Honeybee - 카카오브레인의 Multimodal LLM
이번 Post에서는 지난 달 카카오브레인에서 발표한 Multimodal LLM Honeybee에 대해서 알아보도록 하겠습니다.
Multimodal Model이란 다양한 입력의 형태를 받아들여서 결과를 내는 Model을 뜻합니다.
예를 들어, 이미지, 텍스트, 소리 등의 입력을 받아서 학습한 Model을 뜻합니다.
Honeybee의 경우에는 이미지와 텍스트를 입력으로 받아서 텍스트를 출력하는 LLM입니다.
카카오브레인에서 Honeybee를 Open Source로 공개하였고, 실제로 어느 정도 성능인지 제가 한 번 Test해 보도록 하겠습니다.
카카오브레인 Blog
https://blog.kakaobrain.com/news/1391
Honeybee의 Github
https://github.com/kakaobrain/honeybee
Paper
https://arxiv.org/pdf/2312.06742.pdf
1. Test Environment Setup
Honeybee는 PyTorch 2.01이 필요합니다.
우선 가상환경이나 Docker를 이용해서 PyTorch 2.01 설치하셔야 합니다.
Docker를 이용한 PyTorch 설치는 아래 Link에 좋은 글이 있으니 참고하시기 바랍니다.
Naver Blog - PyTorch GPU Docker 설치 on WSL2
Tistory - PyTorch GPU Docker 설치 on WSL2
PyTorch 2.01 환경을 만드신 다음에는 Github에서 Source를 받습니다.
Github에 나와있는 requirements.txt로 나머지 Package들을 설치합니다.
pip install -r requirements.txt
gradio 형태로 Demo를 해보려면 추가의 Package들의 설치가 필요합니다.
pip install -r requirements_demo.txt
2. Model File
Github에는 Pre-Trained Model File도 올라와 있습니다.
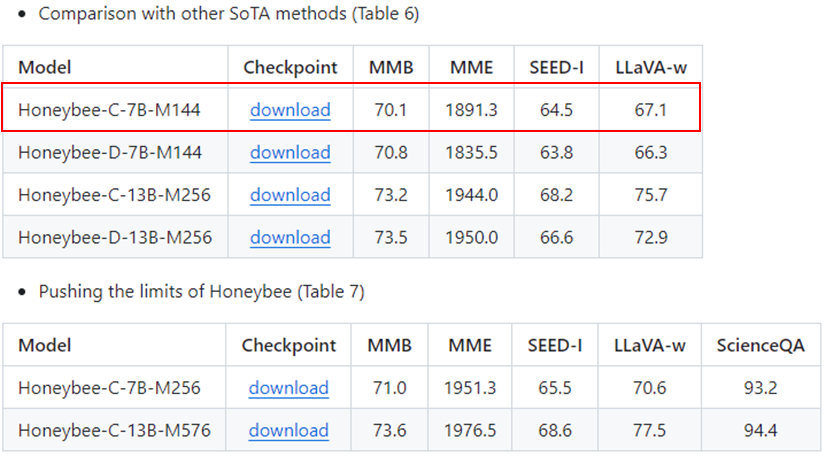
저는 가장 작은 Model인 ‘Honeybee-C-7B-M144’를 받아보겠습니다.
13G 정도 되네요. 제일 작은 Model 입니다.
3. Test
자, 이제 Source도 받았고, Model File도 받았으니, Inference Test를 한 번 해 보도록 하겠습니다.
Inference에 사용할 Code는 https://github.com/kakaobrain/honeybee/blob/main/inference_example.ipynb 를 참고하도록 하겠습니다.
최초 실행시에는 Model File이외에도 아래와 같이 추가로 Download를 조금 하네요
그리고, 아래와 같이 Import Error가 발생하는데, Github에 올라온 Source에 문제가 있습니다.
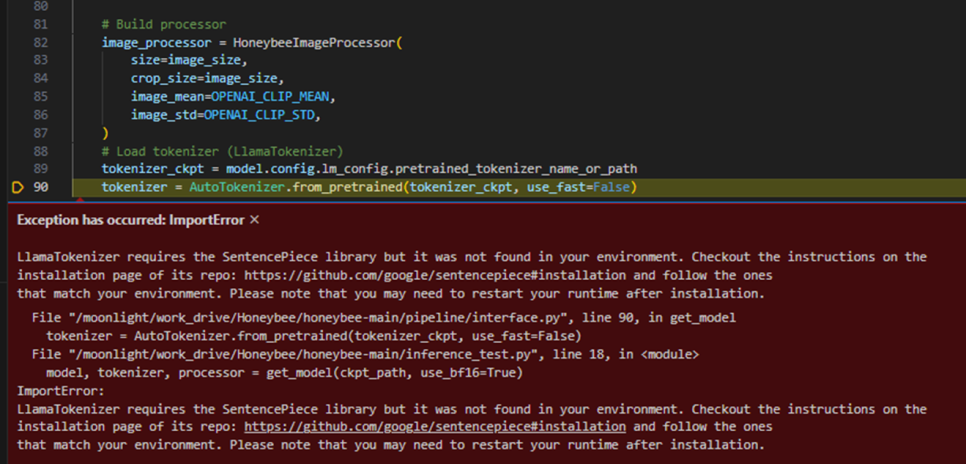
빠진 Package가 있어서 발생하는 문제이니, 아래와 같이 별도로 하나 더 설치하시면 됩니다.
pip install sentencepiece
Pull하려고 하니, 이미 다른 분이 해 놓으셨네요.
이제 진짜 모든 준비가 끝났으니, 실제 Test를 해 보겠습니다.
inference_example.ipynb를 사용하실 때는, Model File의 Path와 Test할 Image File Name 그리고 Image에 대한 Prompt를 수정해야 합니다.
각각 아래의 변수들을 적절한 값을 넣어주시면 됩니다.
Model File Path : ckpt_path = “../7B-C-Abs-M144/last“
Image File Name : image_list = [”./examples/monday.jpg”]
Prompt : prompts = [construct_input_prompt(“Explain why this meme is funny.”)]
Honeybee Github에 있는 몇 개의 그림파일에 “Explain why this meme is funny.”라는 Prompt를 주고 결과를 보도록 하겠습니다.


꽤 훌륭한 결과를 보여주는 것 같습니다.
그림에 대한 일반적인 묘사와 함께 글자도 제대로 인식하고 있으며, 무엇보다도 이런 사실들을 바탕으로 이 그림이 재미있는 이유를 추론하는 것이 가장 놀라운 점입니다.
하나 더 해보겠습니다. 이번에는 아래 그림을 주고, prompt는 “Tell me how you feel for this picture.”라고 입력했습니다.

아래와 같은 결과를 보여주네요

상당히 정확하게 그림을 묘사하고 있고, 창의적이고 재밌는 그림이라는 평가도 내리고 있는 것을 볼 수 있습니다.
다만, 손 부분을 강아지 손이라는 것을 인식하지 못하고 붓(Paintbrush)라고 판단하고 있네요.
근데, 이건 좀 애매하긴 한 것 같습니다.
똑같은 질문을 DALL-E 에게도 해 보았고, 아래와 같은 답변을 내놓았습니다.
“The image you’ve shared appears to be a humorous take on the classic painting “Mona Lisa” by Leonardo da Vinci.
Instead of the usual human figure, it features a dachshund dog’s face and body superimposed onto the painting’s subject.
The juxtaposition of a classic work of art with a modern meme culture twist tends to evoke amusement and can be seen as a playful commentary on the merging of high and pop culture.
It’s a creative and light-hearted image that might bring a smile to someone’s face.”
여러분들은 어떤 답이 더 나은 것 같으신가요?
이번에는 prompt를 “이 그림에 대해서 설명해봐"이라고 한글로 주었습니다.

한글 Prompt에 대해서는 아직 좀 더 다듬어야 할 것 같습니다.
이번에는 아래 그림을 주면서, prompt로는 “Make a title for the picture and extract 10 keywords.”라고 입력해봤습니다.

Honeybee는 아래와 같이 답변했습니다.

그리고, 동일한 그림과 질문을 했을 때 DALL-E의 답변은 아래와 같았습니다.
Title: “Embrace of the Ocean”
Keywords: Titanic, sunset, romance, iconic, embrace, freedom, sea, Jack, Rose, cinematic
제목은 Honeybee가 좀 더 마음에 들고, Keyword는 DALL-E가 좀 더 나은 것 같네요.
( DALL-E는 영화 타이타닉의 한 장면인 것을 알고 있네요)
이번 Post에서는 카카오브레인에서 발표한 LLM인 Honeybee에 대해서 간단하게 살펴보았습니다.
아직 Train Code가 공개되지는 않았지만, 성능적인 면에서는 굉장히 인상적이었습니다.
아쉬운 점이라면, 한글 Prompt에 대해서 살짝 아쉬운 결과를 보이는 것 정도였습니다.
좀 더 Tuning하면 나아지겠죠?