Kaggle Competition Related COVID19
COVID19 & Pandemic
코로나 19로 인해 WHO가 Pandemic을 선언한 가운데, 최근 Kaggle에서 코로나 관련 Dataset과 Competition이 등장하고 있어
이번 Post에서 소개해 볼까 합니다.
Dataset
먼저 Kaggle에 등록된 코로나 19 관련 Dataset들을 살펴보도록 하겠습니다.
https://www.kaggle.com/datasets?search=covid19&sort=usability
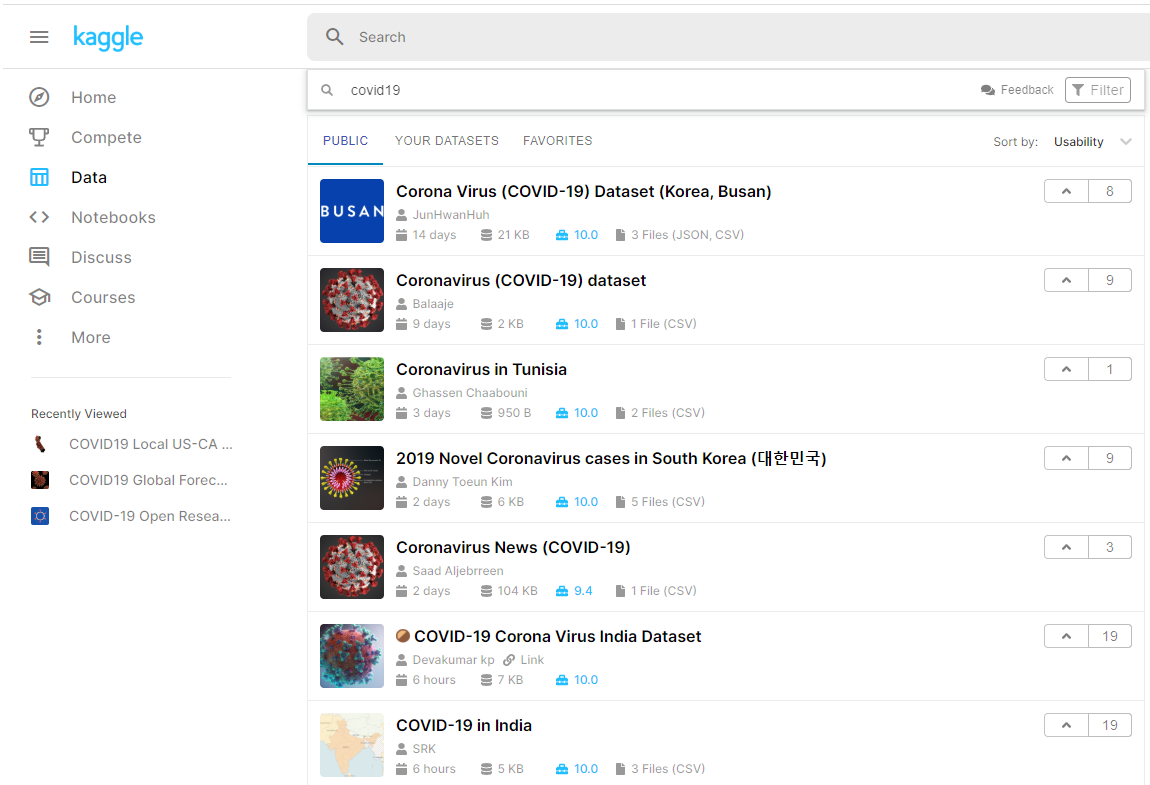
매우 다양한 Dataset이 공개되어 있습니다. 또한, 대한민국에서 공개한 Dataset도 꽤 많이 눈이 띄네요.
그 중에서도 초기에 공개되어 인기를 끌었던, 한양대 대학원생 김지후님이 공개하신 Dataset도 있습니다.
- 관련뉴스 : https://n.news.naver.com/article/030/0002871312
- Kaggle에 공개된 김지후님의 Dataset : https://www.kaggle.com/kimjihoo/coronavirusdataset
국격 높아지는 소리가 들리네요~!
Task
- 이번에는 코로나 19와 관련된 Kaggle Task를 알아보도록 하겠습니다.
- 관련 Dataset은 아래의 Link에서 확인하실 수 있습니다.
- COVID-19 Open Research Dataset Challenge (CORD-19) : https://www.kaggle.com/allen-institute-for-ai/CORD-19-research-challenge
- 이 Dataset은 백악관과 몇몇의 연구 그룹에서 배포한 것입니다.
- 이 Dataset은 COVID-19, SARS-CoV-2 및 코로나 바이러스에 관한 44,000 개가 넘는 학술 자료를 제공하며, 그 중에 29,000 개는 전문으로 제공됩니다.
- Text 형태의 학술 자료이기 때문에 자연어 처리 혹은 기타 AI 기술을 이용하여 다양한 작업을 할 수 있을 것이라고 기대됩니다.
- 이 Datset은 주기적으로 Update되며, 최신 Dataset은 아래 Link에서 확인하시면 됩니다.
- 저는 3월 13일자 Dataset을 Download하였습니다. Directory 구조는 아래와 같았습니다.
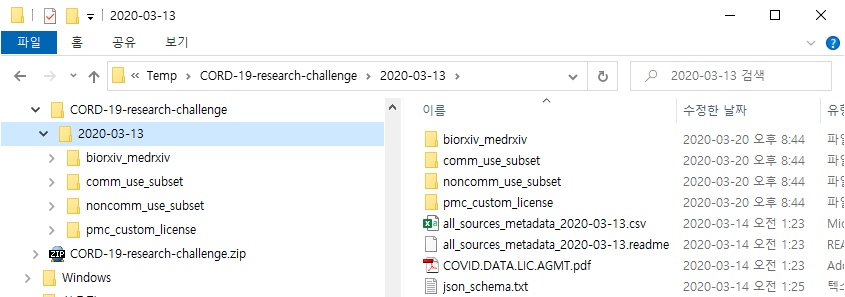
- 각 Folder는 아래와 같은 문서를 제공합니다.
- Commercial use subset (includes PMC content)
- Non-commercial use subset (includes PMC content)
- Custom license subset
- bioRxiv/medRxiv subset (pre-prints that are not peer reviewed)
- 개별 문서는 JSON 형태의 File로 제공되며, Schema는 다음과 같습니다.
- CSV 형태로 Metadata가 제공되며, 개별 문서의 제목은 각 문서의 Hash값( SHA )값과 Match 됩니다.
Task List
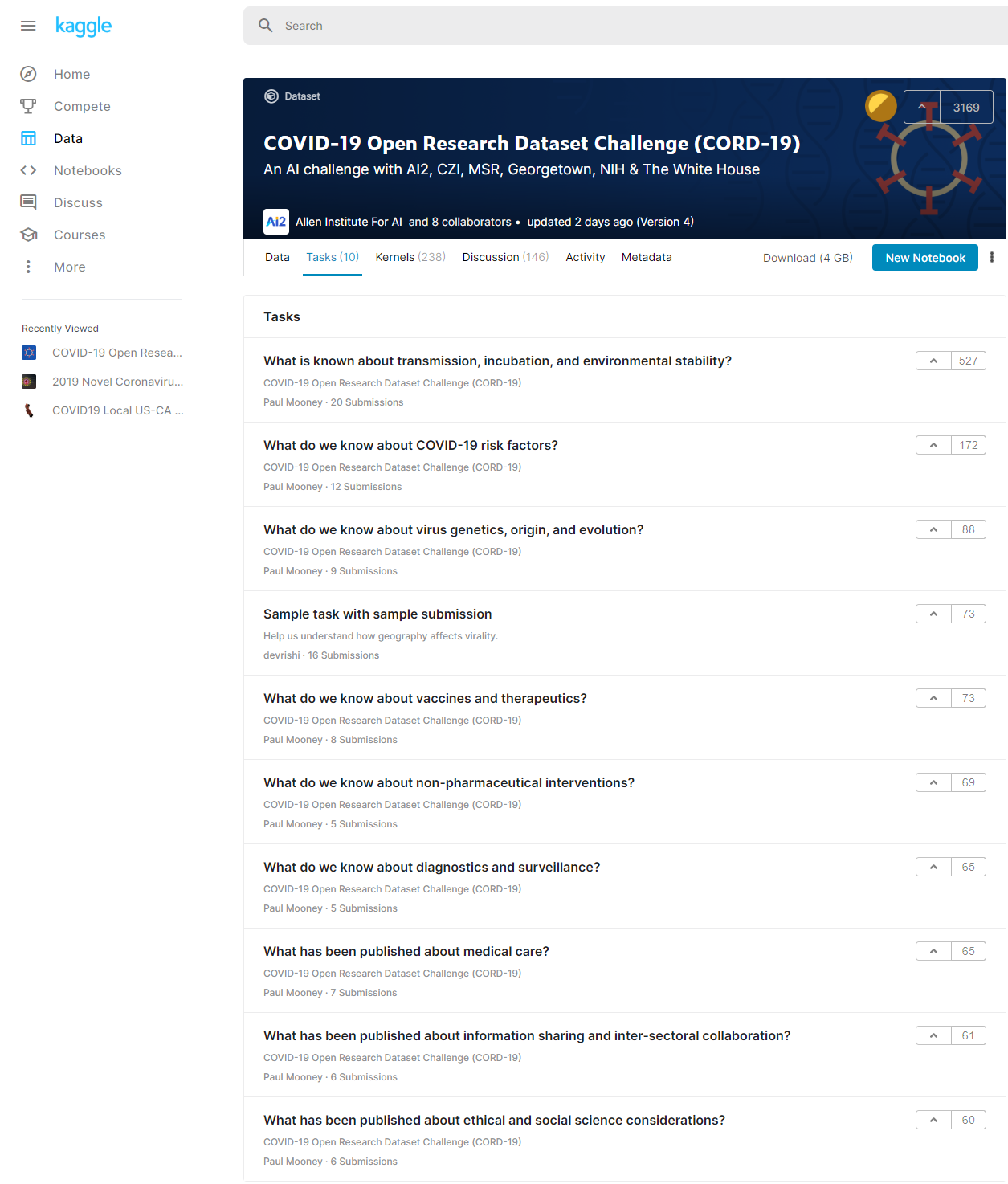
- 이 Dataset과 연결된 Task List는 아래 Link를 참고해 주시기 바랍니다.
- 다양한 Task 들이 있네요.
-
Task들의 제목들을 보아하니, 공개된 Dataset에서 적절한 답변을 찾는 Model을 만드는 것이 이 Task들의 목표 같습니다.
-
아무 Task 하나를 살표보겠습니다. 두번째 보이는 Task에 들어가 보겠습니다.

-
Dataset에서 코로나 19의 Risk Factor를 조사해 보라는 Task네요.
-
제출된 Submission 중 하나를 살펴보도록 하겠습니다.
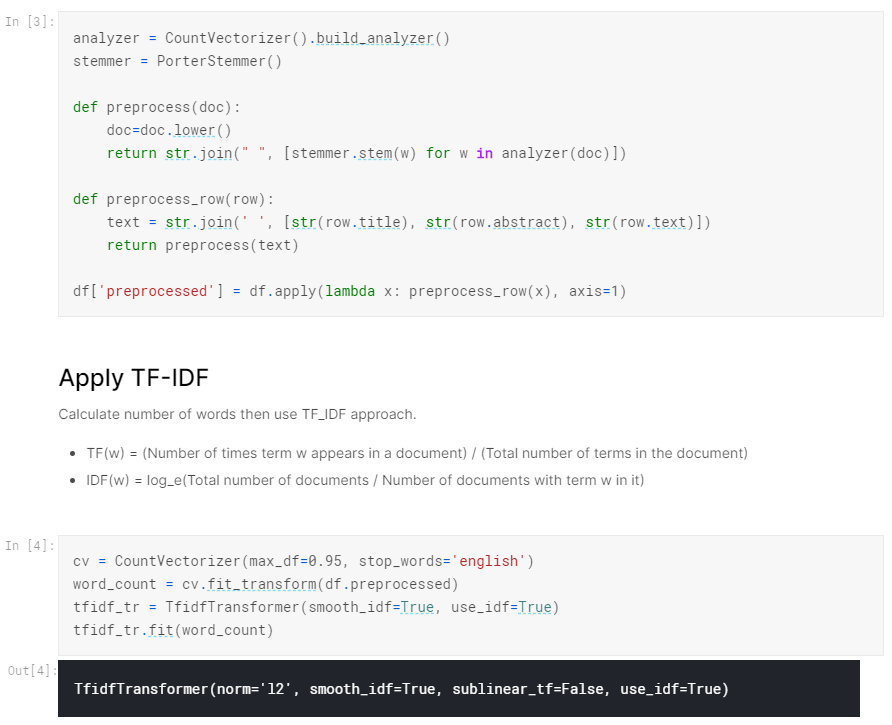
- 위 Submission은 TF-IDF으로 찾고자 하는 Keyword와 관련된 단어를 검색해 내는 방법을 쓰는 것 같습니다.
- 제가 NLP 쪽은 거의 지식이 없는데, 이 Task 들의 Submission들을 보면서 공부하면 좋을 것 같다는 생각이 드네요.
Competition
- 현재 Kaggle에 코로나 19 관련 Competition은 2개가 있습니다.
- COVID-19 Global Forecasting Challenge : https://www.kaggle.com/c/covid19-global-forecasting-week-1/overview
- COVID-19 California Forecasting Challenge : https://www.kaggle.com/c/covid19-local-us-ca-forecasting-week-1/overview
COVID-19 Global Forecasting Challenge & COVID-19 California Forecasting Challenge
- 이 2개의 Competition은 유사한 Competition이며, 백악관의 OSTP(Science and Technology Policy)에서 코로나 19 문제를 해결하기 위해 Kaggle을 포함한 다양한 연구 그룹에 배포하였습니다.
- 이 Competition의 주요 목적은 지역별로 사망자를 예측하는 것이라기 보다는 코로나 19의 전파에 영향을 미치는 중요 요인이 무엇인지를 예측하는 것입니다.
- Data File을 받아서 어떤 Data가 포함되어 있는지 한 번 살펴보도록 하겠습니다.
- 위 Data는 남한 Data의 첫부분만 조금 출력한 것입니다. 각 Column의 의미는 다음과 같습니다.
- Id : 각 Data의 고유 ID
- Province/State : 주 이름
- Country/Region : 국가이름
- Lat/Long : 위도 / 경도
- Date : 날짜
- ConfirmedCases : 누적 확진자 수
- Fatalities : 사망자
- 음… 이 정보들로만 주요 전파 인자를 파악할 수 있을까요 ?
- 제 생각에는 추가적인 정보가 필요할 것으로 보입니다.
- 어떤 정보가 있을까요 ? 우선 나라 / 주 이름이 있으니깐 국가별 / 주별 특징을 추가할 수 있을 것 같습니다.
- 예를 들면, GDP나 인구, 온도 , 습도, 인구 밀도 , 단위 면적당 병원 , 약국 수, 평균 연령 등등….
- 매우 다양한 Feature들을 추가할 수 있을 것 같네요.
- 그런데, 저런 정보를 어떻게 하면 구할 수 있을지가 고민이네요. 혹시 아시는 분 댓글 부탁드립니다.