CNN( Convolutional Neural Network )
CNN ( Convolutional Neural Network )
순서
1. CNN Introduction
2. Terminology
3. Basic Codes & Exercise
4 Pre-Trained Models
1. CNN Introduction
1.1. 시각적 인식
- 시각적 인식은 어떻게 이루어 지는가 ?
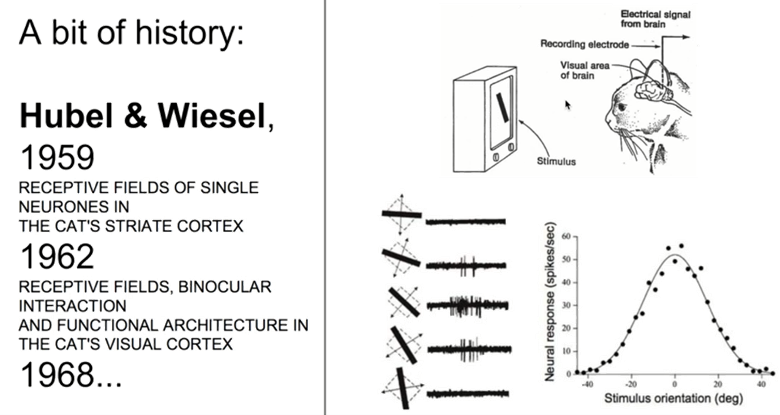
• 고양이의 머리에 전극을 연결 후, 시각 자극에 대한 뇌의 신경들이 어떻게 반응하는지 관찰
• 관찰 결과
- 특정 자극에만 반응하는 특정 뉴런 존재
- 자극은 여러 과정을 거치면서 단순한 형태에서 점점 복잡한 형태( 추상적 )로 지각된다.
→ CNN 의 이론적 토대

1.2. CNN( Convolution Neural Network )
-
Deep Neural Network의 한 종류로써, 하나 또는 여러 개의 Convolution Layer와 Pooling Layer, Fully Connected Layer등으로 구성된 Image 분석에 특화된 신경망
- Convolution의 수학적 정의
- 수학적으로 Convolution이란 두 함수를 이용해 다른 함수에 의해 해당 함수의 모양이 변화되는 새로운 함수를 생성하는 것
- 기존 Image Data에 어떤 연산을 하여 새로운 Data를 만든다.

1.3. Fully Connected vs CNN
- FC( Fully Connected ) Layer ?
- FC란 다음과 같이 개별적인 값을 Network의 Input으로 사용하는 Layer를 말한다.

- FC vs CNN
- Fully Connected Layer로 구성된 인공 신경망의 입력 데이터는 1차원(배열) 형태가 되어야 한다.
- 한 장의 컬러 사진은 3차원 데이터(Height , Width , Color )로 구성되어 있다.
- 사진 데이터를 Fully Connected 신경망을 학습시켜야 할 경우에, 3차원 사진 데이터를 1차원으로 평면화시켜야 한다.
- 사진 데이터를 평면화 시키는 과정에서 공간 정보가 손실될 수밖에 없다.
- 결과적으로 Image 공간 정보 유실로 인한 정보 부족으로 인공 신경망이 특징을 추출 및 학습이 비효율, 정확도를 높이는데 한계가 있다.
- Image의 공간 정보를 유지한 상태로 학습이 가능한 모델이 바로 CNN(Convolutional Neural Network)입니다.
1.4. CNN의 특징
- 각 Layer의 입출력 데이터의 형상 유지
- Image의 공간 정보를 유지하면서 인접 Image와의 특징을 효과적으로 인식
- 복수의 Filter로 Image 의 특징 추출 및 학습
- 추출한 Image 의 특징을 모으고 강화하는 Pooling Layer
- Filter를 공유 Parameter로 사용하기 때문에, 일반 Neural Net.과 비교하여 학습 Parameter가 매우 적음
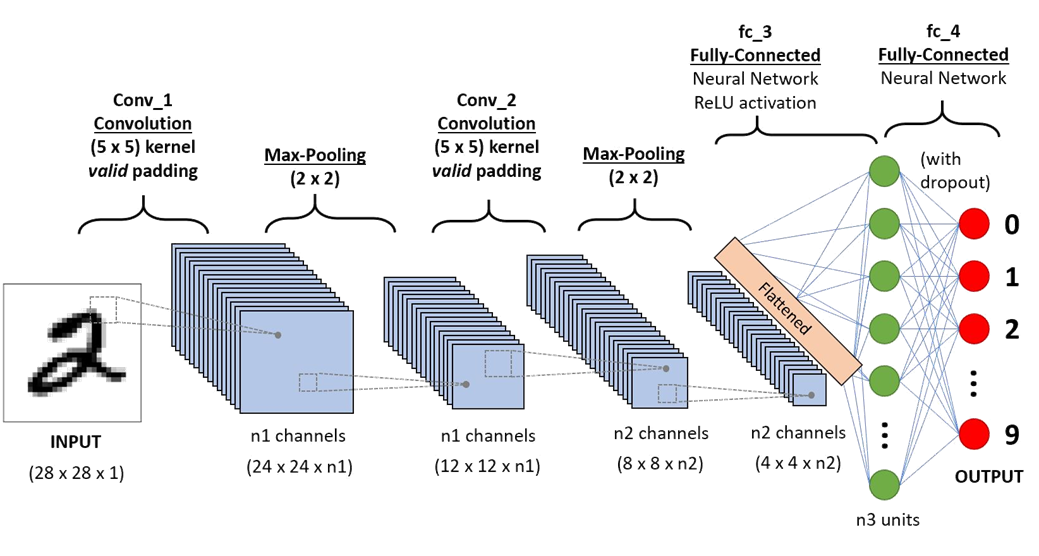
1.5. Simple CNN Example
- 아래 그림은 CNN의 가장 전형적인 구조를 보여줍니다.

2. Terminology
2.1. Terminology
- Convolution
- Channel
- Filter ( Kernel )
- Stride
- Padding
- Feature Map( Activation Map )
- Pooling Layer
2.2. Channel
- 컬러 Image는 3개의 Channel로 구성
- 흑백 Image는 1개의 Channel

2.3. Filter( Kernel )
- Filter는 Image의 특징을 찾아내기 위한 공용 Parameter
- Filter는 일반적으로 (4, 4)이나 (3, 3)과 같은 정사각 행렬로 정의
- 입력 데이터를 지정된 간격(Stride)으로 순회하며 Channel별로 합성곱을 하고 모든 Channel(컬러의 경우 3개)의 합성곱의 합을 Feature Map생성
2.4. Application of Filter(Kernel)
- Image의 기하학적 정보를 추출한다


2.5. Stride
- 한번에 Filter가 움직이는 거리

2.6. Padding
- Filter를 적용할 수록 Image Size는 작아지고, 정보가 사라짐
- 모서리 부분의 Data를 살리고자 할 때
- 보통 0으로 채운다
- Size를 조절하는 기능이 외에, 외각을 “0”값으로 둘러싸는 특징으로 부터 인공 신경망이 Image의 외각을 인식하는 학습 효과도 있음

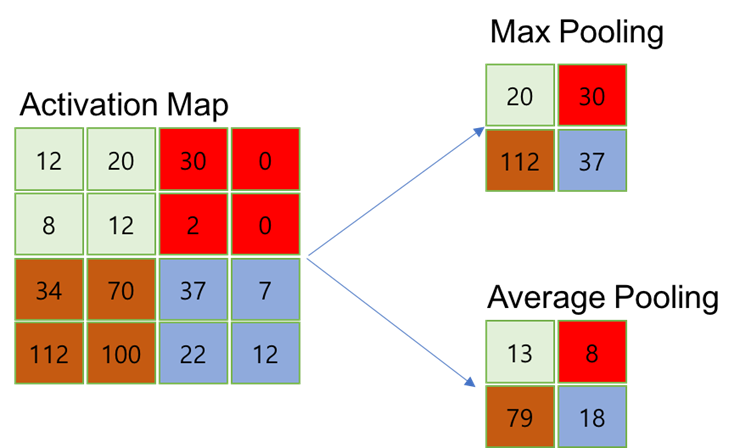
2.7. Pooling Layer
- Pooling Layer는 Conv. Layer의 출력 데이터를 입력으로 받아서 출력 데이터(Activation Map)의 크기를 줄이거나 특정 데이터를 강조하는 용도로 사용
- Pooling Layer를 처리하는 방법으로는 Max Pooling과 Average Pooning, Min Pooling이 있음
- 정사각 행렬의 특정 영역 안에 값의 최댓값을 모으거나 특정 영역의 평균을 구하는 방식으로 동작
2.8. CNN Training Process
- CNN Network이 Image를 학습하는 과정을 시각화한 자료입니다.
- 아래 Link를 참고하세요.

2.9. General Architecture of CNN
- CNN은 Convolution Layer와 Max Pooling Layer를 반복적으로 stack을 쌓는 특징 추출(Feature Extraction) 부분과 Fully Connected Layer를 구성하고 마지막 출력층에 Softmax를 적용한 분류 부분으로 나뉨
3. Basic Codes
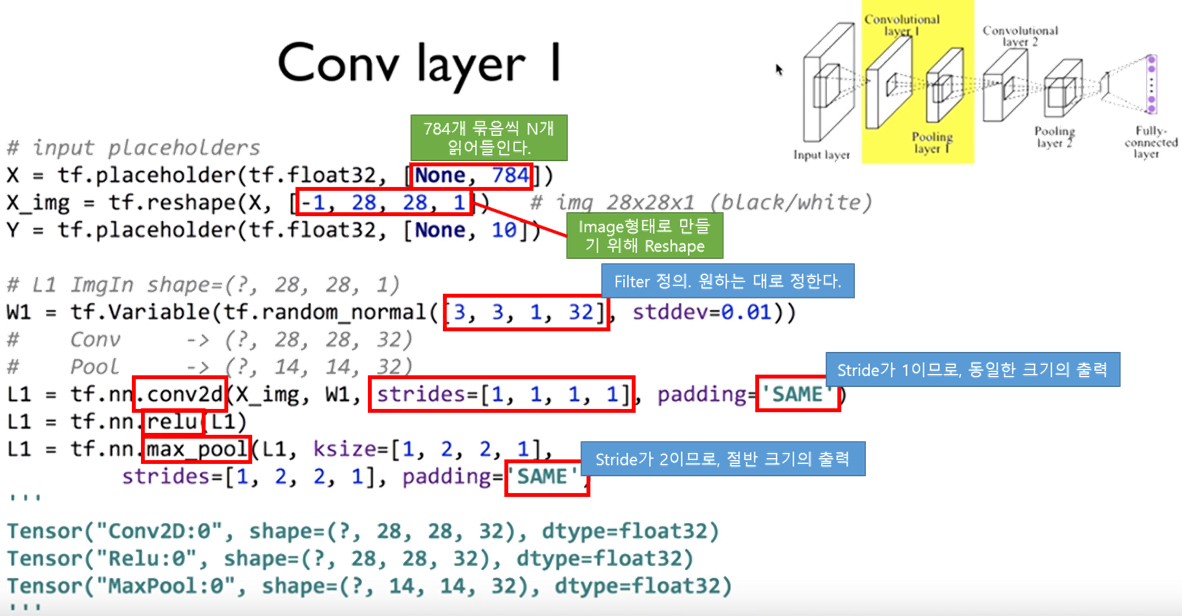
3.1. Basic Tensorflow Code
- 다음의 Example Code는 일반적인 Tensorflow Code를 이용한 CNN을 구현한 것입니다.
- 출처는 김훈님의 Deep Learning 강의입니다.



3.2. Basic Keras Code
- 다음의 Example Code는 일반적인 Keras Code를 이용한 CNN을 구현한 것입니다.
- Tensorflow Code보다 훨씬 간결하고 직관적이다.

3.3. General Process of CNN Model Training
- CNN Model Training 과정을 재밌게 시각화한 자료가 있어서 공유드립니다.
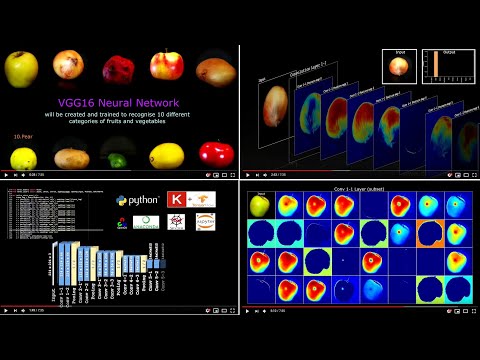
4. Pre-Trained Models
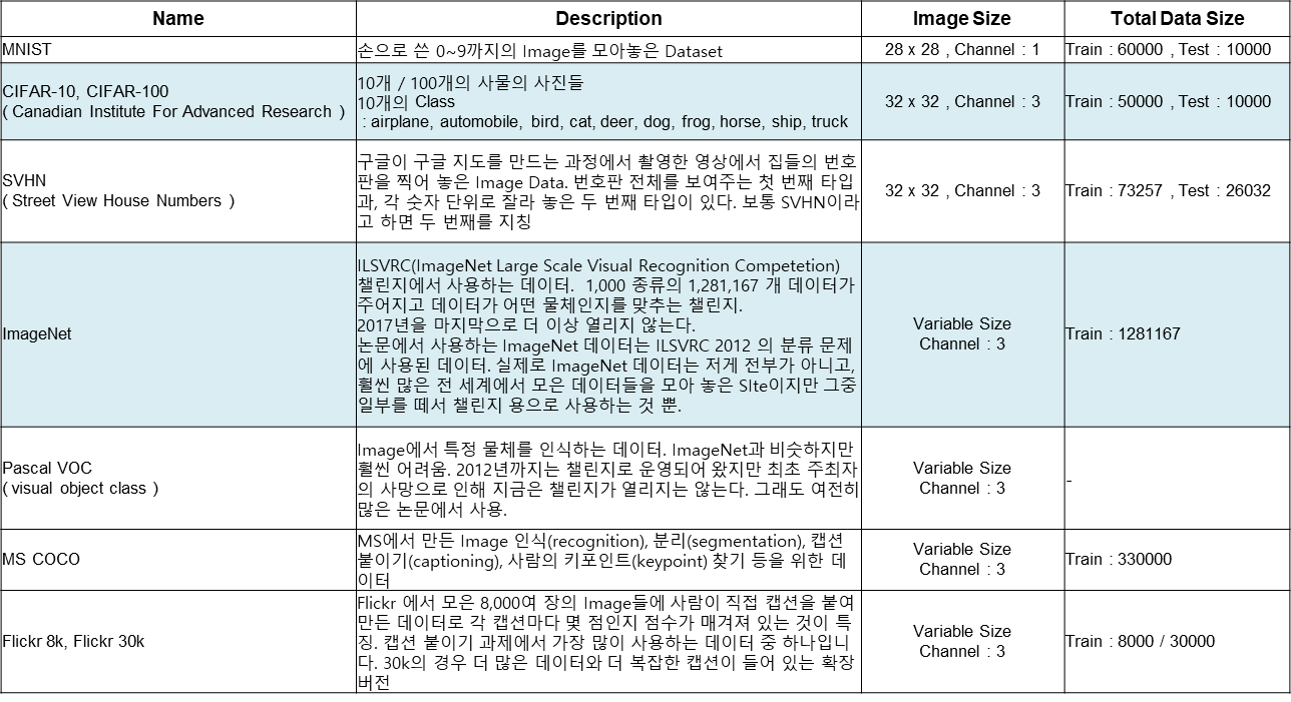
4.1. Image Dataset
- Image Train에 사용할 수 있도록 공개된 Training용 Image Data Set이 많이 있습니다.
- CNN Model에 관련된 자료를 보시다 보면, 자주 등장하는 Dataset에 대한 정보를 조사하였습니다.
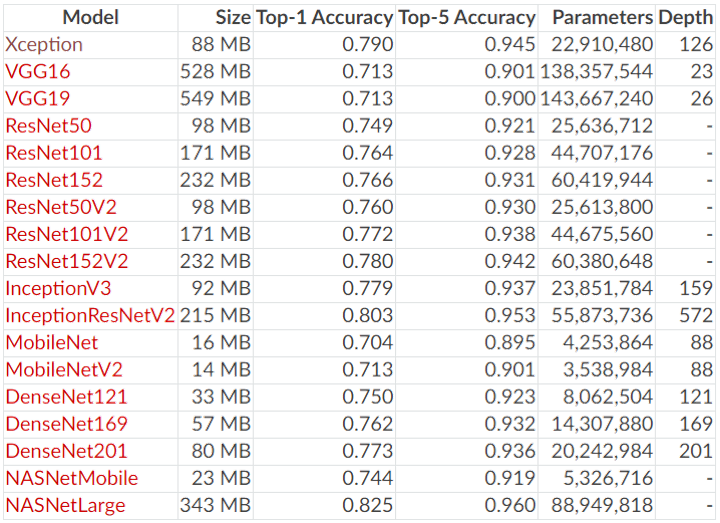
4.2. Pre-trained CNN Model in Keras
- Keras에서 제공하는 Pre-Trained Model의 종류는 다음과 같습니다.
- Top-1 Accuracy : Model이 분류한 결과중 가장 높은 확률 1개가 정답일 확률
- Top-5 Accuracy : Model이 분류한 결과중 가장 높은 확률 5개 중에 정답이 있을 확률
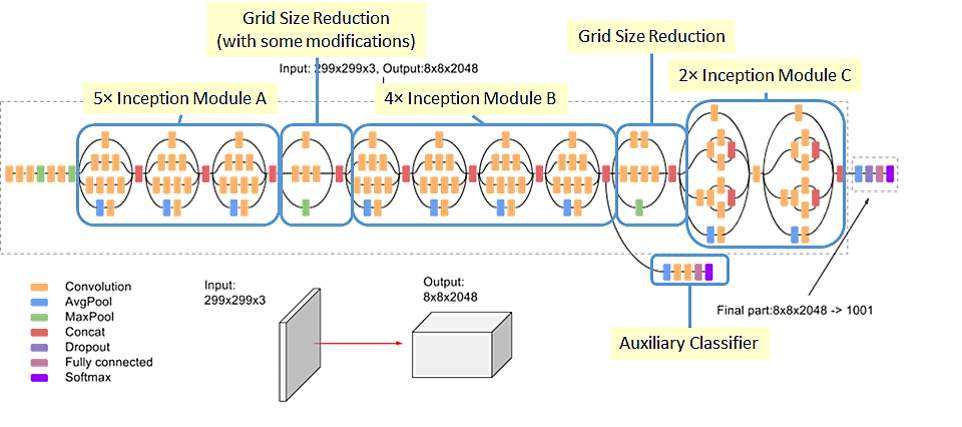
4.3. InceptionV3
- 자주 접할 수 있는 Pre-Trained Model중 하나인 InceptionV3의 구조입니다.
4.4. VGG16

4.5. ResNet
- Microsoft 북경 연구소 개발 ( Kaiming He , Xiangyu Zhang , Shaoqing Ren , Jian Sun )
- 논문 : https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/He_Deep_Residual_Learning_CVPR_2016_paper.pdf
층을 깊게 하면 무조건 성능이 좋아질까 ?

- Convolution Layer & Fully Connected Layer를 추가해 56 Layers & 20 Layers Model로 Test 진행
결과에서 보듯이 무조건 망을 깊게 하는 것이 능사가 아니다.
Degradation
- Neural Network은 Weight / Bias를 확률적 경사 하강법(stochastic gradient descent)을 통해 Update
- Gradient를 통해 Weight를 Update할 때, Gradient가 Explode or Vanishing 해버리는 경우 발생
-
https://dnddnjs.github.io/cifar10/2018/10/09/resnet/
- 이를 개선하기 위해서
- Xavier initialization / He initialization
- Batch Normalization (Sergey Ioffe & Christian Szegedy )
- Neural Network가 학습하기 어려운 이유를 internal covariate shift.
( Internal Covariate Shift : Neural Network가 학습하면서 각 층의 입력 분포가 계속 변하는 현상 ) - Mini-batch마다 각 층의 Input을 Normalization하는 방법으로 어느정도 해결했다.
- Batch normalization을 사용하면 initialization을 크게 신경쓰지 않아도 된다.
- Optimizer의 learning rate를 이전보다 더 높일 수 있다
- 일종의 Regularization 역할도 하기 때문에 Dropout을 사용하지 않아도 학습이 잘 되는 특성이 있다.
- 이 때부터 많은 neural Network에서 dropout을 사용하지 않기 시작했다.
- Neural Network가 학습하기 어려운 이유를 internal covariate shift.
- Highway Network
- Degradation 문제를 개선하기 위해 제안된 Network 구조. LSTM에 영감을 받음
• ResNet도 Highway Network과 마찬가지로 Degradation 문제를 개선하기 위해 제안된 Network 구조
( https://dnddnjs.github.io/cifar10/2018/10/09/resnet/ )
- 기존 CNN은 Input X를 Target에 Mapping 시키는 H(x)를 찾는 것이 목적 ( Direct Mapping )
- Residual은 일종의 오차.
-
Residual Learning은 Input으로부터 얼마만큼 달라져야 하는지를 학습.
- H(x)가 학습해야하는 Mapping이라면 H(x)를 H(x) = F(x) + x로 새롭게 정의.
- Neural Network 학습 목표를 H(x) 학습에서 F(x) 학습으로 변경
Shortcut Connection
- 몇 개의 layer를 건너뛰는 것(Skip)
- ResNet에서 Shortcut Connection은 2개의 Layer를 건너뛴다.
- Layer에 들어오는 입력이 Shortcut Connection을 통해서 건너뛰면 Layer를 지난 출력과 Element-Wise Addition 한다.

ResNet 구조
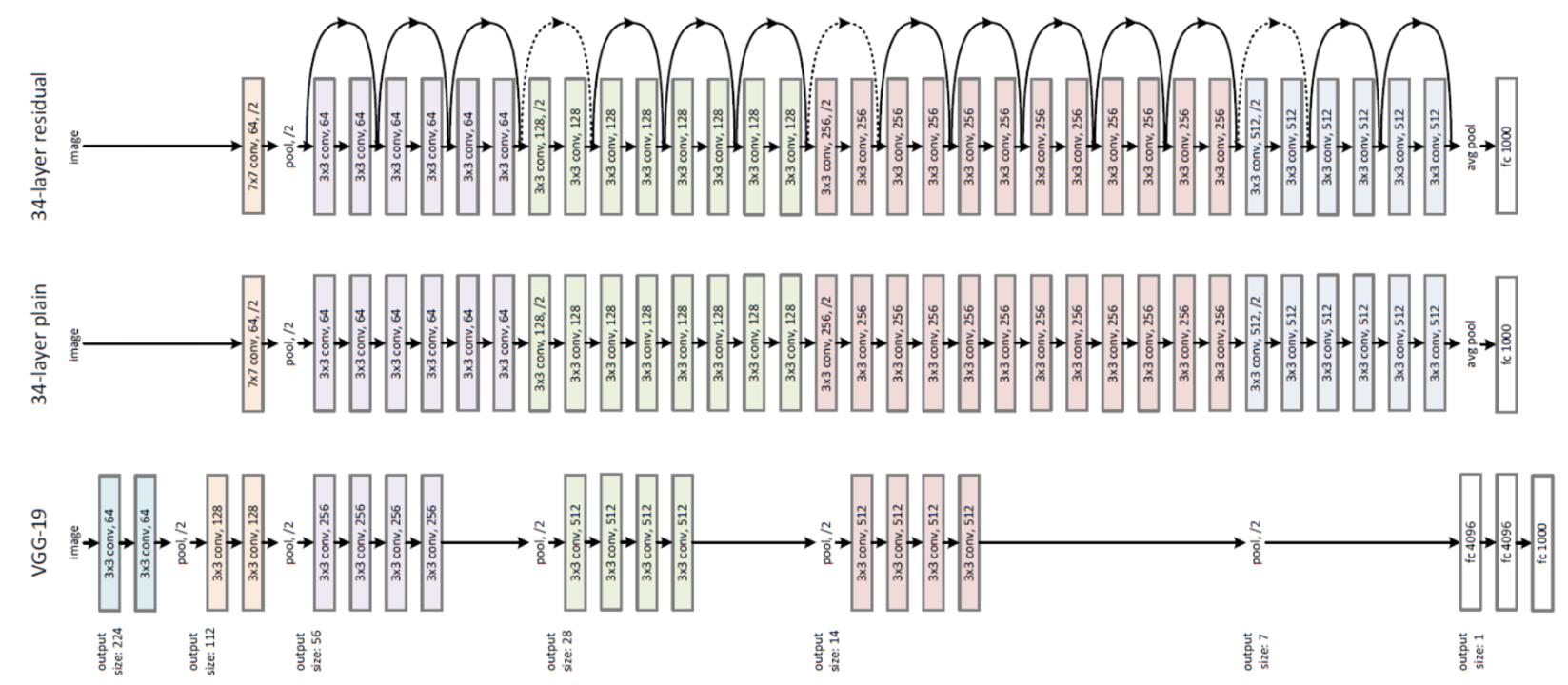
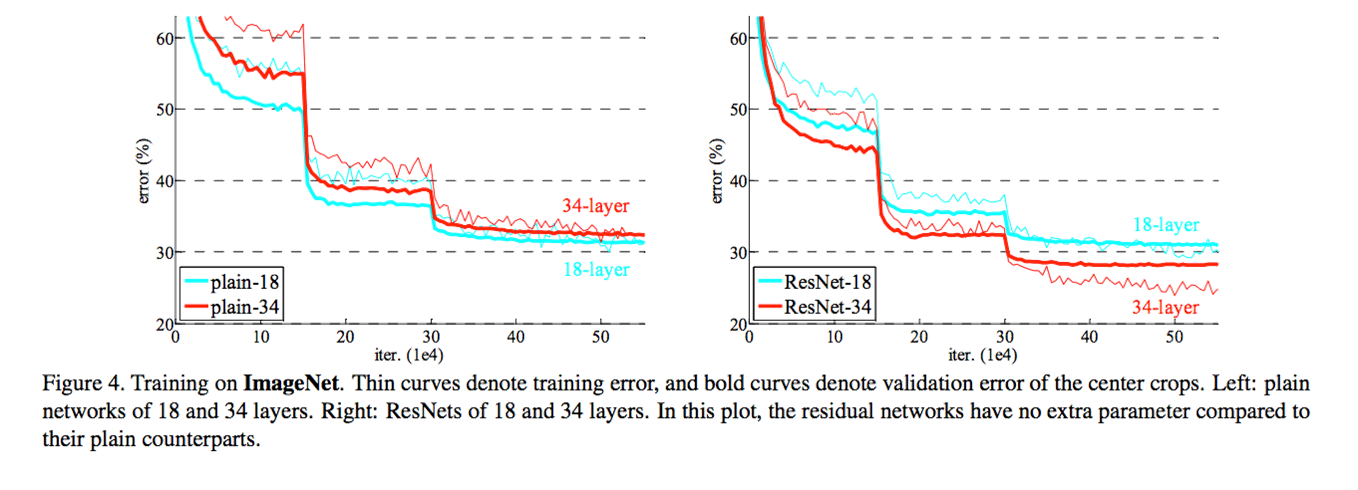
Test Result
- Left Graph : 일반 CNN 구조에서 34 Layer와 18 Layer의 Error Rate. 층이 깊을 수록 오히려 Error 증가
- Right Graph : ResNet 구조. 층이 깊을 수록 Error Rate 감소
- Layer를 극단적으로 깊게 하면 다시 Degradation 현상 발생

- Kaiming He - Identity Mappings in Deep Residual Networks 논문 발표
- 새로운 Residual Block 구조 제안
새로운 Residual Block 구조
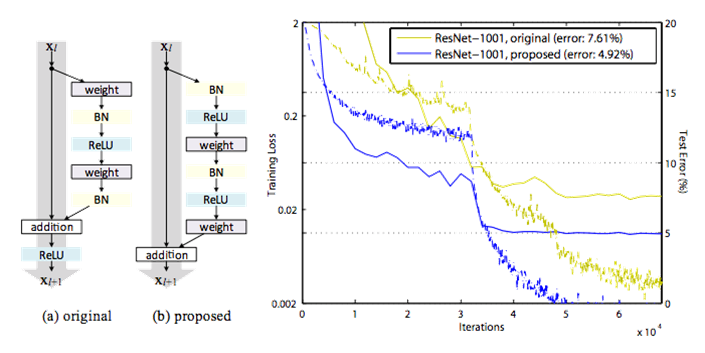
1) Optimization을 더 쉽게 해주었다. 위 학습 그래프를 보면 기존 ResNet보다 Pre-activation ResNet이 training loss가 더 빠르게 주는 것을 볼 수 있다.
이것은 기존 residual block에서는 ReLU 이후에 다음 residual block으로 넘어가기 때문에 back-propagation 할 때 ReLU에 의해 truncated 될 수 있기 때문이다.
하지만 새로운 residual unit에서는 back-propagation 할 때 identity에 대한 부분은 출력부분부터 입력부분까지 유지될 수가 있다. 따라서 좀 더 optimization이 쉬워진다. (기존 ResNet 또한 100 층 정도까지는 optimization에 어려움이 생기지는 않는다)
2) Batch-normalization으로 인한 regularization 효과 때문이다. 기존 Residual Block의 경우 BN을 한 이후에 identity mapping과 addition을 해주고 그 이후에 ReLU가 나온다.
따라서 Batch normalization의 regularization 효과를 충분히 보지 못한 것이다.
새로운 residual block에서는 Batch normalization 이후에 바로 ReLU가 나오므로 성능 개선의 여지가 있던 것이다.
4.6. NASNet
- 기존 NAS
- 강화학습 (RL, Reinforcement Learning) 기반 최적 Architecture를 찾는 연구
- Barret Zoph, Quoc V. Le, “Neural Architecture Search with reinforcement learning” (2017)
- Network의 Architecture를 결정하는 요소들 (Convolutional Layer , Filter Size, Stride 등)의 값을 예측하는 RNN Controller와 이 RNN Controller가 출력한 값들로 구성한 모델을 학습시켜 얻은 Validation Accuracy를 Reward로 하여 RNN Controller를 학습시키는 강화학습 모델로 구성
- 하나의 Dataset 전체를 학습한 다음 그 결과를 강화 학습 Reward로 이용하는 방식을 무수히 반복하여 최적의 Parameter를 찾는 방식
- CIFAR-10에 대해 최적의 모델을 찾기까지 800대의 최상급 GPU 를 사용하여 거의 한 달 소요.
- 이렇게 해서 찾은 모델은 ResNet보다는 좋은 성능을 보이고, DenseNet과는 거의 유사한 성능을 보이는 것을 확인
- CIFAR-10은 32 x 32이고, Dataset의 크기가 50000장 밖에 되지 않음.
- NAS방식을 ImageNet과 같은 대용량의 Dataset에 적용하기에는 현실적으로 매우 어려움
- 그러나, 강화학습을 기반으로 사람이 Design한 모델에 버금가는 모델을 찾을 수 있음을 보인 것 자체로 큰 의미를 가짐
- NASNet
- Barret Zoph, Vijay Vasudevan, Jonathon Shlens, Quoc V. Le , “Learning Transferable Architectures for Scalable Image Recognition”, 2018
- Transferable한 Architecture Search 방법론을 제안
- NAS와 다르게 Image Classification 을 위한 CNN 구조 탐색으로 범위를 한정
- 사람이 Design한 최고 Model에 버금가는 성능. NAS에 비해 학습 소요 시간도 단축(그래도 굉장히 길다)
- NAS : 800 GPU, 28 days (NVIDIA K40 GPU)
- NASNet : 500 GPU, 4days (NVIDIA P100s GPU)
- Search space의 변화 : 전체 Network를 학습하는 방법(NAS)대신, NASNet에서는 Convolution Cell이라는 단위로 학습을 진행
- Convolution Cell로 부터 Architecture를 생성하는 과정

-
NAS vs NASNet
- NAS Final Architecture
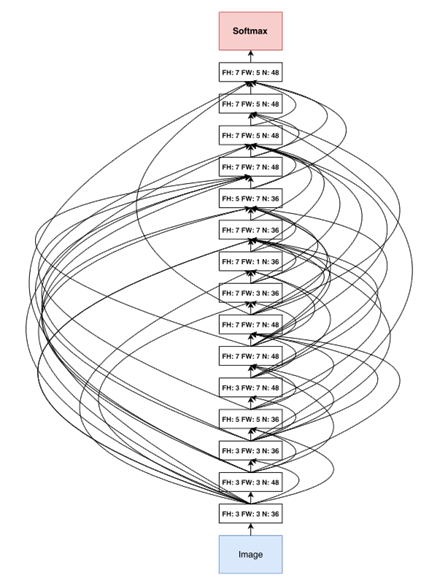
- NASNet-A Final Architecture
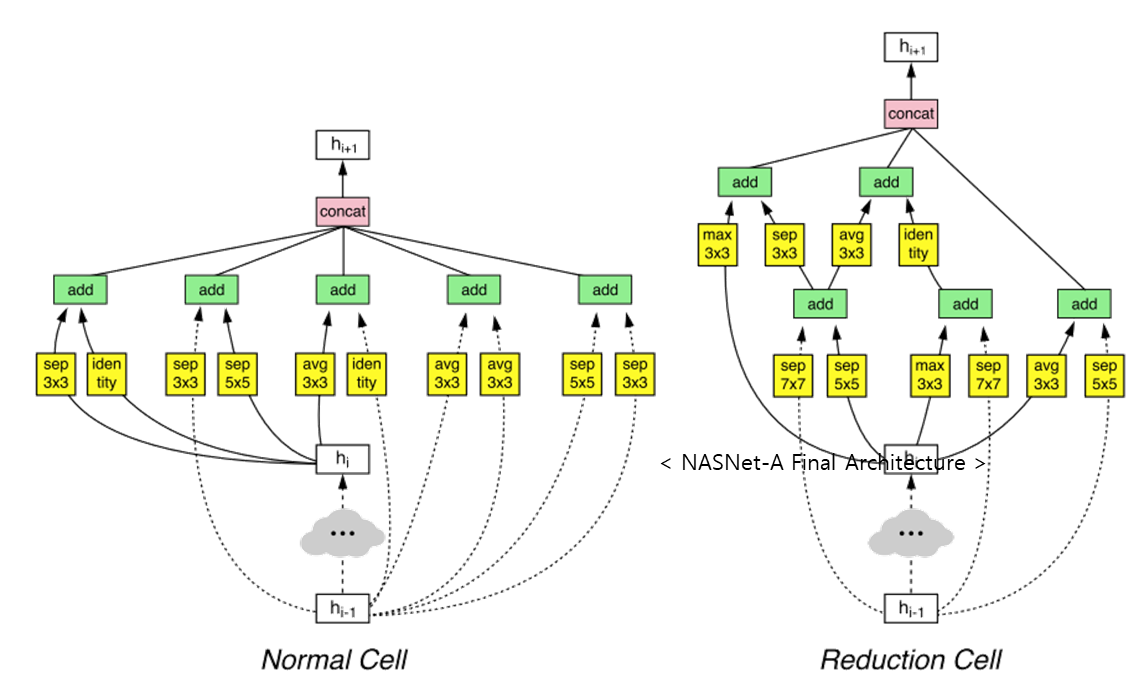
- 주로 사용하는 3x3 Convolution Filter는 3번밖에 쓰이지 않았고 5x5, 7x5, 5x7, 7x7 등 다양한 모양의 Convolution Filter를 사용
- 또한 Skip Connection이 굉장히 많으며 사람이 Design하기에는 다소 무리가 있을 정도로 불규칙성이 심한 것을 확인할 수 있습니다.

-
Transferability of NASNet
- Transfer Learning
-
Transfer learning is a machine learning method where a model developed for a task is reused as the starting point for a model on a second task.
-
It is a popular approach in deep learning where pre-trained models are used as the starting point on computer vision and natural language processing tasks given the vast compute and time resources required to develop neural network models on these problems and from the huge jumps in skill that they provide on related problems.
-
- 특정 Dataset에서 학습한 Model을 다른 Dataset에서도 사용하는 Training 방법
- Transfer Learning
- Transferability
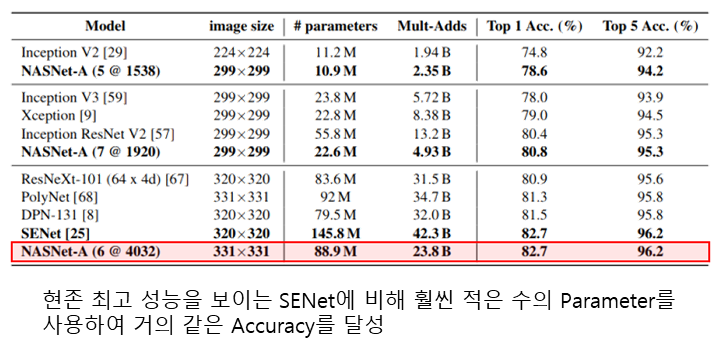
- CIFAR-10 Dataset으로 학습한 NASNet 구조를 ImageNet 분류에 그대로 적용
- http://research.sualab.com/review/2018/09/28/nasnet-review.html

- 후속 연구
- Architecture Search 분야. ENAS 라는 연구 결과를 제시
- Architecture Search에 걸리는 시간을 획기적으로 감소.
- 1대의 GPU로 거의 하루만에 Architecture를 찾을 수 있었으며 성능도 비교적 높게 측정되는 것을 확인
- 최적의 Optimizer, Activation function 등을 AutoML을 이용하여 찾는 연구도 진행
- Activation function은 기존에 자주 사용하던 ReLU와 그 변형된 function 대신 Swish라는 이름을 가진 f(x)=x⋅Sigmoid(βx) 함수를 AutoML을 통해 발견하였고, 이 함수를 사용하면 더 성능이 좋다고 설명
- 이 외에도 최근에는 augmentation에도 AutoML을 적용한 AutoAugment 논문
- Mobile device를 타겟으로 NAS를 적용한 MNASNet 논문 등 굉장히 다양한 연구들이 쏟아지고 있음.
- Architecture Search 분야. ENAS 라는 연구 결과를 제시
4.7. SENet ( Squeeze and Excitation Networks )
- https://jayhey.github.io/deep%20learning/2018/07/18/SENet/
- Hu, J., Shen, L., & Sun, G. (2017). Squeeze-and-excitation Networks
- CNN은 Convolution Filter가 Image or Feature Map의 “Local”을 학습
- Local Receptive Field에 있는 정보들의 조합.
- 이 조합들을 활성함수에 통과 후, 비선형적인 관계를 추론, Pooling과 같은 방법으로 큰 Feature들을 작게 만들어 한 번에 볼 수 있게 한다.
- 이런 식으로 CNN은 Global Receptive Field의 관계를 효율적으로 다루기 때문에 Image 분류와 같은 분야에서는 인간을 뛰어넘는 매우 훌륭한 성능을 낼 수 있다.
-
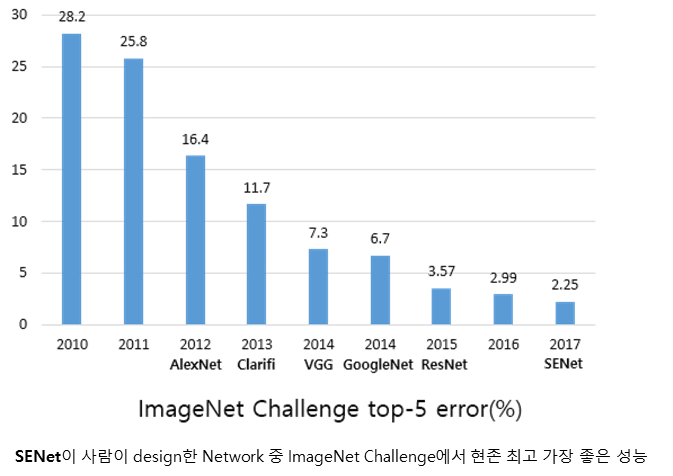
당연하게도 일반적인 CNN구조보다 효율적으로 피쳐들을 잘 다룰 수 있는 다양한 구조에 대한 연구가 있었고, 매년 ILSVRC에서 1등을 차지했습니다. ( GoogLeNet의 Inception module, ResNet의 Skip-connection, DenseNet의 Dense-connection )
- 논문의 저자들은 Squeeze-and-Excitation라는 방법을 적용해서 ILSVRC 2017을 우승
- Main Idea
- Our goal is to improve the representational power of a Network by explicitly modelling the interdependencies between the channels of its convolutional Features
- 각 피쳐맵에 대한 전체 정보를 요약하는 Squeeze operation, 이를 통해 각 피쳐맵의 중요도를 스케일해주는 excitation operation으로 이루어져 있습니다. 이렇게 하나의 덩어리를 SE block
• SE block의 장점
- 네트워크 어떤 곳이라도 바로 붙일 수 있습니다. VGG, GoogLeNet, ResNet 등 어느 네트워크에도 바로 부착이 가능합니다.
- Parameter의 증가량에 비해 모델 성능 향상도가 매우 큽니다. 이는 모델 복잡도(Model complexity)와 계산 복잡도(computational burden) 이 크게 증가하지 않다는 장점이 있습니다.
- Implementation

- Test Result
