DCGAN(Deep Convolutional Generative Adversarial Networks) (EN)
DCGAN(Deep Convolutional Generative Adversarial Networks)
0. Introduction
-
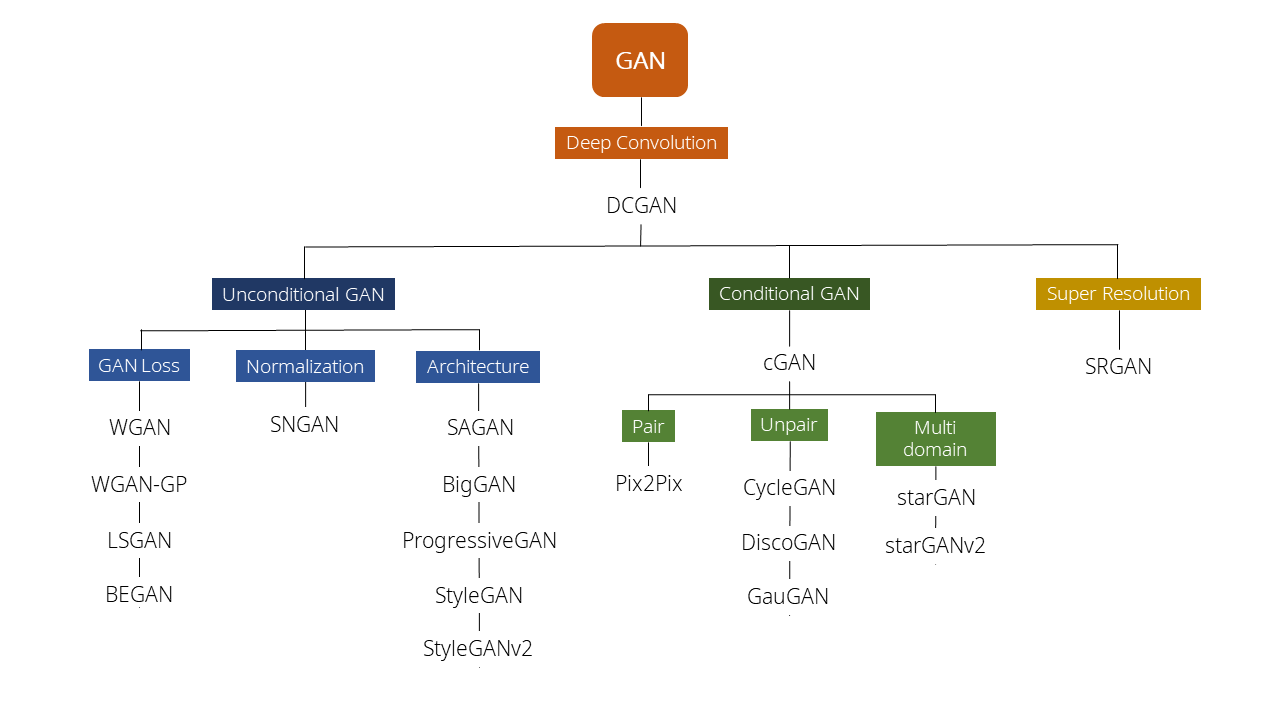
After Goodfellow, Ian introduced GAN in 2014, a wide variety of GAN applications have emerged, as shown in the figure below.
( Various Type of GAN. https://ysbsb.github.io/gan/2020/06/17/GAN-newbie-guide.html )
-
In this post, we will take a look at DCGAN (Deep Convolutional Generative Adversarial Networks), which can be the beginning of all GAN applications.
- DCGAN was released in 2016 by Alec Radford & Luke Metz , Soumith Chintala.
- The paper title is ‘UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS’, and please refer to the paper link below. UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS
1. Issues of GAN
-
This paper pointed out some limitations of existing GAN.
- GANs have been known to be unstable to train, often resulting in generators that produce nonsensical outputs.
- It is not easy to train because the structure of GAN itself is unstable.
- GANs have been known to be unstable to train, often resulting in generators that produce nonsensical outputs.
- One constant criticism of using neural networks has been that they are black-box methods, with little understanding of what the networks do in the form of a simple human-consumable algorithm.
- This is a chronic limitation of the Neural Net structure. It is difficult to interpret the trained model.
- It is often expressed as a ‘Black-Box’ because it is not known on what makes the model the judgment.
- It is difficult to quantitatively evaluate GAN model performance.
- It is difficult to quantitatively determine how well model is trained from the sample, and it is also difficult for humans to evaluate it.
2. Purpose of DCGAN
- Proof that the generator does not simply memorize and display sample data
- If the structure of the model is large enough compared to the sample data, and the training is carried out sufficiently, the model may memorize all the sample data.
- It is hard to accept as Generating.
- At first glance, it seems to have something to do with Overfitting…
- WALKING IN THE LATENT SPACE
- The result of generation should occur naturally even with small changes in z of latent space. ( This is called as ‘WALKING IN THE LATENT SPACE’ in paper)
3. Architecture Guidelines
3.1. Overall
- Moving from the structure proposed by GAN to DCGAN, the overall structure remains the same, but some details have changed.
- Here’s how the authors established the structures in the paper:
- after extensive model exploration we identified a family of architectures that resulted in stable training across a range of datasets and allowed for training higher resolution and deeper generative models.
- In paper, it is said in a grandiose way but it means that the best model structure was found with so many trials and errors.
- after extensive model exploration we identified a family of architectures that resulted in stable training across a range of datasets and allowed for training higher resolution and deeper generative models.
3.2. Modification Points
- The methods to improve the performance of the existing GAN proposed by DCGAN are as follows.
1. Instead of pooling layers in G/D, strided convolutions are used for D and fractional-strided convolutions are used for G.
2. Using Batch Normalization
3. Not using FC(Fully Connected) Hidden Layer
4. Except for the last layer in G, the activation function is RELU. The last layer uses tanh
5. In D, LeakyRELU is used for activation functions of all layers.
- Let’s take a look at the modifications one by one.
3.2.1. Add Convolution Layer
- First, let’s look at strded convolutions and fractional-strded convolutions used instead of the Pooling Layer.
- Strided convolutions and fractional-strided convolutions are one of the convolution methods, but the size of the convolution applied to the existing CNN gradually decreases as it goes through the kernel. There is a difference that the size of strided convolutions and fractional-strded convolutions increase the kernel size through a specific operation.
- The following describes strided convolutions. Strided convolution is a convolution that move by stride.
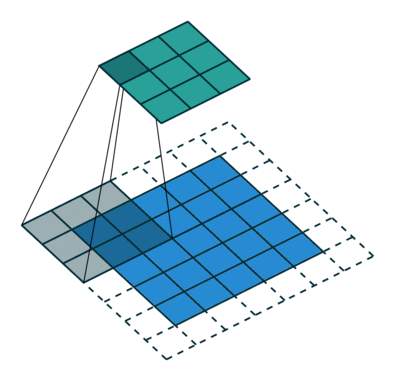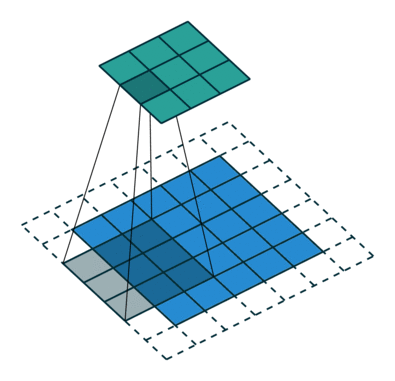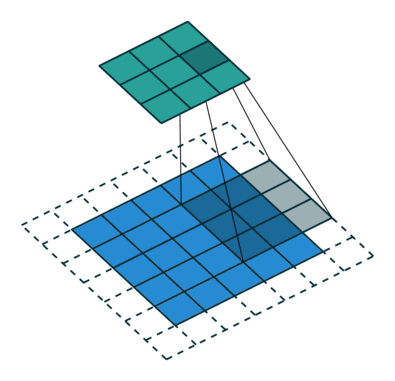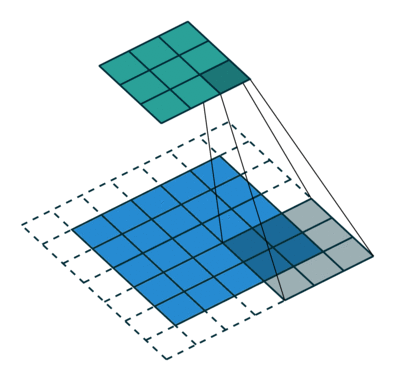
- Fractional-strded convolutions are called transposed convolutions (sometimes called deconvolution, but this is not an exact concept).
- Strictly speaking, the method used by DCGAN’s generator is Transposed Convolution.

-
For more information on Transposed Convolution, please refer to the article at the link below.
CS231n의 Transposed Convolution은 Deconvolution에 가까운 Transposed Convolution이다
- Transposed Convolution is implemented in Tensorflow as a function called Conv2DTranspose().
-
For a description of the various convolution methods, please, refer to the link below for more information.
An Introduction to different Types of Convolutions in Deep Learning
3.2.2. Apply Batch Normalization
- Batch Normalization is a concept introduced in paper, [Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift] (https://arxiv.org/abs/1502.03167) published in 2015 and it is widely applied neural network.
- Paper Link( http://proceedings.mlr.press/v37/ioffe15.pdf )
- The purpose of Batch Normalization is to prevent Gradient Vanishing / Gradient Exploding.
- Even before Batch Normalization, ReLU was used for the activation function or He or Xavier initialization was used for weight initialization.
- Unlike those indirect methods, Batch Normalization suppresses Gradient Vanishing / Gradient Exploding while directly participating in the training process.
-
Please refer to the link below for detailed explanation.
A Gentle Introduction to Batch Normalization for Deep Neural Networks
3.2.3. Others
- Additional explanations for the remaining changes will be omitted.
- As you can see, there is no need to explain in detail.
3.2.4. Overall Architecture
- The overall architecture of generator to which the above-mentioned contents are applied is as follows.
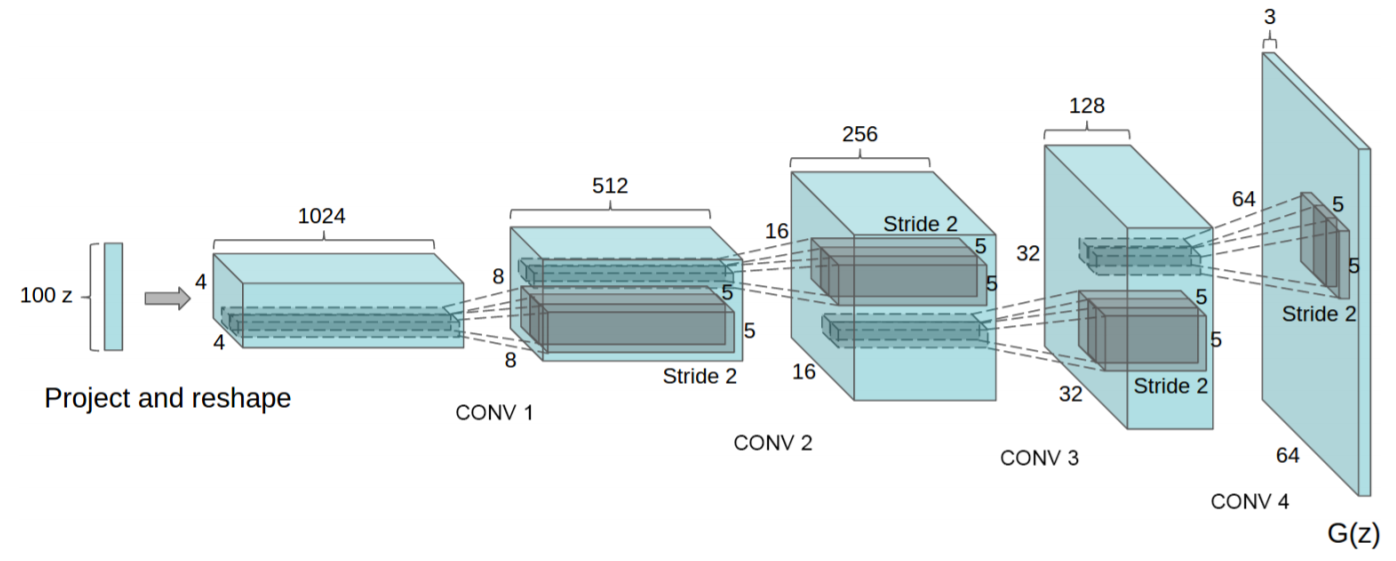
- Fractional-strided convolutions were applied in the process of going from z to 64x64 images and no fully connected layers or pooling layers were used.
4. Result
4.1. Image Generation
- All of the bedroom images below are images created with DCGAN after 1 epoch training.

- The bedroom images below are images created with DCGAN after 5 epoch training.

- The quality is great.
- According to the paper, the generator can theoretically memorize sample data but experimentally it is impossible by applying a low learning rate and mini-batch.
4.2. WALKING IN THE LATENT SPACE
- In the paper, one of the goals of DCGAN is to make the result change smoothly (walking) even with small changes in z.

- The picture above shows the change from the original image on the left to the generated image on the right.
- Where there used to be a wall, a window suddenly appears, and where there used to be a light, a window appears.
4.3. Overcoming ‘Black Box’
- By visualizing the features of DCGAN’s discriminator, we can see more clearly how the model works.

4.4. VECTOR ARITHMETIC ON IMAGE
- In paper, it is said that while DCGAN was performed, the characteristics of Word2Vec used in NLP could be used in image as well.
- For example, like vector(”King”) - vector(”Man”) + vector(”Woman”) = Queen in Word2Vec, it is said that similar VECTOR ARITHMETIC operation was possible with image.
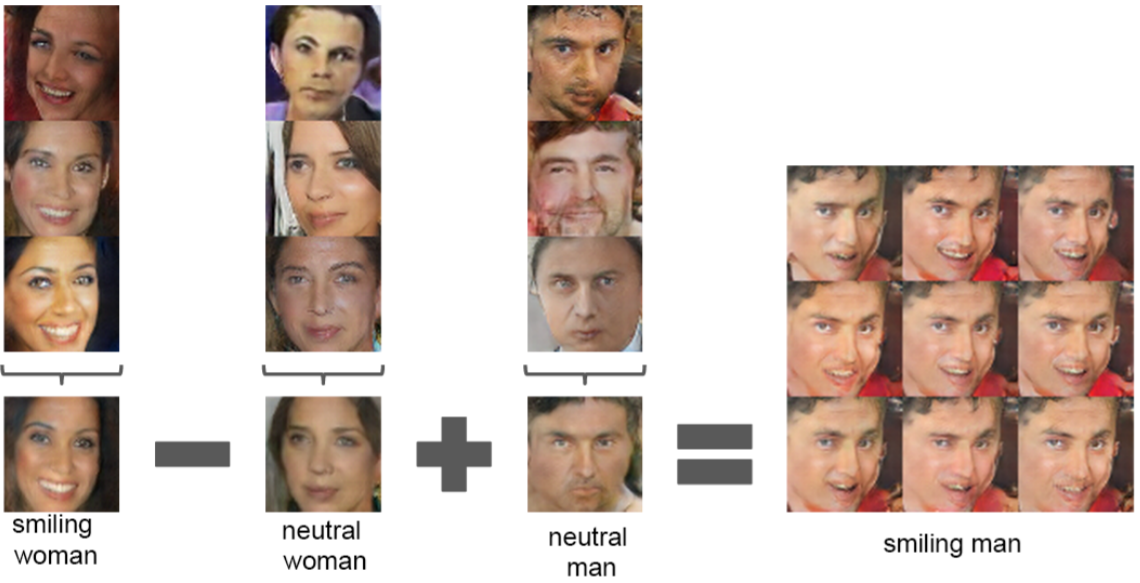

- In this post, I’ve reviewed DCGAN paper.
- Next, let’s look at the actual code of DCGAN.