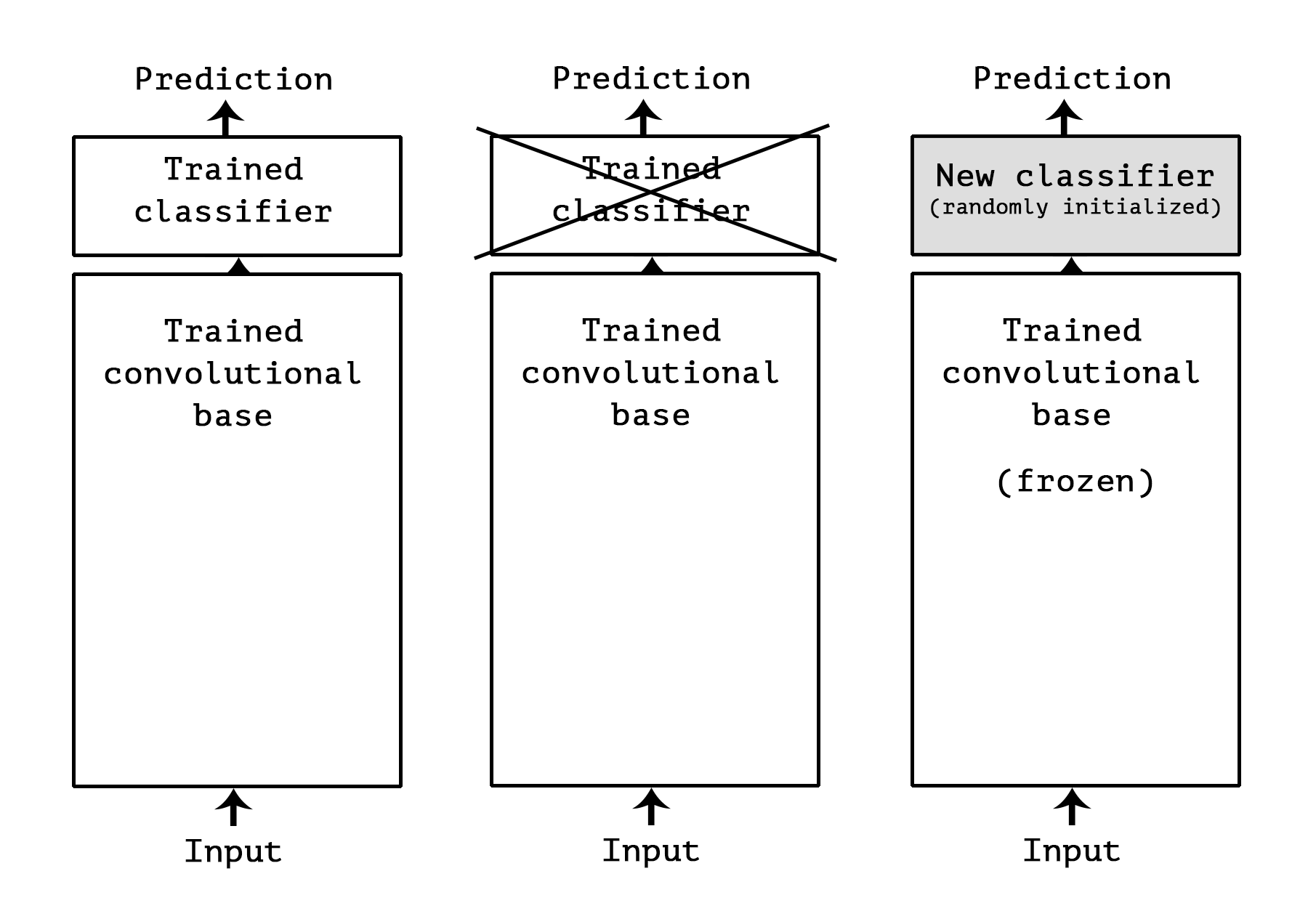
- Classifier만 재학습하는 이유는 분류기에서 학습한 표현은 모델이 훈련된 클래스 집합(VGG16의 경우는 ImageNet Dataset)에 특화되어 있기 때문에 새로운 Dataset에 크게 쓸모가 없기 때문입니다.
- 특정 합성곱 층에서 추출한 표현의 일반성(그리고 재사용성)의 수준은 모델에 있는 층의 깊이에 달려 있습니다.
- 모델의 하위층(Input Layer에 가까운 쪽)은 (에지, 색깔, 질감 등과 같이) 지역적이고 매우 일반적인 특성 맵을 추출합니다.
- 반면 상위 층은 (‘강아지 눈’이나 ‘고양이 귀’와 같이) 좀 더 추상적인 개념을 추출하는 특성이 있습니다.
- 만약 새로운 Dataset이 원본 모델이 훈련한 데이터셋과 많이 다르다면 전체 합성곱 기반층을 사용하는 것보다는 모델의 하위 층 몇 개만 특성 추출에 사용하는 것이 좋습니다.
- 이런저런 일반적인 설정을 합니다.
- Folder Name을 설정하고, Feature Extract 할 Data Generator도 만듭니다.
import os
import numpy as np
from keras.preprocessing.image import ImageDataGenerator
base_dir = './dataset'
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
test_dir = os.path.join(base_dir, 'test')
datagen = ImageDataGenerator(rescale=1./255)
batch_size = 20
- Train Data 2000장의 Feature Extract합니다.
- Softmax Layer를 제외한 Conv. Base Model로 Predict를 하면 해당 Image에 대한 Feature가 추출되겠죠 ?
- ImageDataGenerator의 사용법을 유심히 봐 둘 필요가 있습니다.
- ImageDataGenerator가 Return 해주는 Data와 그 Data의 Format도 봐주시기 바랍니다.
def extract_features(directory, sample_count):
features = np.zeros(shape=(sample_count, 4, 4, 512))
labels = np.zeros(shape=(sample_count))
generator = datagen.flow_from_directory(
directory,
target_size=(150, 150),
batch_size=batch_size,
class_mode='binary')
i = 0
for inputs_batch, labels_batch in generator:
#print( labels_batch.shape , labels_batch[0] )
# label은 (20,)의 1차원 ndarrdy
#print( inputs_batch.shape , inputs_batch[0] )
# inputs_batch은 (20,150,150,3) ndarrdy
features_batch = conv_base.predict(inputs_batch)
features[i * batch_size : (i + 1) * batch_size] = features_batch
labels[i * batch_size : (i + 1) * batch_size] = labels_batch
i += 1
if i * batch_size >= sample_count:
# 제너레이터는 루프 안에서 무한하게 데이터를 만들어내므로 모든 이미지를 한 번씩 처리하고 나면 중지합니다
break
return features, labels
train_features, train_labels = extract_features(train_dir, 2000)
Found 2000 images belonging to 2 classes.
- extract_features 가 Return한 Data의 형태를 보도록 하겠습니다.
- features, labels을 Return하고 있고, features는 (2000, 4, 4, 512) , labels은 (2000,)의 형태를 갖습니다.
- (4, 4, 512)는 Conv. Base의 출력이며, 각 Image의 Feature가 되겠고, 전체 Image 갯수는 2000개 이기 때문에 (2000, 4, 4, 512) Shape이 됩니다.
- labels는 각 Image의 Label( Dog or Cat)을 0,1로 표현되어 있습니다.
type( train_features )
train_features.shape
train_labels.shape
train_labels[0:10]
numpy.ndarray
(2000, 4, 4, 512)
(2000,)
array([0., 1., 0., 0., 1., 1., 0., 0., 0., 1.])
- Validation / Test Data도 위와 동일하게 Feature Extract를 진행하도록 하겠습니다.
validation_features, validation_labels = extract_features(validation_dir, 1000)
Found 1000 images belonging to 2 classes.
test_features, test_labels = extract_features(test_dir, 1000)
Found 1000 images belonging to 2 classes.
- 자~! 이제 Train Data가 모두 준비되었습니다.
- Dog & Cat Classifier를 Train 시키기 위해서 Feature Array를 Reshape하도록 하겠습니다.
- Feature를 1차원 Array로 쭉 편다고 생각하시면 됩니다.
train_features = np.reshape(train_features, (2000, 4 * 4 * 512))
validation_features = np.reshape(validation_features, (1000, 4 * 4 * 512))
test_features = np.reshape(test_features, (1000, 4 * 4 * 512))
- 적당한 Dense Layer를 만들어서 Train을 시작해 보겠습니다.
- 최종 Classifier만 학습하기 때문에 시간이 많이 걸리지 않습니다.
from keras import models
from keras import layers
from keras import optimizers
model = models.Sequential()
model.add(layers.Dense(256, activation='relu', input_dim=4 * 4 * 512))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer=optimizers.RMSprop(lr=2e-5),
loss='binary_crossentropy',
metrics=['acc'])
history = model.fit(train_features, train_labels,
epochs=30,
batch_size=20,
validation_data=(validation_features, validation_labels))
WARNING:tensorflow:From C:\Users\Moon\Anaconda3\lib\site-packages\keras\backend\tensorflow_backend.py:3445: calling dropout (from tensorflow.python.ops.nn_ops) with keep_prob is deprecated and will be removed in a future version.
Instructions for updating:
Please use `rate` instead of `keep_prob`. Rate should be set to `rate = 1 - keep_prob`.
WARNING:tensorflow:From C:\Users\Moon\Anaconda3\lib\site-packages\keras\optimizers.py:790: The name tf.train.Optimizer is deprecated. Please use tf.compat.v1.train.Optimizer instead.
WARNING:tensorflow:From C:\Users\Moon\Anaconda3\lib\site-packages\tensorflow\python\ops\nn_impl.py:180: add_dispatch_support.<locals>.wrapper (from tensorflow.python.ops.array_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.where in 2.0, which has the same broadcast rule as np.where
Train on 2000 samples, validate on 1000 samples
Epoch 1/30
2000/2000 [==============================] - 1s 723us/step - loss: 0.6165 - acc: 0.6515 - val_loss: 0.4434 - val_acc: 0.8260
Epoch 2/30
2000/2000 [==============================] - 1s 280us/step - loss: 0.4296 - acc: 0.8090 - val_loss: 0.3600 - val_acc: 0.8590
Epoch 3/30
2000/2000 [==============================] - 1s 276us/step - loss: 0.3520 - acc: 0.8420 - val_loss: 0.3238 - val_acc: 0.8720
Epoch 4/30
2000/2000 [==============================] - 1s 276us/step - loss: 0.3103 - acc: 0.8710 - val_loss: 0.3069 - val_acc: 0.8760
Epoch 5/30
2000/2000 [==============================] - 1s 283us/step - loss: 0.2899 - acc: 0.8870 - val_loss: 0.2848 - val_acc: 0.8920
Epoch 6/30
2000/2000 [==============================] - 1s 282us/step - loss: 0.2677 - acc: 0.8930 - val_loss: 0.2721 - val_acc: 0.8970
Epoch 7/30
2000/2000 [==============================] - 1s 277us/step - loss: 0.2470 - acc: 0.9025 - val_loss: 0.2645 - val_acc: 0.8960
Epoch 8/30
2000/2000 [==============================] - 1s 280us/step - loss: 0.2328 - acc: 0.9065 - val_loss: 0.2608 - val_acc: 0.8940
Epoch 9/30
2000/2000 [==============================] - 1s 280us/step - loss: 0.2253 - acc: 0.9185 - val_loss: 0.2520 - val_acc: 0.8970
Epoch 10/30
2000/2000 [==============================] - 1s 269us/step - loss: 0.2114 - acc: 0.9235 - val_loss: 0.2732 - val_acc: 0.8770
Epoch 11/30
2000/2000 [==============================] - 1s 280us/step - loss: 0.1966 - acc: 0.9290 - val_loss: 0.2469 - val_acc: 0.9020
Epoch 12/30
2000/2000 [==============================] - 1s 290us/step - loss: 0.1881 - acc: 0.9370 - val_loss: 0.2551 - val_acc: 0.8990
Epoch 13/30
2000/2000 [==============================] - 1s 274us/step - loss: 0.1792 - acc: 0.9410 - val_loss: 0.2534 - val_acc: 0.8960
Epoch 14/30
2000/2000 [==============================] - 1s 271us/step - loss: 0.1778 - acc: 0.9385 - val_loss: 0.2378 - val_acc: 0.9060
Epoch 15/30
2000/2000 [==============================] - 1s 278us/step - loss: 0.1672 - acc: 0.9410 - val_loss: 0.2442 - val_acc: 0.9040
Epoch 16/30
2000/2000 [==============================] - 1s 277us/step - loss: 0.1584 - acc: 0.9470 - val_loss: 0.2364 - val_acc: 0.9080
Epoch 17/30
2000/2000 [==============================] - 1s 276us/step - loss: 0.1494 - acc: 0.9455 - val_loss: 0.2349 - val_acc: 0.9080
Epoch 18/30
2000/2000 [==============================] - 1s 280us/step - loss: 0.1448 - acc: 0.9490 - val_loss: 0.2338 - val_acc: 0.9080
Epoch 19/30
2000/2000 [==============================] - 1s 276us/step - loss: 0.1401 - acc: 0.9525 - val_loss: 0.2347 - val_acc: 0.9060
Epoch 20/30
2000/2000 [==============================] - 1s 290us/step - loss: 0.1299 - acc: 0.9575 - val_loss: 0.2357 - val_acc: 0.9050
Epoch 21/30
2000/2000 [==============================] - 1s 278us/step - loss: 0.1241 - acc: 0.9590 - val_loss: 0.2404 - val_acc: 0.9040
Epoch 22/30
2000/2000 [==============================] - 1s 279us/step - loss: 0.1214 - acc: 0.9585 - val_loss: 0.2359 - val_acc: 0.9060
Epoch 23/30
2000/2000 [==============================] - 1s 290us/step - loss: 0.1166 - acc: 0.9625 - val_loss: 0.2371 - val_acc: 0.9050
Epoch 24/30
2000/2000 [==============================] - 1s 290us/step - loss: 0.1122 - acc: 0.9650 - val_loss: 0.2352 - val_acc: 0.9040
Epoch 25/30
2000/2000 [==============================] - 1s 286us/step - loss: 0.1052 - acc: 0.9675 - val_loss: 0.2450 - val_acc: 0.9030
Epoch 26/30
2000/2000 [==============================] - 1s 277us/step - loss: 0.1029 - acc: 0.9700 - val_loss: 0.2380 - val_acc: 0.9070
Epoch 27/30
2000/2000 [==============================] - 1s 284us/step - loss: 0.0988 - acc: 0.9675 - val_loss: 0.2487 - val_acc: 0.9030
Epoch 28/30
2000/2000 [==============================] - 1s 279us/step - loss: 0.0966 - acc: 0.9640 - val_loss: 0.2370 - val_acc: 0.9060
Epoch 29/30
2000/2000 [==============================] - 1s 276us/step - loss: 0.0899 - acc: 0.9690 - val_loss: 0.2378 - val_acc: 0.9030
Epoch 30/30
2000/2000 [==============================] - 1s 279us/step - loss: 0.0881 - acc: 0.9700 - val_loss: 0.2424 - val_acc: 0.9070
- 학습이 완료되었으니 결과를 한 번 보도록 하죠.
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
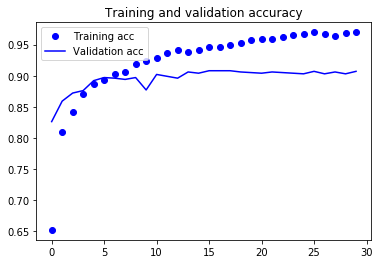
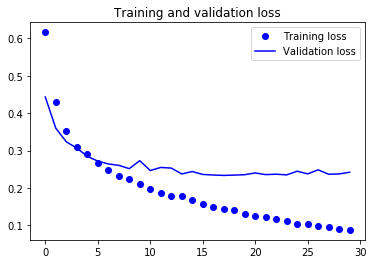
- 90% 정도의 검증 정확도에 도달했으나 많은 비율로 드롭아웃을 사용했음에도 불구하고 훈련이 시작하면서 거의 바로 과대적합되고 있습니다.
- 이를 개선하기 위해서 Data Augmentation을 사용해 보도록 하겠습니다.
1.2. 방법 #01-02
- ImageDataGenerator를 사용하여 Data Augmentation을 이용해 보도록 하겠습니다.
-
전체 Network을 다 실행해야합니다.
- 방법 #01-01에 Data Augmentation을 사용하면 안될까요 ??
- Data Augmentation을 사용하려면 ImageDataGenerator를 사용해야 하고, ImageDataGenerator를 사용하려면 fit_generator를 호출해야
합니다. - fit_generator를 호출하면 전체 Network을 다 Train해야합니다..
- Data Augmentation을 사용하려면 ImageDataGenerator를 사용해야 하고, ImageDataGenerator를 사용하려면 fit_generator를 호출해야
- 새로운 Model을 정의하는데, 기존 Conv. Base에서 Dense Layer를 추가합니다.
from keras import models
from keras import layers
model = models.Sequential()
model.add(conv_base)
model.add(layers.Flatten())
model.add(layers.Dense(256, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
vgg16 (Model) (None, 4, 4, 512) 14714688
_________________________________________________________________
flatten_1 (Flatten) (None, 8192) 0
_________________________________________________________________
dense_3 (Dense) (None, 256) 2097408
_________________________________________________________________
dense_4 (Dense) (None, 1) 257
=================================================================
Total params: 16,812,353
Trainable params: 16,812,353
Non-trainable params: 0
_________________________________________________________________
print('conv_base를 동결하기 전 훈련되는 가중치의 수:',
len(model.trainable_weights))
conv_base를 동결하기 전 훈련되는 가중치의 수: 30
- Keras에서는 trainable 속성을 False로 설정하여 네트워크를 동결할 수 있습니다:
conv_base.trainable = False
print('conv_base를 동결한 후 훈련되는 가중치의 수:',
len(model.trainable_weights))
conv_base를 동결한 후 훈련되는 가중치의 수: 4
- 컴파일 단계 후에 trainable 속성을 변경하면 반드시 모델을 다시 컴파일해야 합니다. 그렇지 않으면 변경 사항이 적용되지 않습니다.
from keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=20,
width_shift_range=0.1,
height_shift_range=0.1,
shear_range=0.1,
zoom_range=0.1,
horizontal_flip=True,
fill_mode='nearest')
# 검증 데이터는 증식되어서는 안 됩니다!
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
# 타깃 디렉터리
train_dir,
# 모든 이미지의 크기를 150 × 150로 변경합니다
target_size=(150, 150),
batch_size=20,
# binary_crossentropy 손실을 사용하므로 이진 레이블이 필요합니다
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=2e-5),
metrics=['acc'])
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=30,
validation_data=validation_generator,
validation_steps=50,
verbose=2)
Found 2000 images belonging to 2 classes.
Found 1000 images belonging to 2 classes.
Epoch 1/30
- 14s - loss: 0.5165 - acc: 0.7575 - val_loss: 0.4247 - val_acc: 0.8170
Epoch 2/30
- 13s - loss: 0.3989 - acc: 0.8325 - val_loss: 0.3414 - val_acc: 0.8620
Epoch 3/30
- 12s - loss: 0.3424 - acc: 0.8625 - val_loss: 0.3006 - val_acc: 0.8740
Epoch 4/30
- 13s - loss: 0.3187 - acc: 0.8645 - val_loss: 0.2791 - val_acc: 0.8880
Epoch 5/30
- 13s - loss: 0.2934 - acc: 0.8775 - val_loss: 0.2657 - val_acc: 0.8940
Epoch 6/30
- 13s - loss: 0.2779 - acc: 0.8885 - val_loss: 0.2561 - val_acc: 0.8990
Epoch 7/30
- 12s - loss: 0.2802 - acc: 0.8830 - val_loss: 0.2554 - val_acc: 0.8970
Epoch 8/30
- 12s - loss: 0.2572 - acc: 0.8970 - val_loss: 0.2518 - val_acc: 0.9000
Epoch 9/30
- 12s - loss: 0.2544 - acc: 0.8955 - val_loss: 0.2613 - val_acc: 0.8860
Epoch 10/30
- 12s - loss: 0.2422 - acc: 0.9035 - val_loss: 0.2398 - val_acc: 0.9050
Epoch 11/30
- 12s - loss: 0.2439 - acc: 0.8935 - val_loss: 0.2417 - val_acc: 0.9040
Epoch 12/30
- 12s - loss: 0.2401 - acc: 0.9035 - val_loss: 0.2561 - val_acc: 0.9000
Epoch 13/30
- 12s - loss: 0.2354 - acc: 0.9055 - val_loss: 0.2369 - val_acc: 0.9010
Epoch 14/30
- 13s - loss: 0.2262 - acc: 0.9125 - val_loss: 0.2358 - val_acc: 0.9080
Epoch 15/30
- 13s - loss: 0.2311 - acc: 0.9025 - val_loss: 0.2349 - val_acc: 0.9030
Epoch 16/30
- 12s - loss: 0.2263 - acc: 0.9090 - val_loss: 0.2406 - val_acc: 0.9080
Epoch 17/30
- 12s - loss: 0.2114 - acc: 0.9215 - val_loss: 0.2346 - val_acc: 0.9080
Epoch 18/30
- 12s - loss: 0.2054 - acc: 0.9200 - val_loss: 0.2367 - val_acc: 0.9080
Epoch 19/30
- 12s - loss: 0.2038 - acc: 0.9225 - val_loss: 0.2397 - val_acc: 0.9070
Epoch 20/30
- 13s - loss: 0.2057 - acc: 0.9190 - val_loss: 0.2425 - val_acc: 0.8990
Epoch 21/30
- 13s - loss: 0.2065 - acc: 0.9175 - val_loss: 0.2429 - val_acc: 0.9000
Epoch 22/30
- 12s - loss: 0.2093 - acc: 0.9115 - val_loss: 0.2361 - val_acc: 0.9070
Epoch 23/30
- 12s - loss: 0.1982 - acc: 0.9195 - val_loss: 0.2333 - val_acc: 0.9070
Epoch 24/30
- 12s - loss: 0.1968 - acc: 0.9130 - val_loss: 0.2515 - val_acc: 0.8950
Epoch 25/30
- 12s - loss: 0.1952 - acc: 0.9245 - val_loss: 0.2321 - val_acc: 0.9050
Epoch 26/30
- 12s - loss: 0.1906 - acc: 0.9250 - val_loss: 0.2694 - val_acc: 0.8890
Epoch 27/30
- 12s - loss: 0.1899 - acc: 0.9235 - val_loss: 0.2349 - val_acc: 0.9090
Epoch 28/30
- 12s - loss: 0.1876 - acc: 0.9265 - val_loss: 0.2399 - val_acc: 0.9060
Epoch 29/30
- 12s - loss: 0.1777 - acc: 0.9310 - val_loss: 0.2390 - val_acc: 0.9040
Epoch 30/30
- 12s - loss: 0.1824 - acc: 0.9260 - val_loss: 0.2358 - val_acc: 0.9060
- Train이 완료되었으면 일단 저장해 놓습니다.
model.save('cats_and_dogs_small_3.h5')
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
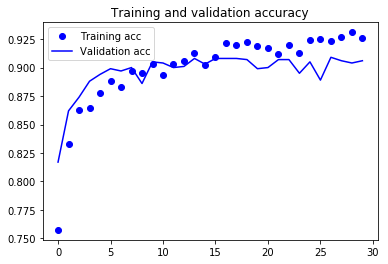
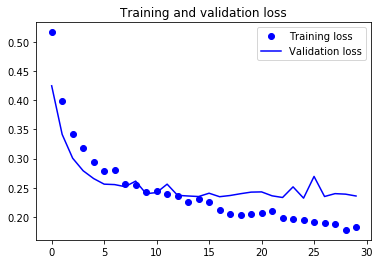
- 정확도가 이전과 비슷하지만 처음부터 훈련시킨 소규모 컨브넷보다 과대적합이 줄었습니다
1.3. 방법 #02 - 미세조정
- Feature Extract에 사용했던 모델의 상위 층 몇 개를 동결에서 해제하고 모델에 새로 추가한 층( FC )과 함께 훈련하는 방식입니다.
- 주어진 문제에 조금 더 밀접하게 재사용 모델의 표현을 일부 조정하기 때문에 미세 조정이라고 부릅니다.
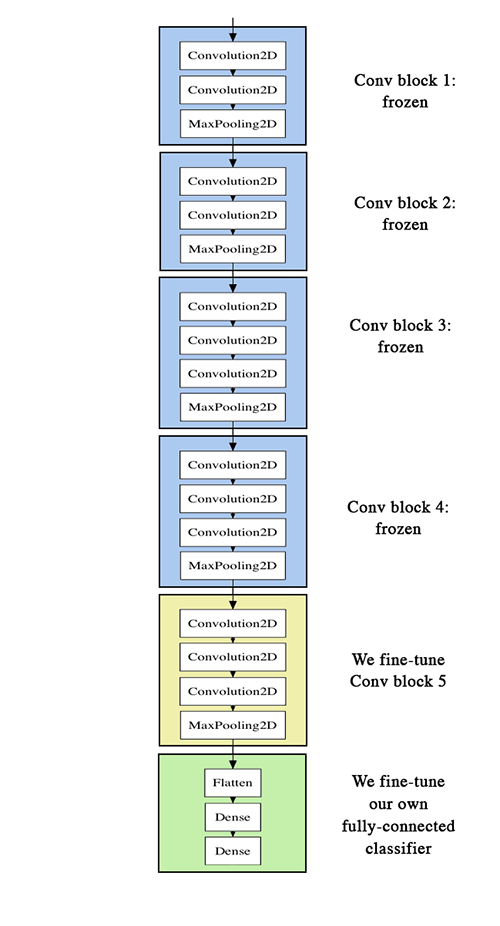
- 앞선 방법에서는 마지막 FC만 학습하고 나머지 VGG Model은 Trainable = false로 했습니다.
- 이번 방법에서는 기존 VGG 마지막 Conv. Layer만 동결해제 합니다.
네트워크를 미세 조정하는 단계는 다음과 같습니다:
- 사전에 훈련된 기반 네트워크 위에 새로운 네트워크를 추가합니다.
- 기반 네트워크를 동결합니다.
- 새로 추가한 네트워크를 훈련합니다.
- 기반 네트워크에서 일부 층의 동결을 해제합니다.
- 동결을 해제한 층과 새로 추가한 층을 함께 훈련합니다.
처음 세 단계는 특성 추출을 할 때 이미 완료했고, 네 번째 단계를 진행해 보죠. conv_base의 동결을 해제하고 개별 층을 동결하겠습니다.
conv_base.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 150, 150, 3) 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 150, 150, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 150, 150, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 75, 75, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 75, 75, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 75, 75, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 37, 37, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 37, 37, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 37, 37, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 37, 37, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 18, 18, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 18, 18, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 18, 18, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 18, 18, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 9, 9, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 4, 4, 512) 0
=================================================================
Total params: 14,714,688
Trainable params: 0
Non-trainable params: 14,714,688
_________________________________________________________________
-
마지막 세 개의 합성곱 층을 미세조정. 즉, block4_pool까지 모든 층은 동결하고 block5_conv1, block5_conv2, block5_conv3 층은 학습하도록 하겠습니다.
-
왜 더 많은 층을 미세 조정하지 않을까요?
- 합성곱 기반층에 있는 하위 층들은 좀 더 일반적이고 재사용 가능한 특성들을 인코딩한다.
- 반면 상위 층은 좀 더 특화된 특성을 인코딩합니다.
- 새로운 문제에 재활용하도록 수정이 필요한 것은 구체적인 특성이므로 이들을 미세 조정하는 것이 유리합니다.
- 하위 층으로 갈수록 미세 조정에 대한 효과가 감소합니다.
- 훈련해야 할 파라미터가 많을수록 과대적합의 위험이 커집니다.
- 합성곱 기반층은 1천 5백만 개의 파라미터를 가지고 있고, 작은 데이터셋으로 전부 훈련하려고 하면 매우 위험합니다.
그러므로 이런 상황에서는 합성곱 기반층에서 최상위 두 세개의 층만 미세 조정하는 것이 좋습니다.
- block5_conv1 이후의 Layer는 동결하도록 하겠습니다.
conv_base.trainable = True
set_trainable = False
for layer in conv_base.layers:
if layer.name == 'block5_conv1':
set_trainable = True
if set_trainable:
layer.trainable = True
else:
layer.trainable = False
- Train을 시작합니다.
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-5),
metrics=['acc'])
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=100,
validation_data=validation_generator,
validation_steps=50)
Epoch 1/100
100/100 [==============================] - 14s 137ms/step - loss: 0.1813 - acc: 0.9255 - val_loss: 0.2593 - val_acc: 0.9000
Epoch 2/100
100/100 [==============================] - 13s 128ms/step - loss: 0.1533 - acc: 0.9430 - val_loss: 0.2473 - val_acc: 0.9080
Epoch 3/100
100/100 [==============================] - 13s 128ms/step - loss: 0.1373 - acc: 0.9450 - val_loss: 0.2697 - val_acc: 0.8930
Epoch 4/100
100/100 [==============================] - 13s 128ms/step - loss: 0.1190 - acc: 0.9535 - val_loss: 0.2574 - val_acc: 0.9010
Epoch 5/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0953 - acc: 0.9655 - val_loss: 0.1973 - val_acc: 0.9250
Epoch 6/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0770 - acc: 0.9705 - val_loss: 0.2241 - val_acc: 0.9260s - loss: - ETA: 3s - loss: 0.0793 - acc: - ETA: 2s - loss: 0.0859 - acc: - ETA: 2s - loss: 0.0853 - acc: - ETA: 1s - loss: 0.0
Epoch 7/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0851 - acc: 0.9650 - val_loss: 0.1914 - val_acc: 0.9260
Epoch 8/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0702 - acc: 0.9730 - val_loss: 0.2129 - val_acc: 0.9240757 - acc:
Epoch 9/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0565 - acc: 0.9790 - val_loss: 0.2240 - val_acc: 0.9260
Epoch 10/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0551 - acc: 0.9825 - val_loss: 0.2592 - val_acc: 0.9190
Epoch 11/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0481 - acc: 0.9830 - val_loss: 0.2330 - val_acc: 0.9340
Epoch 12/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0453 - acc: 0.9835 - val_loss: 0.2633 - val_acc: 0.91500434 -
Epoch 13/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0381 - acc: 0.9860 - val_loss: 0.2258 - val_acc: 0.9200
Epoch 14/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0404 - acc: 0.9860 - val_loss: 0.2146 - val_acc: 0.9330
Epoch 15/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0278 - acc: 0.9925 - val_loss: 0.3402 - val_acc: 0.9140A: 2s - loss
Epoch 16/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0328 - acc: 0.9875 - val_loss: 0.2362 - val_acc: 0.9260
Epoch 17/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0272 - acc: 0.9895 - val_loss: 0.2303 - val_acc: 0.9350
Epoch 18/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0311 - acc: 0.9900 - val_loss: 0.2423 - val_acc: 0.9300
Epoch 19/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0167 - acc: 0.9950 - val_loss: 0.2193 - val_acc: 0.9380ETA: 2
Epoch 20/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0309 - acc: 0.9915 - val_loss: 0.2480 - val_acc: 0.9310 7s - loss: 0.0265 - ETA: 6s - loss: 0.0371 - acc: 0 - ETA: 5s - loss: 0.0562 - - ETA: 4s - loss: - ETA: 2s - loss: 0.0364 - acc: - ETA: 2s - loss: 0 - ETA: 0s - loss: 0.0325 - acc: 0.990 - ETA: 0s - loss: 0.0323 - acc:
Epoch 21/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0160 - acc: 0.9950 - val_loss: 0.2892 - val_acc: 0.9220
Epoch 22/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0217 - acc: 0.9935 - val_loss: 0.3709 - val_acc: 0.9100
Epoch 23/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0238 - acc: 0.9910 - val_loss: 0.2201 - val_acc: 0.9390
Epoch 24/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0167 - acc: 0.9940 - val_loss: 0.2208 - val_acc: 0.9360
Epoch 25/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0209 - acc: 0.9930 - val_loss: 0.2692 - val_acc: 0.9320 - loss: 0.0209 -
Epoch 26/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0165 - acc: 0.9950 - val_loss: 0.2837 - val_acc: 0.9300
Epoch 27/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0135 - acc: 0.9940 - val_loss: 0.2806 - val_acc: 0.9250
Epoch 28/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0070 - acc: 0.9985 - val_loss: 0.2602 - val_acc: 0.9330
Epoch 29/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0168 - acc: 0.9935 - val_loss: 0.2746 - val_acc: 0.9260
Epoch 30/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0238 - acc: 0.9930 - val_loss: 0.3045 - val_acc: 0.9250
Epoch 31/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0135 - acc: 0.9950 - val_loss: 0.2851 - val_acc: 0.9210
Epoch 32/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0073 - acc: 0.9975 - val_loss: 0.3244 - val_acc: 0.9230 ETA: 4s - loss: 0.0041 - a
Epoch 33/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0150 - acc: 0.9955 - val_loss: 0.2884 - val_acc: 0.9350
Epoch 34/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0131 - acc: 0.9945 - val_loss: 0.3464 - val_acc: 0.9190
Epoch 35/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0088 - acc: 0.9980 - val_loss: 0.2882 - val_acc: 0.9340
Epoch 36/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0091 - acc: 0.9975 - val_loss: 0.3254 - val_acc: 0.9290
Epoch 37/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0061 - acc: 0.9985 - val_loss: 0.3295 - val_acc: 0.9310
Epoch 38/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0130 - acc: 0.9960 - val_loss: 0.3055 - val_acc: 0.93200.0087 - acc: - ETA: 0s - loss: 0.0131 - acc: 0.996
Epoch 39/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0047 - acc: 0.9990 - val_loss: 0.2662 - val_acc: 0.9410
Epoch 40/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0106 - acc: 0.9965 - val_loss: 0.2971 - val_acc: 0.9310
Epoch 41/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0069 - acc: 0.9980 - val_loss: 0.3663 - val_acc: 0.9110
Epoch 42/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0075 - acc: 0.9980 - val_loss: 0.2408 - val_acc: 0.9390
Epoch 43/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0077 - acc: 0.9975 - val_loss: 0.3169 - val_acc: 0.92900.99
Epoch 44/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0044 - acc: 0.9990 - val_loss: 0.3122 - val_acc: 0.9260 loss: 0.0046 - acc:
Epoch 45/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0057 - acc: 0.9985 - val_loss: 0.2893 - val_acc: 0.9360- loss: 0.0064
Epoch 46/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0085 - acc: 0.9965 - val_loss: 0.7179 - val_acc: 0.8810
Epoch 47/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0101 - acc: 0.9970 - val_loss: 0.4235 - val_acc: 0.9240
Epoch 48/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0119 - acc: 0.9970 - val_loss: 0.2666 - val_acc: 0.9340
Epoch 49/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0024 - acc: 0.9995 - val_loss: 0.3485 - val_acc: 0.9310
Epoch 50/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0048 - acc: 0.9980 - val_loss: 0.3051 - val_acc: 0.9340
Epoch 51/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0076 - acc: 0.9975 - val_loss: 0.3027 - val_acc: 0.9240047 - acc: 0.9 - ETA: 5s - loss:
Epoch 52/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0030 - acc: 0.9990 - val_loss: 0.3273 - val_acc: 0.9260
Epoch 53/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0042 - acc: 0.9985 - val_loss: 0.3460 - val_acc: 0.9270
Epoch 54/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0018 - acc: 0.9995 - val_loss: 0.3755 - val_acc: 0.9310- ETA: 1s - loss: 0.0019 -
Epoch 55/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0040 - acc: 0.9990 - val_loss: 0.3012 - val_acc: 0.9410
Epoch 56/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0041 - acc: 0.9985 - val_loss: 0.3481 - val_acc: 0.9320oss: 0.0044 - acc:
Epoch 57/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0058 - acc: 0.9980 - val_loss: 0.2842 - val_acc: 0.9360
Epoch 58/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0051 - acc: 0.9980 - val_loss: 0.3516 - val_acc: 0.9360
Epoch 59/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0022 - acc: 1.0000 - val_loss: 0.3672 - val_acc: 0.9250
Epoch 60/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0043 - acc: 0.9975 - val_loss: 0.3058 - val_acc: 0.9390
Epoch 61/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0051 - acc: 0.9980 - val_loss: 0.3159 - val_acc: 0.9350
Epoch 62/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0045 - acc: 0.9990 - val_loss: 0.3732 - val_acc: 0.9300
Epoch 63/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0026 - acc: 0.9985 - val_loss: 0.3657 - val_acc: 0.9290- ETA: 0s - loss: 0.0026 - acc: 0
Epoch 64/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0015 - acc: 0.9995 - val_loss: 0.2992 - val_acc: 0.9500
Epoch 65/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0027 - acc: 0.9990 - val_loss: 0.4004 - val_acc: 0.9210
Epoch 66/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0016 - acc: 0.9995 - val_loss: 0.4355 - val_acc: 0.9290
Epoch 67/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0022 - acc: 0.9990 - val_loss: 0.3004 - val_acc: 0.9460
Epoch 68/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0033 - acc: 0.9995 - val_loss: 0.3708 - val_acc: 0.9350
Epoch 69/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0083 - acc: 0.9980 - val_loss: 0.3919 - val_acc: 0.9250
Epoch 70/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0043 - acc: 0.9990 - val_loss: 0.4616 - val_acc: 0.9170TA: 2s - lo
Epoch 71/100
100/100 [==============================] - 13s 127ms/step - loss: 0.0034 - acc: 0.9980 - val_loss: 0.3611 - val_acc: 0.9340 ETA: 2s - loss: 0. - ETA: 0s - loss: 0.0036 - acc: 0
Epoch 72/100
100/100 [==============================] - 13s 127ms/step - loss: 0.0028 - acc: 0.9990 - val_loss: 0.4096 - val_acc: 0.9210
Epoch 73/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0049 - acc: 0.9980 - val_loss: 0.3963 - val_acc: 0.9300
Epoch 74/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0037 - acc: 0.9995 - val_loss: 0.3567 - val_acc: 0.9330 1s - loss: 0.0042 -
Epoch 75/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0012 - acc: 1.0000 - val_loss: 0.3776 - val_acc: 0.9340
Epoch 76/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0034 - acc: 0.9990 - val_loss: 0.3662 - val_acc: 0.9390
Epoch 77/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0024 - acc: 0.9990 - val_loss: 0.5282 - val_acc: 0.9280
Epoch 78/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0028 - acc: 0.9995 - val_loss: 0.4118 - val_acc: 0.9350
Epoch 79/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0131 - acc: 0.9975 - val_loss: 0.4383 - val_acc: 0.9290
Epoch 80/100
100/100 [==============================] - 13s 127ms/step - loss: 0.0020 - acc: 0.9990 - val_loss: 0.4570 - val_acc: 0.9320
Epoch 81/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0029 - acc: 0.9985 - val_loss: 0.5011 - val_acc: 0.9220
Epoch 82/100
100/100 [==============================] - 13s 127ms/step - loss: 0.0025 - acc: 0.9985 - val_loss: 0.5921 - val_acc: 0.9090
Epoch 83/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0046 - acc: 0.9985 - val_loss: 0.4468 - val_acc: 0.9280
Epoch 84/100
100/100 [==============================] - 13s 128ms/step - loss: 1.3392e-04 - acc: 1.0000 - val_loss: 0.2831 - val_acc: 0.9480
Epoch 85/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0029 - acc: 0.9985 - val_loss: 0.4810 - val_acc: 0.9280
Epoch 86/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0128 - acc: 0.9975 - val_loss: 0.4014 - val_acc: 0.9330
Epoch 87/100
100/100 [==============================] - 13s 127ms/step - loss: 9.7576e-04 - acc: 0.9995 - val_loss: 0.3834 - val_acc: 0.9380
Epoch 88/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0023 - acc: 0.9990 - val_loss: 0.3717 - val_acc: 0.9320
Epoch 89/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0049 - acc: 0.9980 - val_loss: 0.4039 - val_acc: 0.9290
Epoch 90/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0029 - acc: 0.9990 - val_loss: 0.3495 - val_acc: 0.9450
Epoch 91/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0030 - acc: 0.9980 - val_loss: 0.3481 - val_acc: 0.9380
Epoch 92/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0025 - acc: 0.9985 - val_loss: 0.4316 - val_acc: 0.9260oss: 0.0026 - acc: 0
Epoch 93/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0025 - acc: 0.9985 - val_loss: 0.3484 - val_acc: 0.9380
Epoch 94/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0059 - acc: 0.9975 - val_loss: 0.3907 - val_acc: 0.9320
Epoch 95/100
100/100 [==============================] - 13s 128ms/step - loss: 7.1898e-04 - acc: 1.0000 - val_loss: 0.6235 - val_acc: 0.9080
Epoch 96/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0029 - acc: 0.9995 - val_loss: 0.4184 - val_acc: 0.9250
Epoch 97/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0024 - acc: 0.9990 - val_loss: 0.3732 - val_acc: 0.9300
Epoch 98/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0026 - acc: 0.9985 - val_loss: 0.4068 - val_acc: 0.9390
Epoch 99/100
100/100 [==============================] - 13s 128ms/step - loss: 7.8065e-04 - acc: 1.0000 - val_loss: 0.3804 - val_acc: 0.9290
Epoch 100/100
100/100 [==============================] - 13s 128ms/step - loss: 0.0018 - acc: 0.9985 - val_loss: 0.3999 - val_acc: 0.9300
- Validation Set에서 정확도가 93%정도 되네요.
model.save('cats_and_dogs_small_4.h5')
- 자, 이제 결과를 그래프로 그려보도록 하겠습니다.
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
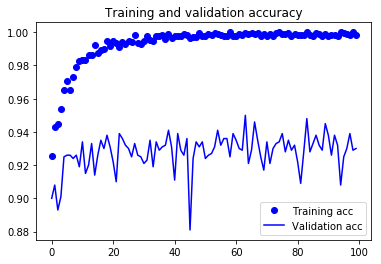
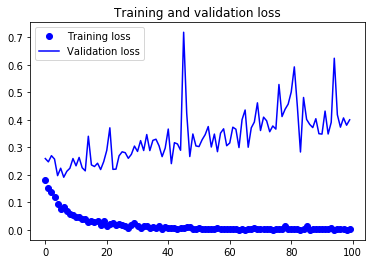
2. Test Set으로 검증
test_generator = test_datagen.flow_from_directory(
test_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
test_loss, test_acc = model.evaluate_generator(test_generator, steps=50)
print('test acc:', test_acc)
Found 1000 images belonging to 2 classes.
test acc: 0.9409999907016754
- Test Set에서의 정확도는 94% 까지 올라갔네요.