Transformer #5 - Decoder Detail
0. Introduction
안녕하세요, 이번 Post에서는 Transformer의 Decoder에 대해서 자세히 알아보도록 하겠습니다.
Transformer Decoder의 각 부분을 구체적으로 하나씩 알아보도록 하겠습니다.
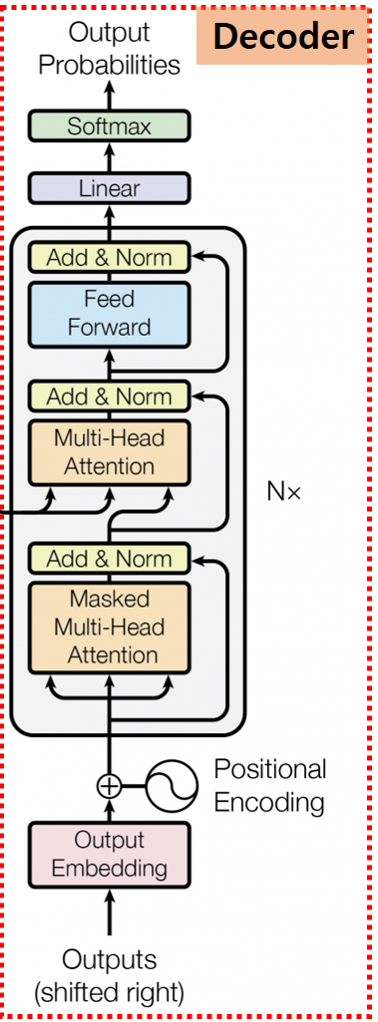
Encoder에서 살펴본 구조도 몇몇 보이지만, Decoder는 이전의 Decoder 출력을 기반으로 현재 출력을 생성해 내는 자기 회귀적 특징으로 인해
조금씩 다른 부분이 있습니다.
Decoder에서 이런 자기 회귀적인 특징이 가장 많이 반영되어 있는 부분이 Masked Multi-Head Attention 부분이니 먼저 이 부분을 자세히 알아보도록 하겠습니다.
1. Masked Multi-Head Attention
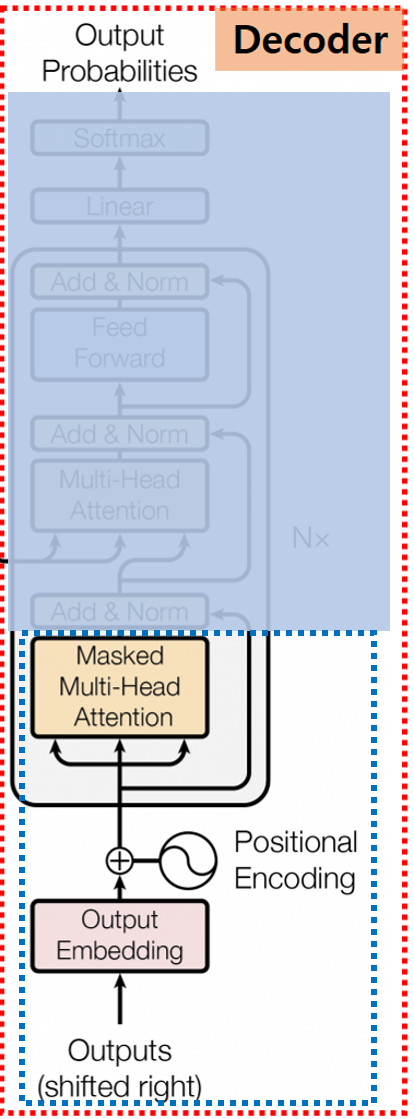
1.0. Shifted Right
Decoder 입력은 최초
최초 시작을 뜻하는 ‘SOS’ Token으로 시작하게 되고 실제 의미 있는 예측 값은 한 단계 Shifted 됩니다.
이를 Shifted Right라고 합니다.
1.1. Embedding & Positional Encoding
Embedding & Positional Encoding은 Encoder와 유사합니다.
1.2. Teacher Forcing
1.2.0. Introduction
Decoder를 Train 시키는 상황을 생각해 보면, 이전의 정보를 바탕으로 다음의 정보를 예측한다고 생각할 수 있습니다.
그런데, 만약 이전 정보가 잘못 예측된 정보라면 다음의 정보 예측도 제대로 될 수가 없을 것입니다.
예를 들어 봅시다. ‘I am your father’라는 문장을 예측해야 하는 경우라면 두 번째 ‘am’을 제대로 예측하지 못했다면 그다음 단어인 ‘your’도 제대로 예측할 수 없을 것입니다.
이와 같은 Train 시의 문제를 해결하려면 Train 시에 Model이 예측한 정보를 가지고 다음 정보를 예측하도록 해서는 안 되고, 실제 정답의 정보를 가지고 Train을 진행시켜야 합니다.
이처럼 Train 시에 정답 Data를 이용해서 Train 시키는 방법을 ‘Teacher Forcing’ 기법이라고 합니다.
즉, 전체적인 흐름은 Encoder에서 넘어온 정보와 이전 과정까지의 정답 정보를 입력으로 해서 다음 출력을 생성하고,
이 예측값과 실제 정답과의 오차를 Backpropagation 해서 전체 Model의 Parameter를 Update 하는 방식으로 Decoder 학습이 진행되게 됩니다.
1.2.1. Attention Score Masking
Transformer Model에 Teacher Forcing 기법을 적용하기 위해서, 논문에서는 Attention Socre를 Masking 하는 방법을 이용합니다.
Transformer에서는 Attention Score 값 자체가 각 Token에 대한 정보이므로 이를 가려버리는(Masked) 방법을 사용합니다.
예를 들어 ‘I am your father’라는 문장의 Attention Score가 다음과 같다고 가정해 보겠습니다.
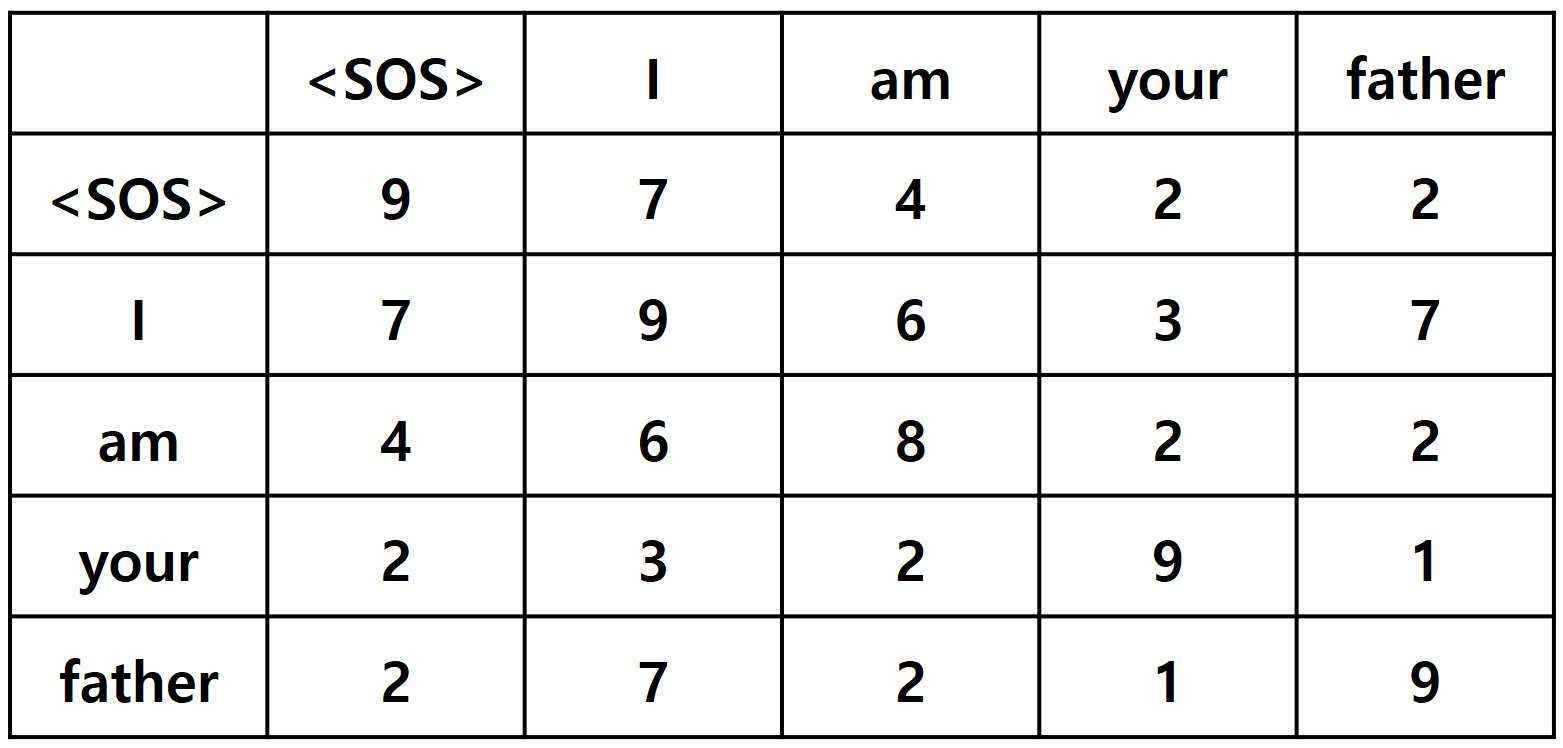
Transformer에서는 Attention Score가 Model 예측해야 할 답과 같은 값이기 때문에, Train 시에 예측해야 할 단어의 Attention Score를 사용해서는 안 됩니다.
답을 알고 시험을 보는 것과 같기 때문이죠.
예를 들어서 ‘am’까지의 정보를 이용해서 다음에 올 단어를 예측해야 하는 경우에는 ‘am’까지의 Attention Score만을 이용해서 Train 해야 합니다.
즉, ‘SOS’ , ‘I’ , ‘am’까지의 단어를 가지고 Attention Scroe를 구하고, 그 정보를 이용해서 계산된 가중치를 Value Vector에 곱해서 Attention Score를 얻어야 합니다.
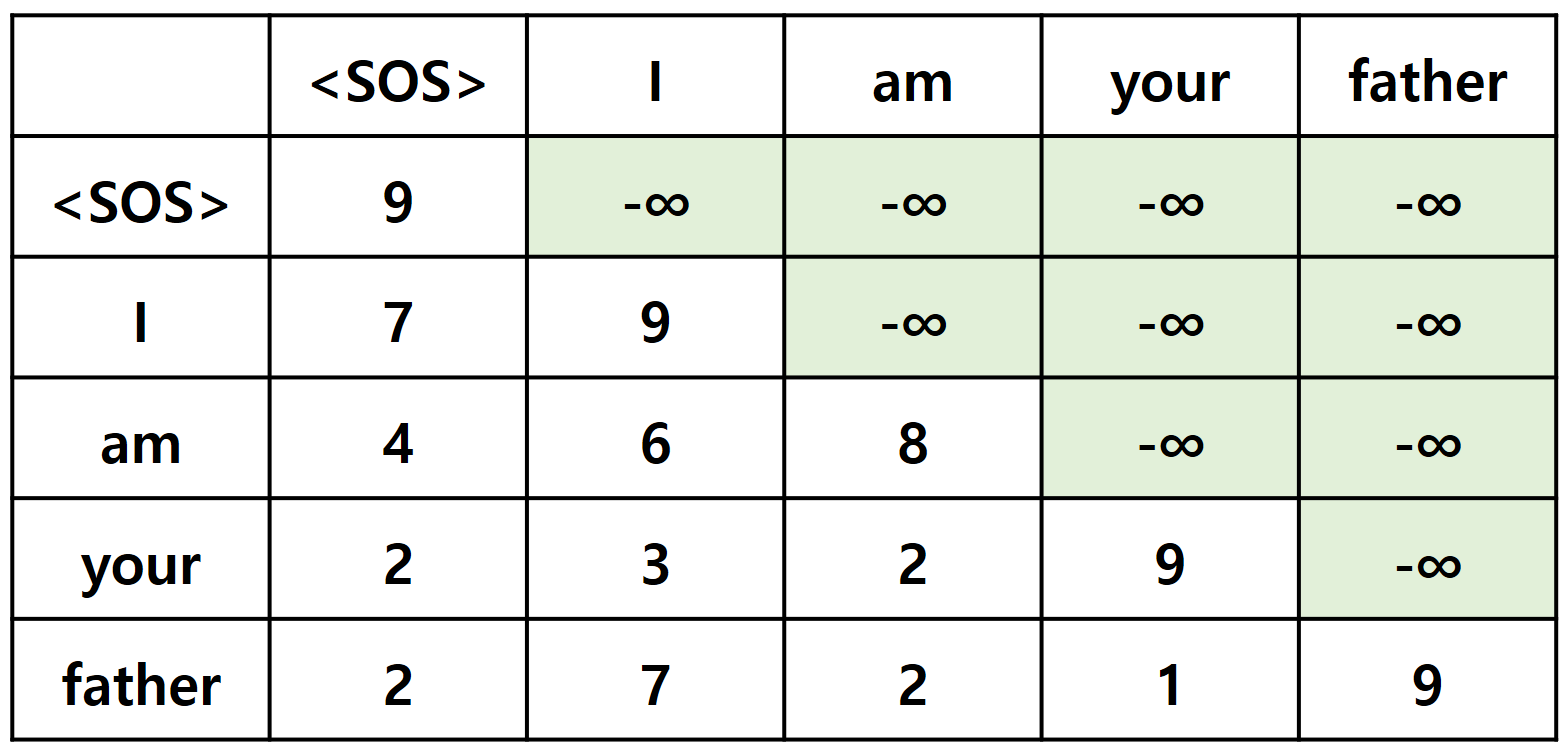
이렇게 하기 위해서 다음 단어의 Attention Score에 -∞를 곱해서 Softmax 값이 0이 되게 하는 방법을 사용합니다.
2. Add & Norm
Add & Norm Layer는 Encoder의 그것과 동일합니다.
3. Multi-Head Attention
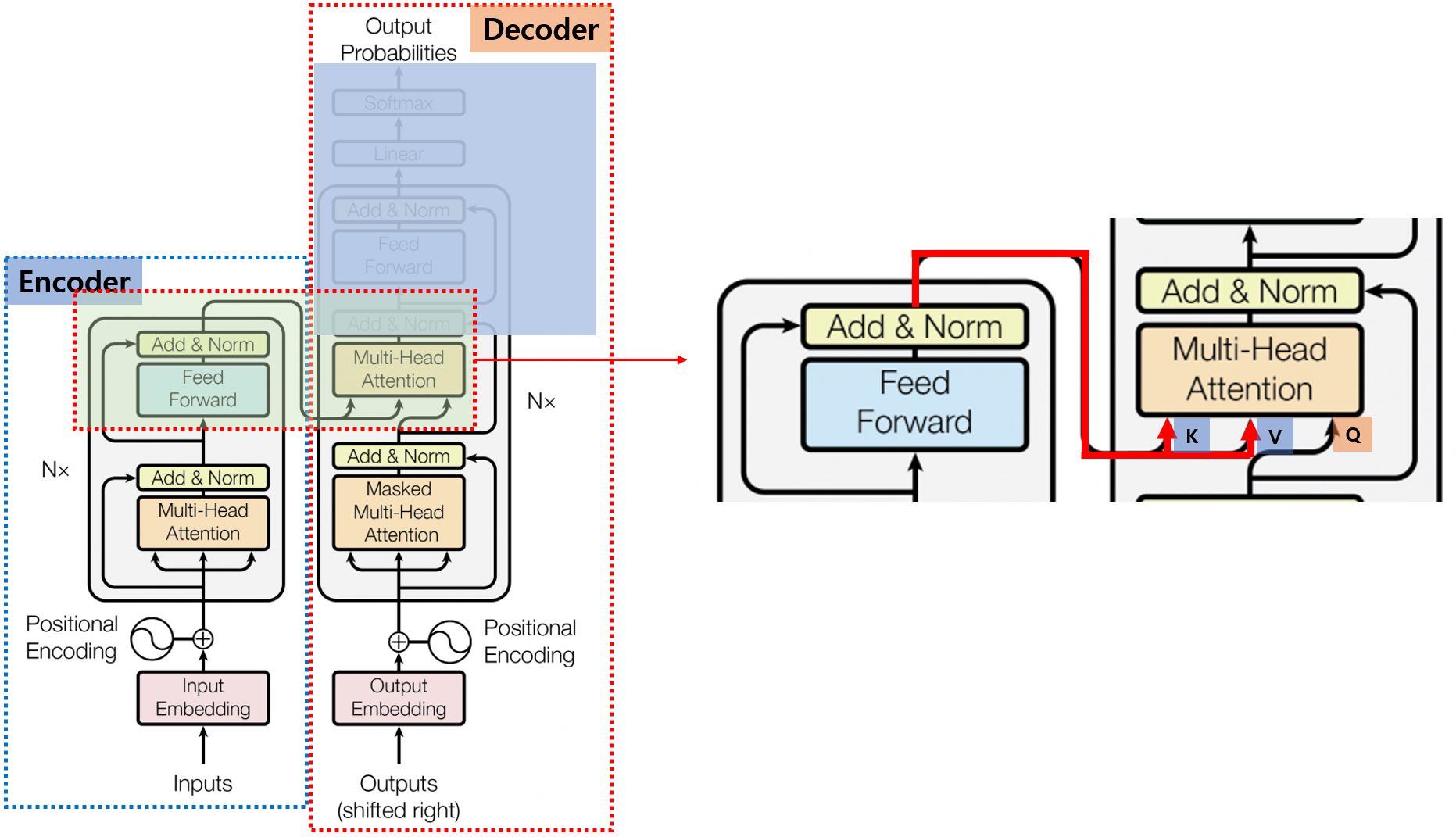
Add & Norm Layer를 거친 후에 다시 한번 Multi-Head Attention Layer가 나옵니다.
이 Multi-Head Attention는 앞서 설명한 Masked Multi-Head Attention과 다르게 일반 Self Attention 구조를 가지고 있습니다.
다만, 다른 점은 위의 오른쪽 그림에서 보이겠지만, 입력으로 들어가는 Q, K, V 값이 전부 Decoder의 출력이 아니라
Encoder의 출력을 일부 사용한다는 점입니다.
즉, Encoder의 정보를 참조하겠다는 의미입니다. Encoder 정보를 참고한다고 해서 ‘Encoder-Decoder Attention’이라고도 합니다.
Q 값만 Decoder의 값을 사용하고, K, V 값은 Encoder의 값을 사용하게 됩니다.
4. Feed Forward & Add & Norm
Encoder-Decoder Attention을 거친 값들은 Feed Forward & Add & Norm을 차례로 거칩니다.
이 Layer들은 Encoder에서 설명한 것과 동일한 구조와 역할을 합니다.
여기까지가 Decoder의 핵심 구조이며, 논문에서는 이 구조를 6개를 쌓아서 사용하고 있습니다.
지금까지 Transformer의 전체적인 구조를 알아보았습니다.
Transformer 구조는 현재 NLP 관련 분야에서 최고의 성능을 보이고 있고, BERT , GPT 근간이 되고 있으며 Vision 등의 다른 분야에서도 응용되고 있습니다.
이와 같이 다양하게 응용되고 성능이 우수한 Model의 구조를 기본부터 알아보는 것도 좋은 학습이 될 것 같습니다.