All About LSTM
All About LSTM
- Input Shape : 반드시 3D Array 이어야 한다.
( Batch Size , Time Stamp , Feature Number )
- LSTM의 출력 ( Memory Cell 수 ) : N
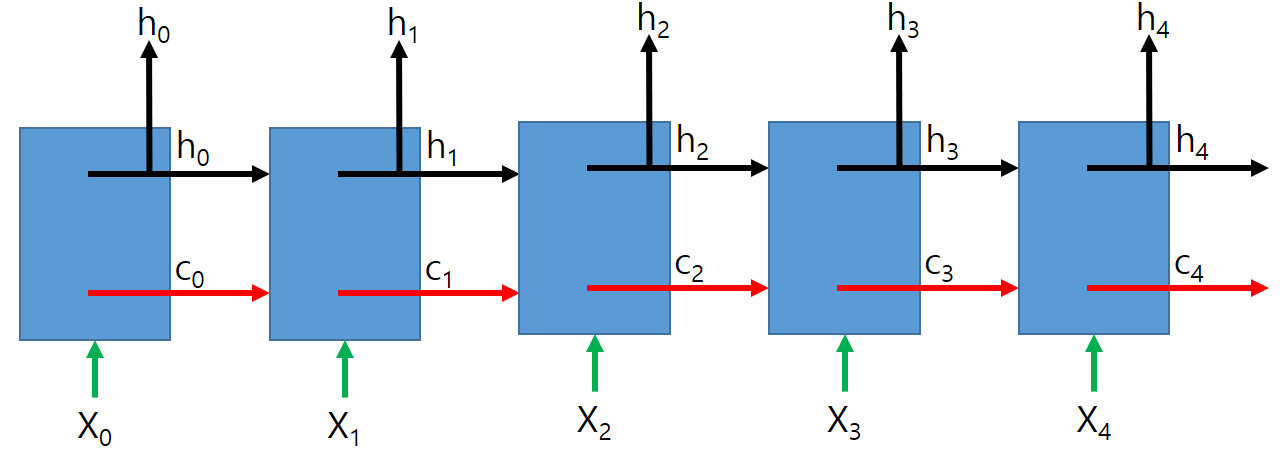
0. return_sequences / return_state / stateful
- Default는 두 Option 모두 False
0.1. return_sequences
-
False이면 마지막 출력 h4만 출력
-
Example
- Time Stamp : 3
- Featuer Number : 1
- Batch Size : 2
- LSTM 출력 : 4
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input
from tensorflow.keras.layers import LSTM
from numpy import array
inputs1 = Input(shape=(3, 1))
lstm1 = LSTM( 4 )(inputs1)
model = Model(inputs=inputs1, outputs=lstm1)
data = array([[0.1, 0.2, 0.3],[0.2, 0.3, 0.4]]).reshape((2,3,1))
p = model.predict(data)
print(p)
print(p.shape)
[[-0.0575355 -0.07571618 -0.00497641 0.03933733]
[-0.08588521 -0.1113222 -0.00439387 0.05813249]]
(2, 4)
-
return_sequences = False이면, 출력은 마지막 LSTM Cell만 나온다.
-
Shape은 ( Batch Size , LSTM 출력 )
-
True이면 각 Time Stamp의 모든 출력이 나온다.
-
Example
- Time Stamp : 3
- Featuer Number : 1
- Batch Size : 2
- LSTM 출력 : 4
inputs1 = Input(shape=(3, 1))
lstm1 = LSTM(4, return_sequences = True)(inputs1)
model = Model(inputs=inputs1, outputs=lstm1)
data = array([[0.1, 0.2, 0.3],[0.2, 0.3, 0.4]]).reshape((2,3,1))
p = model.predict(data)
print( p )
print( p.shape )
[[[-0.00992484 0.00204053 -0.00934763 -0.001566 ]
[-0.02673527 0.00618046 -0.02628965 -0.0047341 ]
[-0.04814639 0.01236558 -0.04956007 -0.00930633]]
[[-0.01992876 0.00419011 -0.01879886 -0.00302125]
[-0.04352047 0.01054809 -0.04349945 -0.00764405]
[-0.06930547 0.01890578 -0.07319777 -0.0134633 ]]]
(2, 3, 4)
- return_sequences = True인 경우의 각 Time Stamp별 출력이 모두 나오고, Output Shape은 ( Batch Size , Time Stamp , LSTM 출력 ) 이 된다.
0.2. return_state
-
return_state의 의미는 LSTM이 Output 뿐만 아니라, LSTM 내부 State( Hidden State , Cell State )도 같이 Return하라는 의미.
-
return_sequences = False / return_state = True이면, 마지막 Time Stamp에서의 Output , Hidden State , Cell State 모두 출력한다.
inputs1 = Input(shape=(3, 1))
lstm1, state_h, state_c = LSTM(4, return_state=True)(inputs1)
model = Model(inputs=inputs1, outputs=[lstm1, state_h, state_c])
data = array([[0.1, 0.2, 0.3],[0.2, 0.3, 0.4]]).reshape((2,3,1))
p = model.predict(data)
print("LSTM 출력\n",p[0] , p[0].shape)
print("Hidden State 출력\n",p[1] , p[1].shape)
print("Cell State 출력\n",p[2] , p[2].shape)
LSTM 출력
[[ 0.01608176 -0.04563671 0.05012723 -0.02996504]
[ 0.02256971 -0.06557295 0.06973792 -0.04364965]] (2, 4)
Hidden State 출력
[[ 0.01608176 -0.04563671 0.05012723 -0.02996504]
[ 0.02256971 -0.06557295 0.06973792 -0.04364965]] (2, 4)
Cell State 출력
[[ 0.03205967 -0.08535378 0.0981688 -0.05697074]
[ 0.04499921 -0.12033087 0.13603717 -0.0815461 ]] (2, 4)
-
마지막 Cell의 Output , Hidden State , Cell State가 출력이 된다.
-
Output , Hidden State , Cell State 각각 Output Shape은 ( Batch Size , LSTM 출력 ) 이 된다.
-
Output , Hidden State는 같은 값이므로, 동일한 값이 출력된다.
- return_sequences = True / return_state = True인 경우, Output , Hidden State , Cell State 모두 출력한다.
inputs1 = Input(shape=(3, 1))
lstm1, state_h, state_c = LSTM(4, return_sequences = True , return_state=True)(inputs1)
model = Model(inputs=inputs1, outputs=[lstm1, state_h, state_c])
data = array([[0.1, 0.2, 0.3],[0.2, 0.3, 0.4]]).reshape((2,3,1))
p = model.predict(data)
print("LSTM 출력\n",p[0] , p[0].shape)
print("Hidden State 출력\n",p[1] , p[1].shape)
print("Cell State 출력\n",p[2] , p[2].shape)
LSTM 출력
[[[-0.00232224 0.01381751 0.00770746 -0.00485208]
[-0.00598483 0.037546 0.02239466 -0.0154511 ]
[-0.01042776 0.06827092 0.04281441 -0.03233362]]
[[-0.00453491 0.02751611 0.01552548 -0.00999177]
[-0.00951656 0.06102681 0.03691184 -0.02671457]
[-0.01474284 0.09843805 0.06241723 -0.05025584]]] (2, 3, 4)
Hidden State 출력
[[-0.01042776 0.06827092 0.04281441 -0.03233362]
[-0.01474284 0.09843805 0.06241723 -0.05025584]] (2, 4)
Cell State 출력
[[-0.02109056 0.14365022 0.09071556 -0.06398231]
[-0.02994104 0.21193042 0.13567713 -0.09934995]] (2, 4)
-
각 Output Shape은 아래와 같습니다.
-
LSTM 출력 : 각 Time Stamp마다 다 출력합니다.
### ( Batch Size , Time Stamp , LSTM 출력 ) ### -
Hidden State : 마지막 Cell의 출력을 나타낸다.
### ( Batch Size , LSTM 출력 ) ### -
Cell State : 마지막 Cell의 Cell State 출력을 나타낸다.
### ( Batch Size , LSTM 출력 ) ###
0.3. stateful
-
현재까지 학습 상태가 다음 학습시의 초기상태로 전달된다.
- stateful = True일때는 Input Shape 전달시에 반드시 Batch Size를 전해줘야 한다.
( Batch Size , Time Stamp , Feature Number )
-
reset_state()는 현재 Train Data가 다른 Train Data와 상관관계가 없다면 호출합니다.
-
마지막 Train Data를 마치고 다른 Epoch을 실행하는 경우에 Reset해야 한다.
-
한 Epoch 내에서도 여러 Sequence Data가 있을 경우에 새로운 Sequence Data를 시작할 때 Reset해야 한다.
-
1. Example
1.1. stateful Example
-
전체 Train Data Sequence를 Time Stamp 기준으로 몇 개로 나누어서 Train하는 예제
-
stateful을 이용하는 예를 보여준다.
import pandas as pd
import tensorflow as tf
import numpy as np
import os
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM, Conv1D, Lambda, Dropout
from tensorflow.keras.losses import Huber
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
train = pd.read_csv("train.csv")
train.head()
| id | breath_id | R | C | time_step | u_in | u_out | pressure | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 20 | 50 | 0.000000 | 0.083334 | 0 | 5.837492 |
| 1 | 2 | 1 | 20 | 50 | 0.033652 | 18.383041 | 0 | 5.907794 |
| 2 | 3 | 1 | 20 | 50 | 0.067514 | 22.509278 | 0 | 7.876254 |
| 3 | 4 | 1 | 20 | 50 | 0.101542 | 22.808822 | 0 | 11.742872 |
| 4 | 5 | 1 | 20 | 50 | 0.135756 | 25.355850 | 0 | 12.234987 |
-
아래 함수는 Train Data(x) , Target(y)를 받아서 Time Stamp(window_size)만큼 자르고, Batch Size만큼 모아서 Dataset으로 만들어주는 함수
-
.window() Function
- window_size : Time Stamp 수. 이 수만큼 Time Stamp Data를 만들어 준다.
- shift : 다음 Data를 만들때 몇 개의 Data를 Skip할 것인가
- stride : Time Stamp 내에서 몇 개의 Data를 Skip할 것인가
- drop_remainder : x에서 window_size만큼 만들다가 남는건 어떻게 할 것인가
def windowed_dataset(x, y, window_size, batch_size, shuffle):
ds_x = tf.data.Dataset.from_tensor_slices(x)
ds_x = ds_x.window(window_size, shift=1, stride = 1, drop_remainder=True)
ds_x = ds_x.flat_map(lambda x: x.batch(window_size))
ds_y = tf.data.Dataset.from_tensor_slices( y[window_size:])
ds = tf.data.Dataset.zip( (ds_x , ds_y) )
if shuffle:
ds = ds.shuffle(1000)
return ds.batch(batch_size).cache().prefetch(tf.data.experimental.AUTOTUNE)
WINDOW_SIZE=5
#BATCH_SIZE=4
BATCH_SIZE=1 # Stateful일때는 Batch Size 는 1
filename = os.path.join('CheckPoint', 'ckeckpointer.ckpt')
model = Sequential([
# 1차원 feature map 생성
Conv1D(filters=32, kernel_size=5,
padding="causal",
activation="relu",
batch_input_shape=[1, WINDOW_SIZE, 4]),
# LSTM
LSTM(16, activation='tanh' , stateful = True),
Dropout(0.3),
Dense(16, activation="relu"),
Dense(1),
])
# Sequence 학습에 비교적 좋은 퍼포먼스를 내는 Huber()를 사용합니다.
loss = Huber()
optimizer = Adam(0.0005)
model.compile(loss=Huber(), optimizer=optimizer, metrics=['mse'])
# earlystopping은 10번 epoch통안 val_loss 개선이 없다면 학습을 멈춥니다.
earlystopping = EarlyStopping(monitor='val_loss', patience=10)
checkpoint = ModelCheckpoint(filename,
save_weights_only=True,
save_best_only=True,
monitor='val_loss',
verbose=1)
minMaxScaler = MinMaxScaler(feature_range=(0, 1))
t = train.drop(['id','time_step'] , axis=1 ).copy()
t
| breath_id | R | C | u_in | u_out | pressure | |
|---|---|---|---|---|---|---|
| 0 | 1 | 20 | 50 | 0.083334 | 0 | 5.837492 |
| 1 | 1 | 20 | 50 | 18.383041 | 0 | 5.907794 |
| 2 | 1 | 20 | 50 | 22.509278 | 0 | 7.876254 |
| 3 | 1 | 20 | 50 | 22.808822 | 0 | 11.742872 |
| 4 | 1 | 20 | 50 | 25.355850 | 0 | 12.234987 |
| ... | ... | ... | ... | ... | ... | ... |
| 6035995 | 125749 | 50 | 10 | 1.489714 | 1 | 3.869032 |
| 6035996 | 125749 | 50 | 10 | 1.488497 | 1 | 3.869032 |
| 6035997 | 125749 | 50 | 10 | 1.558978 | 1 | 3.798729 |
| 6035998 | 125749 | 50 | 10 | 1.272663 | 1 | 4.079938 |
| 6035999 | 125749 | 50 | 10 | 1.482739 | 1 | 3.869032 |
6036000 rows × 6 columns
minMaxScaler.fit(t)
MinMaxScaler()
t_scaled = minMaxScaler.transform(t)
t_scaled = pd.DataFrame(t_scaled)
t_scaled
| 0 | 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|---|
| 0 | 0.0 | 0.333333 | 1.0 | 0.000833 | 0.0 | 0.115911 |
| 1 | 0.0 | 0.333333 | 1.0 | 0.183830 | 0.0 | 0.116965 |
| 2 | 0.0 | 0.333333 | 1.0 | 0.225093 | 0.0 | 0.146470 |
| 3 | 0.0 | 0.333333 | 1.0 | 0.228088 | 0.0 | 0.204426 |
| 4 | 0.0 | 0.333333 | 1.0 | 0.253559 | 0.0 | 0.211802 |
| ... | ... | ... | ... | ... | ... | ... |
| 6035995 | 1.0 | 1.000000 | 0.0 | 0.014897 | 1.0 | 0.086407 |
| 6035996 | 1.0 | 1.000000 | 0.0 | 0.014885 | 1.0 | 0.086407 |
| 6035997 | 1.0 | 1.000000 | 0.0 | 0.015590 | 1.0 | 0.085353 |
| 6035998 | 1.0 | 1.000000 | 0.0 | 0.012727 | 1.0 | 0.089568 |
| 6035999 | 1.0 | 1.000000 | 0.0 | 0.014827 | 1.0 | 0.086407 |
6036000 rows × 6 columns
t_scaled.columns = ['0','1','2','3','4','5']
t_scaled
| 0 | 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|---|
| 0 | 0.0 | 0.333333 | 1.0 | 0.000833 | 0.0 | 0.115911 |
| 1 | 0.0 | 0.333333 | 1.0 | 0.183830 | 0.0 | 0.116965 |
| 2 | 0.0 | 0.333333 | 1.0 | 0.225093 | 0.0 | 0.146470 |
| 3 | 0.0 | 0.333333 | 1.0 | 0.228088 | 0.0 | 0.204426 |
| 4 | 0.0 | 0.333333 | 1.0 | 0.253559 | 0.0 | 0.211802 |
| ... | ... | ... | ... | ... | ... | ... |
| 6035995 | 1.0 | 1.000000 | 0.0 | 0.014897 | 1.0 | 0.086407 |
| 6035996 | 1.0 | 1.000000 | 0.0 | 0.014885 | 1.0 | 0.086407 |
| 6035997 | 1.0 | 1.000000 | 0.0 | 0.015590 | 1.0 | 0.085353 |
| 6035998 | 1.0 | 1.000000 | 0.0 | 0.012727 | 1.0 | 0.089568 |
| 6035999 | 1.0 | 1.000000 | 0.0 | 0.014827 | 1.0 | 0.086407 |
6036000 rows × 6 columns
t['R'] = t_scaled['1']
t['C'] = t_scaled['2']
t['u_in'] = t_scaled['3']
t['u_out'] = t_scaled['4']
t
| breath_id | R | C | u_in | u_out | pressure | |
|---|---|---|---|---|---|---|
| 0 | 1 | 0.333333 | 1.0 | 0.000833 | 0.0 | 5.837492 |
| 1 | 1 | 0.333333 | 1.0 | 0.183830 | 0.0 | 5.907794 |
| 2 | 1 | 0.333333 | 1.0 | 0.225093 | 0.0 | 7.876254 |
| 3 | 1 | 0.333333 | 1.0 | 0.228088 | 0.0 | 11.742872 |
| 4 | 1 | 0.333333 | 1.0 | 0.253559 | 0.0 | 12.234987 |
| ... | ... | ... | ... | ... | ... | ... |
| 6035995 | 125749 | 1.000000 | 0.0 | 0.014897 | 1.0 | 3.869032 |
| 6035996 | 125749 | 1.000000 | 0.0 | 0.014885 | 1.0 | 3.869032 |
| 6035997 | 125749 | 1.000000 | 0.0 | 0.015590 | 1.0 | 3.798729 |
| 6035998 | 125749 | 1.000000 | 0.0 | 0.012727 | 1.0 | 4.079938 |
| 6035999 | 125749 | 1.000000 | 0.0 | 0.014827 | 1.0 | 3.869032 |
6036000 rows × 6 columns
x_train, x_val, y_train, y_val = train_test_split( t.drop('pressure', 1),
t['pressure'],
test_size=0.005,
random_state=0,
shuffle=False )
<ipython-input-13-0a210ac6df78>:1: FutureWarning: In a future version of pandas all arguments of DataFrame.drop except for the argument 'labels' will be keyword-only
x_train, x_val, y_train, y_val = train_test_split( t.drop('pressure', 1),
breath_id = list( x_train['breath_id'].value_counts().reset_index()['index'] )
breath_id.sort()
x_val = x_val.drop(['breath_id'] , axis=1 ).copy()
x_val
| R | C | u_in | u_out | |
|---|---|---|---|---|
| 6005820 | 0.0 | 0.25 | 0.044443 | 1.0 |
| 6005821 | 0.0 | 0.25 | 0.045260 | 1.0 |
| 6005822 | 0.0 | 0.25 | 0.045960 | 1.0 |
| 6005823 | 0.0 | 0.25 | 0.046555 | 1.0 |
| 6005824 | 0.0 | 0.25 | 0.047062 | 1.0 |
| ... | ... | ... | ... | ... |
| 6035995 | 1.0 | 0.00 | 0.014897 | 1.0 |
| 6035996 | 1.0 | 0.00 | 0.014885 | 1.0 |
| 6035997 | 1.0 | 0.00 | 0.015590 | 1.0 |
| 6035998 | 1.0 | 0.00 | 0.012727 | 1.0 |
| 6035999 | 1.0 | 0.00 | 0.014827 | 1.0 |
30180 rows × 4 columns
val_ds = windowed_dataset( x_val , y_val , WINDOW_SIZE , BATCH_SIZE , False )
for epoch in range(5):
for b_id in breath_id:
train_b_id = x_train[ x_train['breath_id'] == b_id ]
train_b_id = train_b_id.drop(['breath_id'] , axis=1 ).copy()
train_ds = windowed_dataset( train_b_id , y_train , WINDOW_SIZE , BATCH_SIZE , False )
print("Breath ID : {0}".format(b_id))
history = model.fit(train_ds,
validation_data=(val_ds),
epochs=10,
callbacks=[checkpoint, earlystopping])
model.reset_states()
filename = "Save_iter_{}.h5".format(epoch)
model.save( filename )
Breath ID : 1
Epoch 1/10
71/Unknown - 5s 8ms/step - loss: 10.4798 - mse: 149.2300
---------------------------------------------------------------------------
KeyboardInterrupt Traceback (most recent call last)
<ipython-input-17-c7d14ad0602f> in <module>
10 print("Breath ID : {0}".format(b_id))
11
---> 12 history = model.fit(train_ds,
13 validation_data=(val_ds),
14 epochs=10,
~\Anaconda3\envs\TF.2.5.0-GPU\lib\site-packages\tensorflow\python\keras\engine\training.py in fit(self, x, y, batch_size, epochs, verbose, callbacks, validation_split, validation_data, shuffle, class_weight, sample_weight, initial_epoch, steps_per_epoch, validation_steps, validation_batch_size, validation_freq, max_queue_size, workers, use_multiprocessing)
1212 model=self,
1213 steps_per_execution=self._steps_per_execution)
-> 1214 val_logs = self.evaluate(
1215 x=val_x,
1216 y=val_y,
~\Anaconda3\envs\TF.2.5.0-GPU\lib\site-packages\tensorflow\python\keras\engine\training.py in evaluate(self, x, y, batch_size, verbose, sample_weight, steps, callbacks, max_queue_size, workers, use_multiprocessing, return_dict, **kwargs)
1487 with trace.Trace('test', step_num=step, _r=1):
1488 callbacks.on_test_batch_begin(step)
-> 1489 tmp_logs = self.test_function(iterator)
1490 if data_handler.should_sync:
1491 context.async_wait()
~\Anaconda3\envs\TF.2.5.0-GPU\lib\site-packages\tensorflow\python\eager\def_function.py in __call__(self, *args, **kwds)
887
888 with OptionalXlaContext(self._jit_compile):
--> 889 result = self._call(*args, **kwds)
890
891 new_tracing_count = self.experimental_get_tracing_count()
~\Anaconda3\envs\TF.2.5.0-GPU\lib\site-packages\tensorflow\python\eager\def_function.py in _call(self, *args, **kwds)
922 # In this case we have not created variables on the first call. So we can
923 # run the first trace but we should fail if variables are created.
--> 924 results = self._stateful_fn(*args, **kwds)
925 if self._created_variables:
926 raise ValueError("Creating variables on a non-first call to a function"
~\Anaconda3\envs\TF.2.5.0-GPU\lib\site-packages\tensorflow\python\eager\function.py in __call__(self, *args, **kwargs)
3021 (graph_function,
3022 filtered_flat_args) = self._maybe_define_function(args, kwargs)
-> 3023 return graph_function._call_flat(
3024 filtered_flat_args, captured_inputs=graph_function.captured_inputs) # pylint: disable=protected-access
3025
~\Anaconda3\envs\TF.2.5.0-GPU\lib\site-packages\tensorflow\python\eager\function.py in _call_flat(self, args, captured_inputs, cancellation_manager)
1958 and executing_eagerly):
1959 # No tape is watching; skip to running the function.
-> 1960 return self._build_call_outputs(self._inference_function.call(
1961 ctx, args, cancellation_manager=cancellation_manager))
1962 forward_backward = self._select_forward_and_backward_functions(
~\Anaconda3\envs\TF.2.5.0-GPU\lib\site-packages\tensorflow\python\eager\function.py in call(self, ctx, args, cancellation_manager)
589 with _InterpolateFunctionError(self):
590 if cancellation_manager is None:
--> 591 outputs = execute.execute(
592 str(self.signature.name),
593 num_outputs=self._num_outputs,
~\Anaconda3\envs\TF.2.5.0-GPU\lib\site-packages\tensorflow\python\eager\execute.py in quick_execute(op_name, num_outputs, inputs, attrs, ctx, name)
57 try:
58 ctx.ensure_initialized()
---> 59 tensors = pywrap_tfe.TFE_Py_Execute(ctx._handle, device_name, op_name,
60 inputs, attrs, num_outputs)
61 except core._NotOkStatusException as e:
KeyboardInterrupt:
1.2. return_sequences Example
- 전체 Sequence를 예측하는 Example
import numpy as np
import pandas as pd
import tensorflow as tf
import gc
import matplotlib.pyplot as plt
%matplotlib inline
from tensorflow import keras
from tensorflow.keras.layers import *
from tensorflow.keras import *
from tensorflow.keras.callbacks import LearningRateScheduler
from tensorflow.keras.optimizers.schedules import ExponentialDecay
from sklearn.preprocessing import RobustScaler, normalize
from sklearn.model_selection import train_test_split, KFold
from sklearn.metrics import mean_absolute_error
from pickle import load
import os
DEBUG = True
#DEBUG = False
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
submission = pd.read_csv('sample_submission.csv')
if DEBUG:
train = train[:80*1000]
train.shape, test.shape, submission.shape
((80000, 8), (4024000, 7), (4024000, 2))
def add_features(df):
df['area'] = df['time_step'] * df['u_in']
df['area'] = df.groupby('breath_id')['area'].cumsum()
df['u_in_cumsum'] = (df['u_in']).groupby(df['breath_id']).cumsum()
df['u_in_lag1'] = df.groupby('breath_id')['u_in'].shift(1)
df['u_out_lag1'] = df.groupby('breath_id')['u_out'].shift(1)
df['u_in_lag_back1'] = df.groupby('breath_id')['u_in'].shift(-1)
df['u_out_lag_back1'] = df.groupby('breath_id')['u_out'].shift(-1)
df['u_in_lag2'] = df.groupby('breath_id')['u_in'].shift(2)
df['u_out_lag2'] = df.groupby('breath_id')['u_out'].shift(2)
df['u_in_lag_back2'] = df.groupby('breath_id')['u_in'].shift(-2)
df['u_out_lag_back2'] = df.groupby('breath_id')['u_out'].shift(-2)
df['u_in_lag3'] = df.groupby('breath_id')['u_in'].shift(3)
df['u_out_lag3'] = df.groupby('breath_id')['u_out'].shift(3)
df['u_in_lag_back3'] = df.groupby('breath_id')['u_in'].shift(-3)
df['u_out_lag_back3'] = df.groupby('breath_id')['u_out'].shift(-3)
df['u_in_lag4'] = df.groupby('breath_id')['u_in'].shift(4)
df['u_out_lag4'] = df.groupby('breath_id')['u_out'].shift(4)
df['u_in_lag_back4'] = df.groupby('breath_id')['u_in'].shift(-4)
df['u_out_lag_back4'] = df.groupby('breath_id')['u_out'].shift(-4)
df = df.fillna(0)
df['breath_id__u_in__max'] = df.groupby(['breath_id'])['u_in'].transform('max')
df['breath_id__u_out__max'] = df.groupby(['breath_id'])['u_out'].transform('max')
df['u_in_diff1'] = df['u_in'] - df['u_in_lag1']
df['u_out_diff1'] = df['u_out'] - df['u_out_lag1']
df['u_in_diff2'] = df['u_in'] - df['u_in_lag2']
df['u_out_diff2'] = df['u_out'] - df['u_out_lag2']
df['breath_id__u_in__diffmax'] = df.groupby(['breath_id'])['u_in'].transform('max') - df['u_in']
df['breath_id__u_in__diffmean'] = df.groupby(['breath_id'])['u_in'].transform('mean') - df['u_in']
df['breath_id__u_in__diffmax'] = df.groupby(['breath_id'])['u_in'].transform('max') - df['u_in']
df['breath_id__u_in__diffmean'] = df.groupby(['breath_id'])['u_in'].transform('mean') - df['u_in']
df['u_in_diff3'] = df['u_in'] - df['u_in_lag3']
df['u_out_diff3'] = df['u_out'] - df['u_out_lag3']
df['u_in_diff4'] = df['u_in'] - df['u_in_lag4']
df['u_out_diff4'] = df['u_out'] - df['u_out_lag4']
df['cross']= df['u_in']*df['u_out']
df['cross2']= df['time_step']*df['u_out']
df['R'] = df['R'].astype(str)
df['C'] = df['C'].astype(str)
df['R__C'] = df["R"].astype(str) + '__' + df["C"].astype(str)
df = pd.get_dummies(df)
return df
- 이 Dataset은 80개의 Data가 하나의 Sequence이어서 80개씩 나눈다.
targets = train['pressure'].to_numpy().reshape(-1, 80)
targets.shape
(1000, 80)
train.drop(labels='pressure', axis=1, inplace=True)
train.head()
| id | breath_id | R | C | time_step | u_in | u_out | |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 20 | 50 | 0.000000 | 0.083334 | 0 |
| 1 | 2 | 1 | 20 | 50 | 0.033652 | 18.383041 | 0 |
| 2 | 3 | 1 | 20 | 50 | 0.067514 | 22.509278 | 0 |
| 3 | 4 | 1 | 20 | 50 | 0.101542 | 22.808822 | 0 |
| 4 | 5 | 1 | 20 | 50 | 0.135756 | 25.355850 | 0 |
train = add_features(train)
train.head()
| id | breath_id | time_step | u_in | u_out | area | u_in_cumsum | u_in_lag1 | u_out_lag1 | u_in_lag_back1 | ... | C_50 | R__C_20__10 | R__C_20__20 | R__C_20__50 | R__C_50__10 | R__C_50__20 | R__C_50__50 | R__C_5__10 | R__C_5__20 | R__C_5__50 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 0.000000 | 0.083334 | 0 | 0.000000 | 0.083334 | 0.000000 | 0.0 | 18.383041 | ... | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 2 | 1 | 0.033652 | 18.383041 | 0 | 0.618632 | 18.466375 | 0.083334 | 0.0 | 22.509278 | ... | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 3 | 1 | 0.067514 | 22.509278 | 0 | 2.138333 | 40.975653 | 18.383041 | 0.0 | 22.808822 | ... | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 4 | 1 | 0.101542 | 22.808822 | 0 | 4.454391 | 63.784476 | 22.509278 | 0.0 | 25.355850 | ... | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 5 | 1 | 0.135756 | 25.355850 | 0 | 7.896588 | 89.140326 | 22.808822 | 0.0 | 27.259866 | ... | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
5 rows × 52 columns
# normalise the dataset
RS = RobustScaler()
train = RS.fit_transform(train)
# Reshape to group 80 timesteps for each breath ID
train = train.reshape(-1, 80, train.shape[-1])
train.shape
(1000, 80, 52)
test = add_features(test)
test = RS.transform(test)
test = test.reshape(-1, 80, test.shape[-1])
train.shape, test.shape
((1000, 80, 52), (50300, 80, 52))
train.shape[-2], train.shape[-1]
(80, 52)
-
이 Model은 80개의 Time Stamp를 전부 받아서 각 Cell의 Output을 한 번에 모두 받고, 그 결과를 Target과 비교하는 방식을 사용
-
이를 위해 return_sequences = True를 사용
def create_lstm_model():
x0 = tf.keras.layers.Input(shape=(train.shape[-2], train.shape[-1]))
lstm_layers = 4 # number of LSTM layers
lstm_units = [320, 305, 304, 229]
lstm = Bidirectional(keras.layers.LSTM(lstm_units[0], return_sequences=True))(x0)
for i in range(lstm_layers-1):
lstm = Bidirectional(keras.layers.LSTM(lstm_units[i+1], return_sequences=True))(lstm)
lstm = Dropout(0.001)(lstm)
lstm = Dense(100, activation='relu')(lstm)
lstm = Dense(1)(lstm)
model = keras.Model(inputs=x0, outputs=lstm)
model.compile(optimizer="adam", loss="mae")
return model
EPOCH = 350
#BATCH_SIZE = 512
BATCH_SIZE = 32
NFOLDS = 5
kf = KFold(n_splits=NFOLDS, shuffle=True, random_state=2021)
history = []
test_preds = []
for fold, (train_idx, test_idx) in enumerate(kf.split(train, targets)):
print('-'*15, '>', f'Fold {fold+1}', '<', '-'*15)
X_train, X_valid = train[train_idx], train[test_idx]
y_train, y_valid = targets[train_idx], targets[test_idx]
model = create_lstm_model()
model.compile(optimizer="adam", loss="mae", metrics=[tf.keras.metrics.MeanAbsolutePercentageError()])
scheduler = ExponentialDecay(1e-3, 400*((len(train)*0.8)/BATCH_SIZE), 1e-5)
lr = LearningRateScheduler(scheduler, verbose=0)
history.append(model.fit(X_train, y_train,
validation_data=(X_valid, y_valid),
epochs=EPOCH, batch_size=BATCH_SIZE, callbacks=[lr]))
test_pred = model.predict(test).squeeze().reshape(-1, 1).squeeze()
test_preds.append(test_pred)
# save model
#model.save("lstm_model_fold_{}".format(fold))
del X_train, X_valid, y_train, y_valid, model
gc.collect()
--------------- > Fold 1 < ---------------
Epoch 1/350
25/25 [==============================] - ETA: 0s - loss: 4.3909 - mean_absolute_percentage_error: 34.6729
---------------------------------------------------------------------------
KeyboardInterrupt Traceback (most recent call last)
<ipython-input-18-5f29b2338821> in <module>
13 lr = LearningRateScheduler(scheduler, verbose=0)
14
---> 15 history.append(model.fit(X_train, y_train,
16 validation_data=(X_valid, y_valid),
17 epochs=EPOCH, batch_size=BATCH_SIZE, callbacks=[lr]))
~\Anaconda3\envs\TF.2.5.0-GPU\lib\site-packages\tensorflow\python\keras\engine\training.py in fit(self, x, y, batch_size, epochs, verbose, callbacks, validation_split, validation_data, shuffle, class_weight, sample_weight, initial_epoch, steps_per_epoch, validation_steps, validation_batch_size, validation_freq, max_queue_size, workers, use_multiprocessing)
1212 model=self,
1213 steps_per_execution=self._steps_per_execution)
-> 1214 val_logs = self.evaluate(
1215 x=val_x,
1216 y=val_y,
~\Anaconda3\envs\TF.2.5.0-GPU\lib\site-packages\tensorflow\python\keras\engine\training.py in evaluate(self, x, y, batch_size, verbose, sample_weight, steps, callbacks, max_queue_size, workers, use_multiprocessing, return_dict, **kwargs)
1487 with trace.Trace('test', step_num=step, _r=1):
1488 callbacks.on_test_batch_begin(step)
-> 1489 tmp_logs = self.test_function(iterator)
1490 if data_handler.should_sync:
1491 context.async_wait()
~\Anaconda3\envs\TF.2.5.0-GPU\lib\site-packages\tensorflow\python\eager\def_function.py in __call__(self, *args, **kwds)
887
888 with OptionalXlaContext(self._jit_compile):
--> 889 result = self._call(*args, **kwds)
890
891 new_tracing_count = self.experimental_get_tracing_count()
~\Anaconda3\envs\TF.2.5.0-GPU\lib\site-packages\tensorflow\python\eager\def_function.py in _call(self, *args, **kwds)
922 # In this case we have not created variables on the first call. So we can
923 # run the first trace but we should fail if variables are created.
--> 924 results = self._stateful_fn(*args, **kwds)
925 if self._created_variables:
926 raise ValueError("Creating variables on a non-first call to a function"
~\Anaconda3\envs\TF.2.5.0-GPU\lib\site-packages\tensorflow\python\eager\function.py in __call__(self, *args, **kwargs)
3021 (graph_function,
3022 filtered_flat_args) = self._maybe_define_function(args, kwargs)
-> 3023 return graph_function._call_flat(
3024 filtered_flat_args, captured_inputs=graph_function.captured_inputs) # pylint: disable=protected-access
3025
~\Anaconda3\envs\TF.2.5.0-GPU\lib\site-packages\tensorflow\python\eager\function.py in _call_flat(self, args, captured_inputs, cancellation_manager)
1958 and executing_eagerly):
1959 # No tape is watching; skip to running the function.
-> 1960 return self._build_call_outputs(self._inference_function.call(
1961 ctx, args, cancellation_manager=cancellation_manager))
1962 forward_backward = self._select_forward_and_backward_functions(
~\Anaconda3\envs\TF.2.5.0-GPU\lib\site-packages\tensorflow\python\eager\function.py in call(self, ctx, args, cancellation_manager)
589 with _InterpolateFunctionError(self):
590 if cancellation_manager is None:
--> 591 outputs = execute.execute(
592 str(self.signature.name),
593 num_outputs=self._num_outputs,
~\Anaconda3\envs\TF.2.5.0-GPU\lib\site-packages\tensorflow\python\eager\execute.py in quick_execute(op_name, num_outputs, inputs, attrs, ctx, name)
57 try:
58 ctx.ensure_initialized()
---> 59 tensors = pywrap_tfe.TFE_Py_Execute(ctx._handle, device_name, op_name,
60 inputs, attrs, num_outputs)
61 except core._NotOkStatusException as e:
KeyboardInterrupt:
submission["pressure"] = sum(test_preds)/5
submission.to_csv('submission.csv', index=False)