A Comprehensive Study of Deep Video Action Recognition
A Comprehensive Study of Deep Video Action Recognition
1. Introduction
video understanding에서 가장 중요한 작업 중 하나는 인간의 행동을 이해하는 것입니다.
( One of the most important tasks in video understanding is to understand human actions. )
행동 분석, 비디오 검색, 인간-로봇 상호 작용, 게임 및 엔터테인먼트를 포함한 많은 실제 응용 프로그램이 있습니다.
( It has many real-world applications, including behavior analysis, video retrieval, human-robot interaction, gaming, and entertainment. )
인간 행동 이해에는 인간 행동을 인식, 지역화 및 예측하는 것이 포함됩니다.
( Human action understanding involves recognizing, localizing, and predicting human behaviors. )
동영상에서 사람의 행동을 인식하는 작업을 동영상 행동 인식이라고 합니다.
( The task to recognize human actions in a video is called video action recognition. )
그림 1에서는 악수 및 자전거 타기와 같은 일반적인 인간의 일상 활동인 관련 작업 레이블이 있는 여러 비디오 프레임을 시각화합니다.
( In Figure 1, we visualize several video frames with the associated action labels, which are typical human daily activities such as shaking hands and riding a bike. )

지난 10년 동안 고품질의 대규모 동작 인식 데이터 세트의 등장으로 비디오 동작 인식에 대한 연구 관심이 높아졌습니다.
( Over the last decade, there has been growing research interest in video action recognition with the emergence of high-quality large-scale action recognition datasets. )
인기 있는 동작 인식 데이터 세트의 통계를 그림 2에 요약했습니다.
( We summarize the statistics of popular action recognition datasets in Figure 2. )
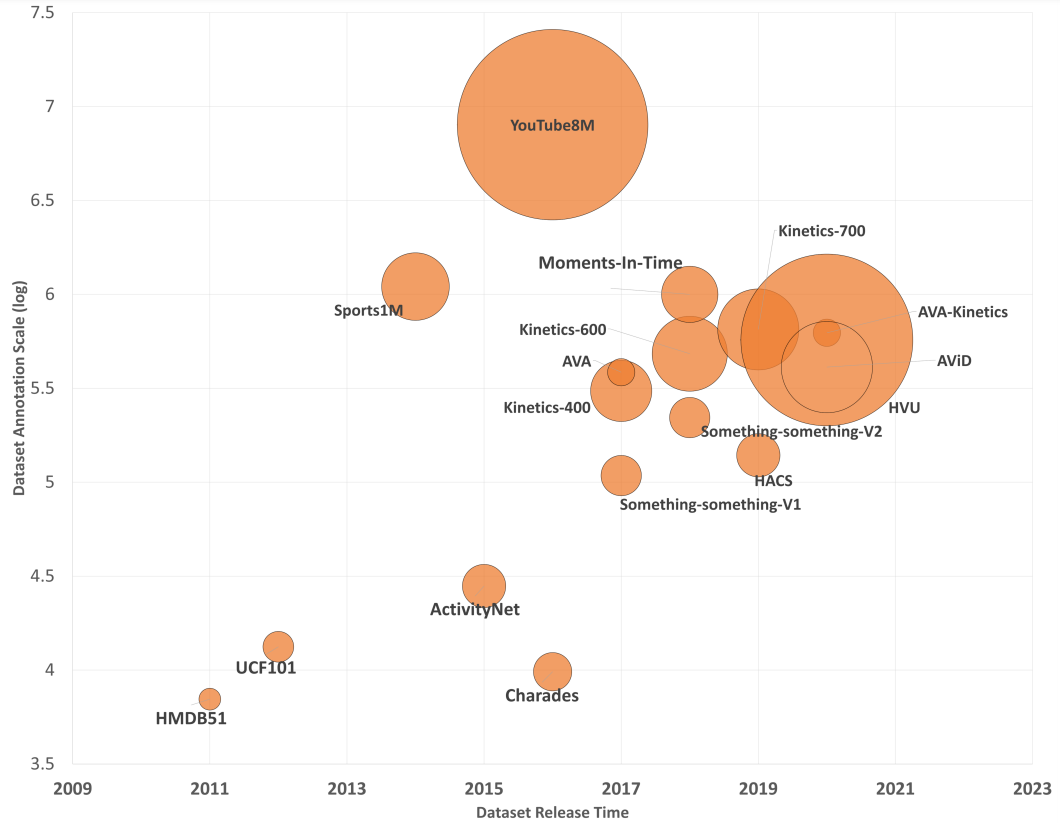
예를 들어 HMDB51[109]의 51개 클래스에 대한 7K 비디오에서 YouTube8M[1]의 3,862개 클래스에 대한 8M 비디오로 비디오 및 클래스의 수 모두 빠르게 증가하는 것을 볼 수 있습니다. 또한 새로운 데이터세트가 공개되는 비율이 증가하고 있습니다. 2016년부터 2020년까지 13개의 데이터세트가 공개된 것에 비해 2011년부터 2015년까지 3개의 데이터세트가 공개되었습니다.
( We see that both the number of videos and classes increase rapidly, e.g, from 7K videos over 51 classes in HMDB51 [109] to 8M videos over 3, 862 classes in YouTube8M [1]. Also, the rate at which new datasets are released is increasing: 3 datasets were released from 2011 to 2015 compared to 13 released from 2016 to 2020.)
대규모 데이터 세트의 가용성과 딥 러닝의 급속한 발전 덕분에 비디오 동작을 인식하는 딥 러닝 기반 모델도 빠르게 성장하고 있습니다.
( Thanks to both the availability of large-scale datasets and the rapid progress in deep learning, there is also a rapid growth in deep learning based models to recognize video actions. )
그림 3에서 우리는 최근 대표 작업의 연대순 개요를 제시합니다.
( In Figure 3, we present a chronological overview of recent representative work. )
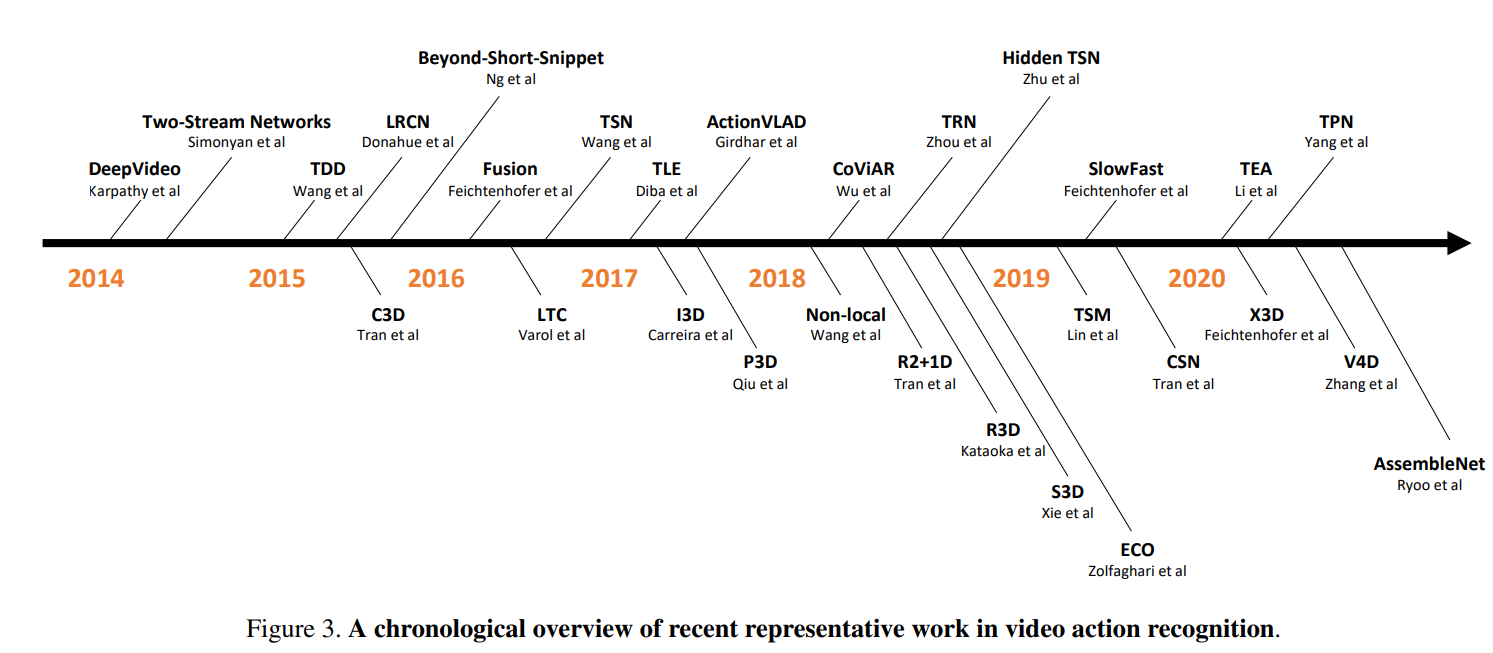
DeepVideo[99]는 convolutional neural networks를 비디오에 적용하려는 초기 시도 중 하나입니다.
( DeepVideo [99] is one of the earliest attempts to apply convolutional neural networks to videos. )
우리는 세가지 트렌드를 확인하였다.
( We observed three trends here. )
Two-Stream Networks[187]에 대한 중요한 논문에서 시작된 첫 번째 추세는 optical flow stream에서 convolutional neural network을 훈련하여 비디오의 시간 정보를 학습하는 두 번째 경로를 추가하는 것입니다.
( The first trend started by the seminal paper on Two-Stream Networks [187], adds a second path to learn the temporal information in a video by training a convolutional neural network on the optical flow stream. )
그것의 큰 성공은 TDD[214], LRCN[37], Fusion[50], TSN[218] 등과 같은 많은 후속 논문에 영감을 주었습니다.
( Its great success inspired a large number of follow-up papers, such as TDD [214], LRCN [37], Fusion [50], TSN [218], etc. )
두 번째 경향은 I3D[14], R3D[74], S3D[239], Non-local[219], SlowFast[45] 등과 같은 비디오 시간 정보를 모델링하기 위해 3D convolutional kernels을 사용하는 것입니다.
( The second trend was the use of 3D convolutional kernels to model video temporal information, such as I3D [14], R3D [74], S3D [239], Non-local [219], SlowFast [45], etc. )
마지막으로 세 번째 트렌드는 실제 애플리케이션에 채택될 수 있도록 훨씬 더 큰 데이터 세트로 확장할 수 있는 계산 효율성에 중점을 두었습니다.
( Finally, the third trend focused on computational efficiency to scale to even larger datasets so that they could be adopted in real applications. )
Hidden TSN[278], TSM[128], X3D[44], TVN[161] 등을 예로 들 수 있습니다.
( Examples include Hidden TSN [278], TSM [128], X3D [44], TVN [161], etc. )
비디오 동작 인식을 위한 많은 수의 딥 러닝 기반 모델에도 불구하고 이러한 모델에 대한 포괄적인 조사는 없습니다.
( Despite the large number of deep learning based models for video action recognition, there is no comprehensive survey dedicated to these models. )
이전 Survey Paper들은 hand-crafted features에 더 공을 들이거나 비디오 캡션[236], 비디오 예측[104], 비디오 동작 감지[261] 및 제로 샷 비디오 동작 인식[ 96].등과 같은 광범위한 주제에 중점을 두었으나,
( Previous survey papers either put more efforts into hand-crafted features [77, 173] or focus on broader topics such as video captioning [236], video prediction [104], video action detection [261] and zero-shot video action recognition [96]. )
이 Paper에서는 다음와 같은 것들에 중점을 둔다.
( In this paper: )
- 영상 동작 인식을 위한 딥러닝에 관한 200편 이상의 논문을 종합적으로 검토합니다. 우리는 독자들에게 최신 발전을 시간순으로 체계적으로 설명하고 인기 있는 논문을 자세히 설명합니다. ( We comprehensively review over 200 papers on deep learning for video action recognition. We walk the readers through the recent advancements chronologically and systematically, with popular papers explained in detail. )
- 우리는 정확성과 효율성 측면에서 동일한 데이터 세트에 대해 널리 채택된 방법을 벤치마킹합니다. 또한 완전한 재현성을 위해 구현을 릴리스합니다. ( We benchmark widely adopted methods on the same set of datasets in terms of both accuracy and efficiency. We also release our implementations for full reproducibility.)
- 우리는 향후 연구를 촉진하기 위해 이 분야의 도전 과제, 열린 문제 및 기회에 대해 자세히 설명합니다. ( We elaborate on challenges, open problems, and opportunities in this field to facilitate future research. )
The rest of the survey is organized as following.
먼저 섹션 2에서 벤치마킹 및 기존 문제에 사용되는 인기 있는 데이터 세트에 대해 설명합니다.
( We first describe popular datasets used for benchmarking and existing challenges in section 2. )
그런 다음 이 설문 조사의 주요 기여인 섹션 3에서 비디오 동작 인식을 위한 딥 러닝을 사용한 최근 발전을 제시합니다.
( Then we present recent advancements using deep learning for video action recognition in section 3, which is the major contribution of this survey. )
섹션 4에서는 표준 벤치마크 데이터 세트에 대해 널리 채택된 접근 방식을 평가하고 섹션 5에서는 논의 및 향후 연구 기회를 제공합니다.
( In section 4, we evaluate widely adopted approaches on standard benchmark datasets, and provide discussions and future research opportunities in section 5. )
2. Datasets and Challenges
2.1. Datasets
딥 러닝 방법은 일반적으로 training data의 양이 증가하면 정확도가 향상됩니다.
( Deep learning methods usually improve in accuracy when the volume of the training data grows. )
video action recognition의 경우 이는 효과적인 모델을 학습하기 위해 large-scale annotated datasets가 필요함을 의미합니다.
( In the case of video action recognition, this means we need large-scale annotated datasets to learn effective models.)
비디오 동작 인식 작업을 위해 데이터 세트는 종종 다음 프로세스에 의해 구축됩니다.
For the task of video action recognition, datasets are often built by the following process:
(1) 이전 동작 인식 데이터 세트의 레이블을 결합하고 사용 사례에 따라 새 범주를 추가하여 동작 목록을 정의합니다.
( Define an action list, by combining labels from previous action recognition datasets and adding new categories depending on the use case. )
(2) YouTube나 영화와 같은 다양한 Source로부터 Video를 얻고 제목이나 부제목을 연관시켜 Action List를 만듭니다.
( Obtain videos from various sources, such as YouTube and movies, by matching the video title/subtitle to the action list. )
(3) 동작의 시작 및 종료 위치를 나타내기 위해 수동으로 임시 주석을 제공하고
( Provide temporal annotations manually to indicate the start and end position of the action, and )
(4) 마지막으로 중복 제거를 통해 데이터 세트를 정리하고 잡음이 많은 클래스/샘플을 필터링합니다.
( finally clean up the dataset by de-duplication and filtering out noisy classes/samples. )
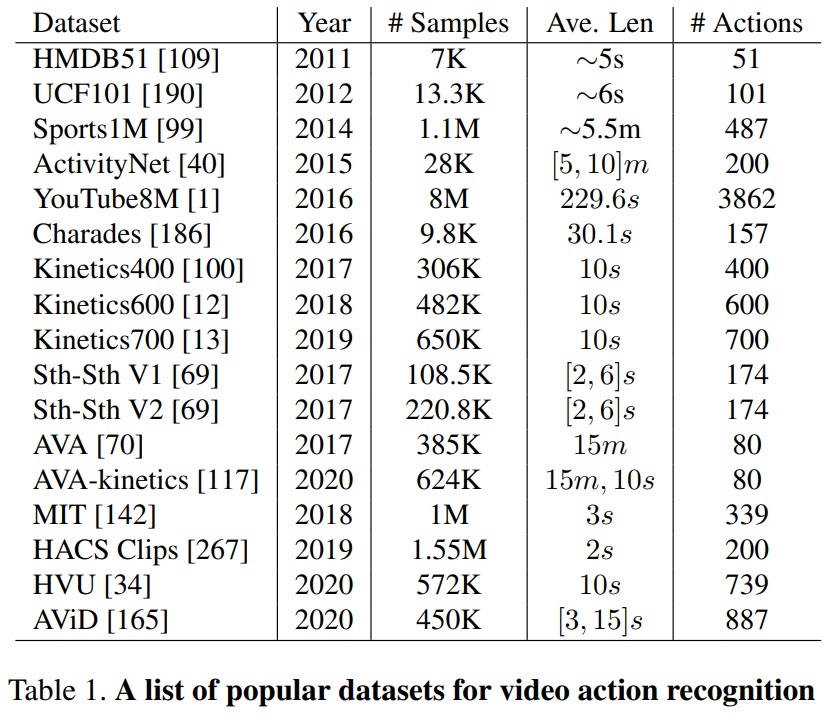
아래 표 1과 그림 2에서 가장 인기 있는 대규모 비디오 동작 인식 데이터 세트를 검토합니다.
Below we review the most popular large-scale video action recognition datasets in Table 1 and Figure 2.
HMDB51[109]은 2011년에 도입되었습니다. 주로 영화에서 수집되었으며 Prelinger 아카이브, YouTube 및 Google 비디오와 같은 공공 데이터베이스에서 작은 비율로 수집되었습니다.
( HMDB51 [109] was introduced in 2011. It was collected mainly from movies, and a small proportion from public databases such as the Prelinger archive, YouTube and Google videos. )
데이터 세트에는 51개의 action categories로 나누어진 6,849개의 클립이 포함되어 있으며 각 범주에는 최소 101개의 클립이 포함되어 있습니다.
The dataset contains 6, 849 clips divided into 51 action categories, each containing a minimum of 101 clips.
데이터 세트에는 세 가지 공식 분할이 있습니다. 대부분의 이전 논문은 분할 1에서 상위 1위 분류 정확도 또는 세 분할에 대한 평균 정확도를 보고합니다.
The dataset has three official splits. Most previous papers either report the top-1 classification accuracy on split 1 or the average accuracy over three splits.
UCF101[190]은 2012년에 나왔으며 이전 UCF50 데이터 세트의 확장입니다.
UCF101 [190] was introduced in 2012 and is an extension of the previous UCF50 dataset.
여기에는 101개 범주의 인간 행동에 대한 YouTube의 13,320개 동영상이 포함되어 있습니다.
It contains 13, 320 videos from YouTube spreading over 101 categories of human actions.
데이터 세트에는 HMDB51과 유사한 3개의 공식 분할이 있으며 동일한 방식으로 평가됩니다.
The dataset has three official splits similar to HMDB51, and is also evaluated in the same manner.
Sports1M [99]은 2014년에 487개의 스포츠 클래스로 주석이 달린 100만 개 이상의 YouTube 동영상으로 구성된 최초의 대규모 동영상 작업 데이터 세트로 소개되었습니다.
Sports1M [99] was introduced in 2014 as the first largescale video action dataset which consisted of more than 1 million YouTube videos annotated with 487 sports classes.
categories는 세분화되어 클래스 간 변동이 적습니다. 평가를 위한 공식적인 10배 교차 검증 분할이 있습니다.
The categories are fine-grained which leads to low interclass variations. It has an official 10-fold cross-validation split for evaluation.
ActivityNet[40]은 2015년에 처음 소개되었으며 ActivityNet family는 초기 출시 이후 여러 버전이 있습니다.
ActivityNet [40] was originally introduced in 2015 and the ActivityNet family has several versions since its initial launch.
최신 ActivityNet 200(V1.3)에는 200개의 인간 일상 생활 동작이 포함되어 있습니다. 10,024개의 Train, 4,926개의 Validation 및 5,044개의 Test 비디오가 있습니다.
The most recent ActivityNet 200 (V1.3) contains 200 human daily living actions. It has 10, 024 training, 4, 926 validation, and 5, 044 testing videos.
평균적으로 class당 137개의 트리밍되지 않은 비디오와 비디오당 1.41개의 활동 인스턴스가 있습니다.
On average there are 137 untrimmed videos per class and 1.41 activity instances per video.
YouTube8M [1]은 2016년에 소개되었으며 800만 개의 YouTube 동영상(총 500K 시간의 동영상)을 포함하고 3,862개의 action classes로 주석이 달린 최대 규모의 동영상 데이터 세트입니다.
YouTube8M [1] was introduced in 2016 and is by far the largest-scale video dataset that contains 8 million YouTube videos (500K hours of video in total) and annotated with 3, 862 action classes.
각 비디오는 YouTube 비디오 주석 시스템에 의해 하나 이상의 레이블로 주석이 추가되었습니다.
Each video is annotated with one or multiple labels by a YouTube video annotation system.
이 데이터 세트는 70:20:10 비율로 교육, 검증 및 테스트로 나누어져 있습니다.
This dataset is split into training, validation and test in the ratio 70:20:10.
이 데이터 세트의 검증 세트는 사람이 검증한 세그먼트 주석으로 확장되어 시간적 현지화 정보를 제공합니다.
The validation set of this dataset is also extended with human-verified segment annotations to provide temporal localization information.
Charades [186]는 실제 동시 행동 이해를 위한 데이터 세트로 2016년에 소개되었습니다.
Charades [186] was introduced in 2016 as a dataset for real-life concurrent action understanding.
평균 길이가 30초인 9,848개의 동영상이 포함되어 있습니다.
It contains 9, 848 videos with an average length of 30 seconds.
이 데이터 세트에는 267명의 서로 다른 사람들이 수행한 157개의 다중 레이블 일일 실내 활동이 포함되어 있습니다.
This dataset includes 157 multi-label daily indoor activities, performed by 267 different people.
7,985개의 Train 비디오와 validation 검사를 위한 나머지 1,863개로 나누어져 있습니다.
It has an official train-validation split that has 7, 985 videos for training and the remaining 1, 863 for validation.
Kinetics Family은 현재 가장 널리 채택된 벤치마크입니다. Kinetics400[100]은 2017년에 소개되었으며 400개의 인간 행동 범주에서 10초로 트리밍된 약 240k개의 교육 및 20k 검증 비디오로 구성됩니다.
Kinetics Family is now the most widely adopted benchmark. Kinetics400 [100] was introduced in 2017 and it consists of approximately 240k training and 20k validation videos trimmed to 10 seconds from 400 human action categories.
Kinetics 제품군은 2018년에 480K 비디오로 출시된 Kinetics-600[12]과 2019년 650K 비디오로 출시된 Kinetics700[13]으로 계속 확장되고 있습니다.
The Kinetics family continues to expand, with Kinetics-600 [12] released in 2018 with 480K videos and Kinetics700[13] in 2019 with 650K videos.
20BN-Something-Something [69] V1은 2017년에, V2는 2018년에 소개되었습니다.
20BN-Something-Something [69] V1 was introduced in 2017 and V2 was introduced in 2018.
이 계열은 인간이 일상적인 물건으로 기본 동작을 수행하는 것을 설명하는 174개의 동작 클래스로 구성된 또 다른 인기 있는 벤치마크입니다.
This family is another popular benchmark that consists of 174 action classes that describe humans performing basic actions with everyday objects.
V1에는 108,499개의 비디오가 있고 V2에는 220,847개의 비디오가 있습니다.
There are 108, 499 videos in V1 and 220, 847 videos in V2.
Something-Something 데이터 세트는 대부분의 활동이 공간적 특징만으로는 유추될 수 없기 때문에 강력한 시간 모델링이 필요합니다(예: 무언가 열기, 무언가로 무언가 덮기).
Note that the Something-Something dataset requires strong temporal modeling because most activities cannot be inferred based on spatial features alone (e.g. opening something, covering something with something).
AVA[70]는 2017년 최초의 대규모 spatio-temporal action detection dataset로 도입되었습니다.
AVA [70] was introduced in 2017 as the first large-scale spatio-temporal action detection dataset.
여기에는 80개의 원자 작업 레이블이 있는 430개의 15분 비디오 클립이 포함되어 있습니다(60개의 레이블만 평가에 사용됨).
It contains 430 15-minute video clips with 80 atomic actions labels (only 60 labels were used for evaluation).
주석은 214,622개의 Train, 57,472개의 Validation 및 120,322개의 Test 샘플로 이어지는 각 키 프레임에서 제공되었습니다.
The annotations were provided at each key-frame which lead to 214, 622 training, 57, 472 validation and 120, 322 testing samples.
AVA 데이터 세트는 최근 352,091개의 훈련, 89,882개의 검증 및 182,457개의 테스트 샘플이 있는 AVA-Kinetics로 확장되었습니다[117].
The AVA dataset was recently expanded to AVA-Kinetics with 352, 091 training, 89, 882 validation and 182, 457 testing samples [117].
Moments in Time [142]은 2018년에 소개되었으며 이벤트 이해를 위해 설계된 대규모 데이터 세트입니다.
Moments in Time [142] was introduced in 2018 and it is a large-scale dataset designed for event understanding.
여기에는 339개 클래스의 사전으로 주석이 달린 백만 개의 3초 비디오 클립이 포함되어 있습니다.
It contains one million 3 second video clips, annotated with a dictionary of 339 classes.
인간 행동 이해를 위해 설계된 다른 데이터 세트와 달리 Moments in Time 데이터 세트는 사람, 동물, 사물 및 자연 현상을 포함합니다.
Different from other datasets designed for human action understanding, Moments in Time dataset involves people, animals, objects and natural phenomena.
데이터 세트는 2019년에 비디오 수를 102만 개로 늘리고 모호한 클래스를 정리하고 비디오당 레이블 수를 늘려 M-MiT(Multi-Moments in Time) [143]로 확장되었습니다.
The dataset was extended to Multi-Moments in Time (M-MiT) [143] in 2019 by increasing the number of videos to 1.02 million, pruning vague classes, and increasing the number of labels per video.
HACS[267]는 웹 비디오에서 수집된 인간 행동의 인식 및 현지화를 위한 새로운 대규모 데이터 세트로 2019년에 소개되었습니다.
HACS [267] was introduced in 2019 as a new large-scale dataset for recognition and localization of human actions collected from Web videos.
두 종류의 manual annotations으로 구성됩니다.
It consists of two kinds of manual annotations.
HACS 클립에는 504K 비디오에 대한 155만 개의 2초 클립 주석이 포함되어 있으며 HACS 세그먼트에는 50K 비디오에 대한 140K개의 완전한 동작 세그먼트(동작 시작부터 끝까지)가 있습니다.
HACS Clips contains 1.55M 2-second clip annotations on 504K videos, and HACS Segments has 140K complete action segments (from action start to end) on 50K videos.
비디오는 ActivityNet(V1.3)[40]에서 사용되는 것과 동일한 200개의 인간 행동 클래스로 주석이 추가됩니다.
The videos are annotated with the same 200 human action classes used in ActivityNet (V1.3) [40].
HVU [34] 데이터 세트는 multi-label multi-task video understanding를 위해 2020년에 릴리스되었습니다.
HVU [34] dataset was released in 2020 for multi-label multi-task video understanding.
이 데이터세트에는 572,000개의 동영상과 3,142개의 라벨이 있습니다.
This dataset has 572K videos and 3, 142 labels.
공식 분할에는 훈련, 검증 및 테스트를 위한 각각 481K, 31K 및 65K 비디오가 있습니다.
The official split has 481K, 31K and 65K videos for train, validation, and test respectively.
이 데이터 세트에는 장면, 개체, 동작, 이벤트, 특성 및 개념의 6가지 작업 범주가 있습니다.
This dataset has six task categories: scene, object, action, event, attribute, and concept.
평균적으로 각 레이블에 대해 약 2,112개의 샘플이 있습니다.
On average, there are about 2, 112 samples for each label.
동영상 재생 시간은 최대 10초로 다양합니다.
The duration of the videos varies with a maximum length of 10 seconds.
AViD[165]는 2020년 익명화된 동작 인식을 위한 데이터 세트로 도입되었습니다.
AViD [165] was introduced in 2020 as a dataset for anonymized action recognition.
여기에는 training용 410K 비디오와 testing용 40K 비디오가 포함되어 있습니다.
It contains 410K videos for training and 40K videos for testing.
각 비디오 클립 길이는 3-15초이며 총 887개의 액션 클래스가 있습니다.
Each video clip duration is between 3-15 seconds and in total it has 887 action classes.
데이터 수집 중에 저자는 데이터 편향을 처리하기 위해 여러 국가에서 데이터를 수집하려고 했습니다.
During data collection, the authors tried to collect data from various countries to deal with data bias.
또한 비디오 제작자의 개인 정보를 보호하기 위해 얼굴 ID를 제거합니다.
They also remove face identities to protect privacy of video makers.
따라서 AViD 데이터 세트는 얼굴 관련 동작을 인식하기 위한 적절한 선택이 아닐 수 있습니다.
Therefore, AViD dataset might not be a proper choice for recognizing face-related actions.
방법들을 시간순으로 검토하기 전에 그림 4에 있는 위 데이터 세트의 몇 가지 시각적 예를 제시하여 서로 다른 특성을 보여줍니다.
Before we dive into the chronological review of methods, we present several visual examples from the above datasets in Figure 4 to show their different characteristics.

상단 두 행에서 UCF101 [190] 및 Kinetics400 [100] 데이터 세트에서 작업 클래스를 선택합니다.
In the top two rows, we pick action classes from UCF101 [190] and Kinetics400 [100] datasets.
흥미롭게도 우리는 이러한 행동이 때때로 맥락이나 장면에 의해서만 결정될 수 있다는 것을 발견했습니다.
Interestingly, we find that these actions can sometimes be determined by the context or scene alone.
예를 들어 모델은 비디오 프레임에서 자전거를 인식하는 한 자전거를 타는 동작을 예측할 수 있습니다.
For example, the model can predict the action riding a bike as long as it recognizes a bike in the video frame.
모델은 크리켓 경기장을 인식하는 경우 액션 크리켓 볼링을 예측할 수도 있습니다.
The model may also predict the action cricket bowling if it recognizes the cricket pitch.
따라서 이러한 클래스의 경우 비디오 동작 인식은 동작/시간 정보를 추론할 필요 없이 개체/장면 분류 문제가 될 수 있습니다.
Hence for these classes, video action recognition may become an object/scene classification problem without the need of reasoning motion/temporal information.
중간 두 행에서 Something-Something 데이터 세트 [69]에서 작업 클래스를 선택합니다.
In the middle two rows, we pick action classes from Something-Something dataset [69].
이 데이터 세트는 인간-객체 상호 작용에 중점을 두므로 더 세분화되고 강력한 시간 모델링이 필요합니다.
This dataset focuses on human-object interaction, thus it is more fine-grained and requires strong temporal modeling.
예를 들어 다른 비디오 프레임을 보지 않고 무언가를 떨어뜨리고 집는 첫 번째 프레임만 보면 이 두 동작을 구분할 수 없습니다.
For example, if we only look at the first frame of dropping something and picking something up without looking at other video frames, it is impossible to tell these two actions apart.
맨 아래 행에서 Moments in Time 데이터 세트[142]에서 작업 클래스를 선택합니다.
In the bottom row, we pick action classes from Moments in Time dataset [142].
이 데이터 세트는 대부분의 비디오 동작 인식 데이터 세트와 다르며 다양한 수준의 추상화에서 동적 이벤트를 나타내는 큰 클래스 간 및 클래스 내 변형을 갖도록 설계되었습니다.
This dataset is different from most video action recognition datasets, and is designed to have large inter-class and intra-class variation that represent dynamical events at different levels of abstraction.
예를 들어, 액션 클라이밍은 다양한 환경(계단 또는 나무)에서 다양한 행위자(사람 또는 동물)를 가질 수 있습니다.
For example, the action climbing can have different actors (person or animal) in different environments (stairs or tree).
2.2. Challenges
효과적인 비디오 동작 인식 알고리즘을 개발하는 데는 몇 가지 주요 과제가 있습니다.
There are several major challenges in developing effective video action recognition algorithms.
데이터 세트 측면에서 첫째, 학습 동작 인식 모델을 위한 레이블 공간을 정의하는 것은 쉽지 않습니다.
In terms of dataset, first, defining the label space for training action recognition models is non-trivial.
인간의 행동은 일반적으로 복합적인 개념이고 이러한 개념의 계층 구조가 잘 정의되어 있지 않기 때문입니다.
It’s because human actions are usually composite concepts and the hierarchy of these concepts are not well-defined.
둘째, 행동 인식을 위한 동영상에 주석을 다는 것은 힘들고(예: 모든 비디오 프레임을 시청해야 함) 모호합니다(예: 행동의 정확한 시작과 끝을 결정하기 어려움).
Second, annotating videos for action recognition are laborious (e.g., need to watch all the video frames) and ambiguous (e.g, hard to determine the exact start and end of an action).
셋째, 일부 인기 있는 벤치마크 데이터 세트(예: Kinetics 제품군)는 사용자가 다운로드할 수 있는 비디오 링크만 공개하고 실제 비디오는 공개하지 않아 방법이 다른 데이터에서 평가되는 상황이 발생합니다.
Third, some popular benchmark datasets (e.g., Kinetics family) only release the video links for users to download and not the actual video, which leads to a situation that methods are evaluated on different data.
방법을 공정하게 비교하고 통찰력을 얻는 것은 불가능합니다.
It is impossible to do fair comparisons between methods and gain insights.
모델링 측면에서 첫째, 인간 행동을 포착한 비디오는 클래스 내 및 클래스 간 변이가 강합니다.
In terms of modeling, first, videos capturing human actions have both strong intra- and inter-class variations.
사람들은 다양한 시점에서 다양한 속도로 동일한 작업을 수행할 수 있습니다.
People can perform the same action in different speeds under various viewpoints.
게다가 일부 동작은 구별하기 어려운 유사한 동작 패턴을 공유합니다.
Besides, some actions share similar movement patterns that are hard to distinguish.
둘째, 인간의 행위를 인식하기 위해서는 단기 행위별 동작 정보와 장거리 시간 정보를 동시에 이해해야 한다.
Second, recognizing human actions requires simultaneous understanding of both short-term action-specific motion information and long-range temporal information.
Single convolutional neural network을 사용하는 대신 다양한 관점을 처리하기 위해 정교한 모델이 필요할 수 있습니다.
We might need a sophisticated model to handle different perspectives rather than using a single convolutional neural network.
셋째, training and inference 모두 계산 비용이 높아 동작 인식 모델의 개발과 배포를 방해합니다.
Third, the computational cost is high for both training and inference, hindering both the development and deployment of action recognition models.
다음 섹션에서는 앞서 언급한 과제를 해결하기 위해 지난 10년 동안 비디오 동작 인식 방법이 어떻게 개발되었는지 보여줍니다.
In the next section, we will demonstrate how video action recognition methods developed over the last decade to address the aforementioned challenges.
3. An Odyssey of Using Deep Learning for Video Action Recognition
In this section, we review deep learning based methods for video action recognition from 2014 to present and introduce the related earlier work in context.
3.1. From hand-crafted features to CNNs
비디오 동작 인식을 위해 CNN(Convolutional Neural Networks)을 사용하는 일부 논문이 있음에도 불구하고 [200, 5, 91], hand-crafted features[209, 210, 158, 112], 특히 IDT(Improved Dense Trajectories) [210], 높은 정확도와 우수한 견고성으로 인해 2015년 이전에 video understanding literature을 지배했습니다.
Despite there being some papers using Convolutional Neural Networks (CNNs) for video action recognition, [200, 5, 91], hand-crafted features [209, 210, 158, 112], particularly Improved Dense Trajectories (IDT) [210], dominated the video understanding literature before 2015, due to their high accuracy and good robustness.
그러나 handcrafted features는 computational cost가 많이 들고 [244] 확장 및 배포가 어렵습니다.
However, handcrafted features have heavy computational cost [244], and are hard to scale and deploy.
딥 러닝[107]이 부상하면서 연구원들은 비디오 문제에 CNN을 적용하기 시작했습니다.
With the rise of deep learning [107], researchers started to adapt CNNs for video problems.
DeepVideo[99]는 각 비디오 프레임에서 단일 2D CNN 모델을 독립적으로 사용하도록 제안하고 late fusion / early fusion / slow fusion과 같은 비디오 동작 인식을 위한 spatio-temporal features를 학습하기 위해 여러 시간 연결 패턴을 조사했습니다.
The seminal work DeepVideo [99] proposed to use a single 2D CNN model on each video frame independently and investigated several temporal connectivity patterns to learn spatio-temporal features for video action recognition, such as late fusion, early fusion and slow fusion.
이 모델은 multi-resolution network와 같이 나중에 유용할 것으로 입증된 아이디어로 초기에 발전했지만 UCF101 [190]의 transfer learning performance는 hand-crafted IDT features보다 20% 낮았습니다(65.4% 대 87.9%).
Though this model made early progress with ideas that would prove to be useful later such as a multi-resolution network, its transfer learning performance on UCF101 [190] was 20% less than hand-crafted IDT features (65.4% vs 87.9%).
또한 DeepVideo [99]는 개별 비디오 프레임에 의해 공급되는 네트워크가 입력이 프레임 스택으로 변경될 때 동일하게 잘 수행됨을 발견했습니다.
Furthermore, DeepVideo [99] found that a network fed by individual video frames, performs equally well when the input is changed to a stack of frames.
이 관찰은 학습된 spatio-temporal features가 모션을 잘 캡처하지 못했음을 나타낼 수 있습니다.
This observation might indicate that the learnt spatio-temporal features did not capture the motion well.
또한 다른 컴퓨터 비전 작업과 달리 CNN 모델이 비디오 영역에서 전통적인 hand-crafted features를 능가하지 못하는 이유에 대해 사람들이 생각하도록 장려했습니다[107, 171].
It also encouraged people to think about why CNN models did not outperform traditional hand-crafted features in the video domain unlike in other computer vision tasks [107, 171].
3.2. Two-stream networks
영상을 이해하려면 직관적인 움직임 정보가 필요하기 때문에 CNN 기반 영상 동작 인식의 성능을 향상시키기 위해서는 프레임 간의 시간적 관계를 설명하는 적절한 방법을 찾는 것이 필수적입니다.
Since video understanding intuitively needs motion information, finding an appropriate way to describe the temporal relationship between frames is essential to improving the performance of CNN-based video action recognition.
Optical flow[79]은 객체/장면 이동을 설명하는 효과적인 동작 표현입니다.
Optical flow [79] is an effective motion representation to describe object/scene movement.
정확히 말하면 관찰자와 장면 간의 상대적인 움직임으로 인해 시각적 장면에서 객체, 표면 및 가장자리의 겉보기 움직임 패턴입니다.
To be precise, it is the pattern of apparent motion of objects, surfaces, and edges in a visual scene caused by the relative motion between an observer and a scene.
그림 5에서 Optical flow의 여러 시각화를 보여줍니다. 우리가 볼 수 있듯이 Optical flow은 각 작업의 모션 패턴을 정확하게 설명할 수 있습니다.
We show several visualizations of optical flow in Figure 5. As we can see, optical flow is able to describe the motion pattern of each action accurately.

Optical flow을 사용하는 이점은 RGB 이미지에 비해 직교 정보(orthogonal information)를 제공한다는 것입니다.
The advantage of using optical flow is it provides orthogonal information compared to the the RGB image.
예를 들어 그림 5의 아래쪽에 있는 두 이미지는 배경이 어수선합니다.
For example, the two images on the bottom of Figure 5 have cluttered backgrounds.
Optical flow은 움직이지 않는 배경을 효과적으로 제거할 수 있으며 원본 RGB 이미지를 입력으로 사용하는 것과 비교하여 학습 문제가 더 간단해집니다.
Optical flow can effectively remove the nonmoving background and result in a simpler learning problem compared to using the original RGB images as input.
또한 Optical flow은 비디오 문제에 잘 작동하는 것으로 나타났습니다.
In addition, optical flow has been shown to work well on video problems.
IDT[210]와 같은 Traditional hand-crafted features에는 HOF(Histogram of Optical Flow) 및 MBH(Motion Boundary Histogram)와 같은 Optical flow와 같은 기능도 포함되어 있습니다.
Traditional hand-crafted features such as IDT [210] also contain optical-flow-like features, such as Histogram of Optical Flow (HOF) and Motion Boundary Histogram (MBH).
따라서 Simonyan et al. [187] 그림 6과 같이 공간 스트림과 시간 스트림을 포함하는 two-stream networks를 제안했습니다.
Hence, Simonyan et al. [187] proposed two-stream networks, which included a spatial stream and a temporal stream as shown in Figure 6.
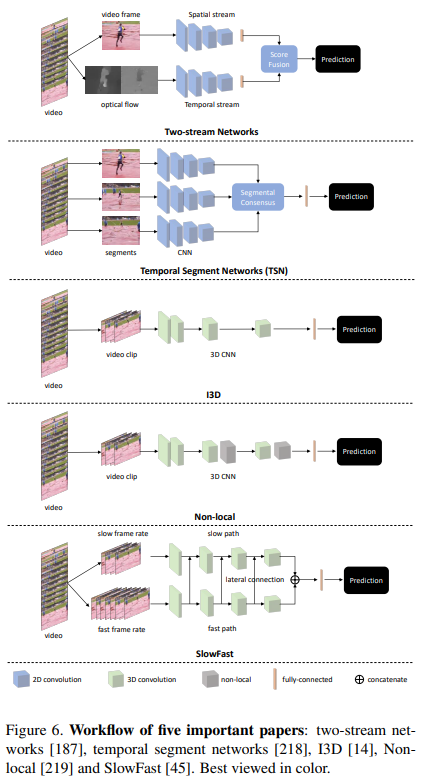
이 방법은 인간의 시각 피질이 객체 인식을 수행하는 ventral stream과 동작을 인식하는 dorsal stream의 두 경로를 포함한다는 two-streams hypothesis[65]과 관련이 있습니다.
This method is related to the two-streams hypothesis [65], according to which the human visual cortex contains two pathways: the ventral stream (which performs object recognition) and the dorsal stream (which recognizes motion).
공간 스트림은 원시 비디오 프레임을 입력으로 사용하여 시각적 모양 정보를 캡처합니다.
The spatial stream takes raw video frame(s) as input to capture visual appearance information.
temporal stream은 비디오 프레임 간의 모션 정보를 캡처하기 위해 optical flow 이미지 스택을 입력으로 사용합니다.
The temporal stream takes a stack of optical flow images as input to capture motion information between video frames.
구체적으로, [187]은 추정된 흐름(즉, x 방향 및 y 방향의 움직임)의 수평 및 수직 구성 요소를 [0, 255] 범위로 선형으로 재조정하고 JPEG를 사용하여 압축했습니다.
To be specific, [187] linearly rescaled the horizontal and vertical components of the estimated flow (i.e., motion in the x-direction and y-direction) to a [0, 255] range and compressed using JPEG.
출력은 그림 6에 표시된 두 개의 optical flow 이미지에 해당합니다.
The output corresponds to the two optical flow images shown in Figure 6.
압축된 optical flow 이미지는 H×W×2L 차원의 시간적 스트림에 대한 입력으로 연결됩니다. 여기서 H, W 및 L은 비디오 프레임의 높이, 너비 및 길이를 나타냅니다.
The compressed optical flow images will then be concatenated as the input to the temporal stream with a dimension of H×W×2L, where H, W and L indicates the height, width and the length of the video frames.
결국 두 스트림의 예측 점수를 평균하여 최종 예측을 얻습니다.
In the end, the final prediction is obtained by averaging the prediction scores from both streams.
Extra temporal stream을 추가함으로써 처음으로 CNN 기반 접근 방식은 UCF101(88.0% 대 87.9%) 및 HMDB51109에서 이전 최고의 hand-crafted feature IDT와 유사한 성능을 달성하였고, 두 가지 중요한 사실을 제공합니다.
By adding the extra temporal stream, for the first time, a CNN-based approach achieved performance similar to the previous best hand-crafted feature IDT on UCF101 (88.0% vs 87.9%) and on HMDB51 [109] (59.4% vs 61.1%). [187] makes two important observations.
첫째, 영상 동작 인식을 위해서는 동작 정보가 중요하다.
First, motion information is important for video action recognition.
둘째, CNN이 원시 비디오 프레임에서 직접 시간 정보를 학습하는 것은 여전히 어려운 일입니다.
Second, it is still challenging for CNNs to learn temporal information directly from raw video frames.
모션 표현으로 optical flow을 미리 계산하는 것은 딥 러닝이 그 힘을 드러내는 효과적인 방법입니다.
Pre-computing optical flow as the motion representation is an effective way for deep learning to reveal its power.
[187]이 딥 러닝 접근 방식과 전통적인 hand-crafted features의 격차를 좁힐 수 있었기 때문에 two-stream 네트워크에 대한 많은 후속 논문이 등장하여 비디오 동작 인식의 개발을 크게 발전시켰습니다. 여기에서 여러 범주로 나누고 개별적으로 검토합니다.
Since [187] managed to close the gap between deep learning approaches and traditional hand-crafted features, many follow-up papers on twostream networks emerged and greatly advanced the development of video action recognition. Here, we divide them into several categories and review them individually
3.2.1 Using deeper network architectures
Two-stream networks [187]는 상대적으로 얕은 네트워크 아키텍처[107]를 사용했습니다.
Two-stream networks [187] used a relatively shallow network architecture [107].
따라서 2개 스트림 네트워크로 자연스럽게 확장하려면 더 깊은 네트워크를 사용해야 합니다.
Thus a natural extension to the two-stream networks involves using deeper networks.
그러나 Wang et al. [215]는 단순히 더 깊은 네트워크를 사용하는 것이 더 나은 결과를 얻지 못한다는 것을 발견했습니다. 아마도 작은 크기의 비디오 데이터 세트에 대한 과적합 때문일 수 있습니다[190, 109]. 섹션 2.1, UCF101 및 HMDB51 데이터 세트에는 수천 개의 교육 비디오만 있습니다.
However, Wang et al. [215] finds that simply using deeper networks does not yield better results, possibly due to overfitting on the small-sized video datasets [190, 109]. Recall from section 2.1, UCF101 and HMDB51 datasets only have thousands of training videos.
따라서 Wang et al. [217] 더 깊은 네트워크가 과적합되는 것을 방지하기 위해 crossmodality initialization, synchronized batch normalization, corner cropping 및 multi-scale cropping data augmentation, large dropout ratio 등을 포함한 일련의 모범 사례를 소개합니다.
Hence, Wang et al. [217] introduce a series of good practices, including crossmodality initialization, synchronized batch normalization,corner cropping and multi-scale cropping data augmentation, large dropout ratio, etc. to prevent deeper networks from overfitting.
이러한 모범 사례를 통해 [217]는 UCF101에서 큰 차이로 [187]보다 성능이 뛰어난 VGG16 모델[188]로 two-stream network를 훈련할 수 있었습니다.
With these good practices, [217] was able to train a two-stream network with the VGG16 model [188] that outperforms [187] by a large margin on UCF101.
이러한 모범 사례는 널리 채택되어 여전히 사용되고 있습니다.
These good practices have been widely adopted and are still being used.
나중에 TSN(Temporal Segment Networks)[218]은 VGG16, ResNet[76], Inception[198]과 같은 네트워크 아키텍처에 대한 철저한 조사를 수행했으며 더 깊은 네트워크가 일반적으로 비디오 동작 인식에 대해 더 높은 인식 정확도를 달성한다는 것을 보여주었습니다.
Later, Temporal Segment Networks (TSN) [218] performed a thorough investigation of network architectures, such as VGG16, ResNet [76], Inception [198], and demonstrated that deeper networks usually achieve higher recognition accuracy for video action recognition.
**섹션 3.2.4에서 TSN에 대한 자세한 내용을 설명합니다. **
We will describe more details about TSN in section 3.2.4.
3.2.2 Two-stream fusion
Two-stream 네트워크에는 두 개의 스트림이 있으므로 최종 예측을 얻기 위해 두 네트워크의 결과를 병합해야 하는 단계가 있습니다.
Since there are two streams in a two-stream network, there will be a stage that needs to merge the results from both networks to obtain the final prediction.
이 단계는 일반적으로 spatial-temporal fusion step라고 합니다.
This stage is usually referred to as the spatial-temporal fusion step.
가장 쉽고 간단한 방법은 두 스트림에서 예측의 가중 평균을 수행하는 late fusion입니다.
The easiest and most straightforward way is late fusion, which performs a weighted average of predictions from both streams.
Late fusion이 널리 채택되고 있음에도 불구하고[187, 217], 많은 연구자들은 이것이 spatial appearance stream과 temporal motion stream 사이의 정보를 융합하는 최적의 방법이 아닐 수 있다고 주장합니다.
Despite late fusion being widely adopted [187, 217], many researchers claim that this may not be the optimal way to fuse the information between the spatial appearance stream and temporal motion stream.
그들은 두 네트워크 간의 earlier interactions이 모델 학습 중에 두 스트림 모두에 도움이 될 수 있으며 이를 early fusion이라고 합니다.
They believe that earlier interactions between the two networks could benefit both streams during model learning and this is termed as early fusion.
Fusion[50]은 네트워크를 융합할 위치(예: 초기 상호 작용이 발생하는 네트워크 계층), 시간 융합을 수행하는 방법(예: 네트워크의 후반 단계에서 2D 또는 3D 컨볼루션 융합 사용)[50] 초기 융합이 두 스트림 모두 더 풍부한 기능을 학습하는 데 도움이 되고 후기 융합보다 성능이 향상됨을 보여줍니다.
Fusion [50] is one of the first of several papers investigating the early fusion paradigm, including how to perform spatial fusion (e.g., using operators such as sum, max, bilinear, convolution and concatenation), where to fuse the network (e.g., the network layer where early interactions happen), and how to perform temporal fusion (e.g., using 2D or 3D convolutional fusion in later stages of the network).[50] shows that early fusion is beneficial for both streams to learn richer features and leads to improved performance over late fusion.
이 연구 라인에 따라 Feichtenhofer et al. [46]은 두 스트림 사이에 residual connections을 도입하여 ResNet [76]을 시공간(spatiotemporal) domain 으로 일반화합니다.
Following this line of research, Feichtenhofer et al. [46] generalizes ResNet [76] to the spatiotemporal domain by introducing residual connections between the two streams.
[46]을 Base로 해서, Feichtenhofer et al. [47] 더 나은 spatio-temporal features을 학습하기 위해 residual networks에 대한 곱셈 게이팅 기능을 추가로 제안합니다.
Based on [46], Feichtenhofer et al. [47] further propose a multiplicative gating function for residual networks to learn better spatio-temporal features.
동시에 [225]는 두 스트림 사이의 계층적 초기 융합을 수행하기 위해 spatio-temporal pyramid를 채택합니다.
Concurrently, [225] adopts a spatio-temporal pyramid to perform hierarchical early fusion between the two streams.
3.2.3 Recurrent neural networks
비디오는 본질적으로 시간적 시퀀스이기 때문에 연구자들은 비디오 내부의 시간적 모델링, 특히 LSTM(Long Short-Term Memory)의 사용을 위해 RNN(Recurrent Neural Networks)을 탐색했습니다[78].
Since a video is essentially a temporal sequence, researchers have explored Recurrent Neural Networks (RNNs) for temporal modeling inside a video, particularly the usage of Long Short-Term Memory (LSTM) [78].
LRCN[37]과 Beyond-Short-Snippets[253]는 두 스트림 네트워크 설정에서 비디오 동작 인식을 위해 LSTM을 사용하는 여러 논문 중 첫 번째입니다.
LRCN [37] and Beyond-Short-Snippets [253] are the first of several papers that use LSTM for video action recognition under the two-stream networks setting.
CNN의 feature maps을 심층 LSTM 네트워크에 대한 입력으로 사용하고 프레임 수준 CNN Features을 비디오 수준 예측으로 집계합니다.
They take the feature maps from CNNs as an input to a deep LSTM network, and aggregate frame-level CNN features into videolevel predictions.
그들은 두 개의 스트림에서 개별적으로 LSTM을 사용하고 최종 결과는 여전히 late fusion에 의해 얻어집니다.
Note that they use LSTM on two streams separately, and the final results are still obtained by late fusion.
그러나 두 스트림 기준선[187]에 비해 LSTM 모델[253]에서 명확한 경험적 개선은 없습니다.
However, there is no clear empirical improvement from LSTM models [253] over the two-stream baseline [187].
CNN-LSTM 프레임워크에 따라 bi-directional LSTM [205], CNN-LSTM fusion [56] 및 hierarchical multi-granularity LSTM network [118]와 같은 여러 변형이 제안됩니다.
Following the CNN-LSTM framework, several variants are proposed, such as bi-directional LSTM [205], CNN-LSTM fusion [56] and hierarchical multi-granularity LSTM network [118].
[125]는 correlation-based spatial attention mechanism 과 lightweight motion-based attention mechanism을 포함하는 VideoLSTM을 설명했습니다.
[125] described VideoLSTM which includes a correlation-based spatial attention mechanism and a lightweight motion-based attention mechanism.
VideoLSTM은 동작 인식에 대한 개선된 결과를 보여줄 뿐만 아니라 학습된 주의가 동작 클래스 레이블에만 의존하여 동작 현지화에 어떻게 사용될 수 있는지 보여줍니다.
VideoLSTM not only show improved results on action recognition, but also demonstrate how the learned attention can be used for action localization by relying on just the action class label.
Lattice-LSTM[196]은 개별 공간 위치에 대한 메모리 셀의 independent hidden state transitions을 학습하여 LSTM을 확장하여 장기적이고 복잡한 움직임을 정확하게 모델링할 수 있습니다.
Lattice-LSTM [196] extends LSTM by learning independent hidden state transitions of memory cells for individual spatial locations, so that it can accurately model long-term and complex motions.
ShuttleNet[183]은 장기 종속성을 학습하기 위해 RNN에서 피드포워드 및 피드백 연결을 모두 고려하는 동시 작업입니다.
ShuttleNet [183] is a concurrent work that considers both feedforward and feedback connections in a RNN to learn long-term dependencies.
FASTER[272]는 값비싼 백본과 저렴한 백본에서 클립 수준 기능을 통합하기 위해 FAST-GRU를 설계했습니다.
FASTER [272] designed a FAST-GRU to aggregate clip-level features from an expensive backbone and a cheap backbone.
이 전략은 중복 클립의 처리 비용을 줄여 inference speed를 가속화합니다.
This strategy reduces the processing cost of redundant clips and hence accelerates the inference speed.
그러나 위에서 언급한 작업[37, 253, 125, 196, 183]은 서로 다른 두 스트림 네트워크/백본을 사용합니다.
However, the work mentioned above [37, 253, 125, 196, 183] use different two-stream networks/backbones.
따라서 RNN을 사용하는 다양한 방법 간의 차이점은 명확하지 않습니다. Ma et al. [135] 공정한 비교를 위한 강력한 기준선을 구축하고 RNN을 사용하여 시공간적 특징을 학습하는 효과를 철저히 연구합니다.
The differences between various methods using RNNs are thus unclear. Ma et al. [135] build a strong baseline for fair comparison and thoroughly study the effect of learning spatiotemporal features by using RNNs.
예를 들어 LSTM은 시간 정보를 완전히 활용하기 위해 사전 분할된 데이터가 필요합니다.
They find that it requires proper care to achieve improved performance, e.g., LSTMs require pre-segmented data to fully exploit the temporal information.
RNN은 또한 비디오 동작 현지화[189] 및 비디오 질문 응답[274]에서 집중적으로 연구되지만 이 설문 조사의 범위를 벗어납니다.
RNNs are also intensively studied in video action localization [189] and video question answering [274], but these are beyond the scope of this survey.
3.2.4 Segment-based methods
Optical flow 덕분에 two-stream networks는 프레임 간의 short-term motion information를 추론할 수 있습니다.
Thanks to optical flow, two-stream networks are able to reason about short-term motion information between frames.
그러나 그들은 여전히 long-range temporal information를 캡처할 수 없습니다.
However, they still cannot capture long-range temporal information.
Two-stream networks의 이러한 약점에 동기를 부여한 Wang et al. [218]은 비디오 수준의 동작 인식을 수행하기 위해 TSN(Temporal Segment Network)을 제안했습니다.
Motivated by this weakness of two-stream networks , Wang et al. [218] proposed a Temporal Segment Network (TSN) to perform video-level action recognition.
처음에는 2D CNN과 함께 사용하도록 제안되었지만 간단하고 일반적입니다.
Though initially proposed to be used with 2D CNNs, it is simple and generic.
따라서 2D 또는 3D CNN을 사용하는 최근 작업은 여전히 이 프레임워크를 기반으로 합니다.
Thus recent work using either 2D or 3D CNNs, are still built upon this framework.
구체적으로, 그림 6에 표시된 것처럼 TSN은 먼저 전체 비디오를 몇 개의 세그먼트로 나누고 세그먼트는 시간 차원을 따라 균일하게 분포됩니다.
To be specific, as shown in Figure 6, TSN first divides a whole video into several segments, where the segments distribute uniformly along the temporal dimension.
그런 다음 TSN은 각 세그먼트 내에서 단일 비디오 프레임을 임의로 선택하여 네트워크를 통해 전달합니다.
Then TSN randomly selects a single video frame within each segment and forwards them through the network.
여기서 네트워크는 모든 세그먼트의 입력 프레임에 대한 가중치를 공유합니다.
Here, the network shares weights for input frames from all the segments.
마지막으로 샘플링된 비디오 프레임에서 정보를 집계하기 위해 segmental consensus가 수행됩니다.
In the end, a segmental consensus is performed to aggregate information from the sampled video frames.
segmental consensus 는 평균 풀링, 최대 풀링, 쌍선형 인코딩 등과 같은 연산자가 될 수 있습니다.
The segmental consensus could be operators like average pooling, max pooling, bilinear encoding, etc.
이런 의미에서 TSN은 모델이 전체 비디오에서 콘텐츠를 보기 때문에 long-range temporal structure를 모델링할 수 있습니다.
In this sense, TSN is capable of modeling long-range temporal structure because the model sees the content from the entire video.
또한 이 sparse sampling strategy은 긴 비디오 시퀀스에 대한 교육 비용을 낮추지만 관련 정보를 보존합니다.
In addition, this sparse sampling strategy lowers the training cost over long video sequences but preserves relevant information.
TSN의 우수한 성능과 단순성을 감안할 때 대부분의 two-stream methods은 나중에 세그먼트 기반 two-stream networks가 됩니다.
Given TSN’s good performance and simplicity, most two-stream methods afterwards become segment-based two-stream networks.
Segmental Consensus는 단순히 최대 또는 평균 풀링 작업을 수행하기 때문에 feature encoding 단계는 글로벌 비디오 기능을 생성하고 기존 접근 방식에서 제안한 성능 향상으로 이어질 수 있습니다[179, 97, 157].
Since the segmental consensus is simply doing a max or average pooling operation, a feature encoding step might generate a global video feature and lead to improved performance as suggested in traditional approaches [179, 97, 157].
DVOF(Deep Local Video Feature) [114]는 로컬 입력에 대해 Train된 심층 네트워크를 feature extractors로 취급하고 다른 인코딩 기능을 Train하여 글로벌 기능을 글로벌 레이블에 매핑하도록 제안했습니다.
Deep Local Video Feature (DVOF) [114] proposed to treat the deep networks that trained on local inputs as feature extractors and train another encoding function to map the global features into global labels.
TLE(Temporal Linear Encoding) 네트워크[36]는 DVOF와 동시에 등장했지만 전체 파이프라인이 end-to-end로 훈련될 수 있도록 인코딩 계층이 네트워크에 내장되었습니다.
Temporal Linear Encoding (TLE) network [36] appeared concurrently with DVOF, but the encoding layer was embedded in the network so that the whole pipeline could be trained end-to-end.
VLAD3와 ActionVLAD[123, 63]도 동시에 등장했다.
VLAD3 and ActionVLAD [123, 63] also appeared concurrently.
그들은 NetVLAD 레이어[4]를 비디오 도메인으로 확장하여 [36]에서와 같이 컴팩트한 바이리니어 인코딩을 사용하는 대신 비디오 레벨 인코딩을 수행했습니다.
They extended the NetVLAD layer [4] to the video domain to perform video-level encoding, instead of using compact bilinear encoding as in [36].
TSN의 시간적 추론 능력을 향상시키기 위해 여러 시간 척도에서 비디오 프레임 간의 시간적 종속성을 학습하고 추론하기 위한 TRN(Temporal Relation Network)[269]이 제안되었습니다.
To improve the temporal reasoning ability of TSN, Temporal Relation Network (TRN) [269] was proposed to learn and reason about temporal dependencies between video frames at multiple time scales.
최근의 최첨단 효율적인 모델인 TSM[128]도 세그먼트 기반입니다.
The recent state-of-the-art efficient model TSM [128] is also segment-based.
섹션 3.4.2에서 더 자세히 논의할 것입니다.
We will discuss it in more detail in section 3.4.2.
3.2.5 Multi-stream networks
Two-stream networks는 모양과 동작 정보가 비디오의 가장 중요한 두 가지 속성이기 때문에 성공적입니다.
Two-stream networks are successful because appearance and motion information are two of the most important properties of a video.
그러나 포즈, 개체, 오디오 및 깊이 등과 같이 비디오 동작 인식을 도울 수 있는 다른 요소가 있습니다.
However, there are other factors that can help video action recognition as well, such as pose, object, audio and depth, etc.
포즈 정보는 인간의 행동과 밀접한 관련이 있습니다.
Pose information is closely related to human action.
우리는 장면 컨텍스트 없이 포즈(스켈레톤) 이미지만 보고 대부분의 작업을 인식할 수 있습니다.
We can recognize most actions by just looking at a pose (skeleton) image without scene context.
동작 인식을 위해 포즈를 사용하는 이전 작업[150, 246]이 있지만 P-CNN[23]은 비디오 동작 인식을 개선하기 위해 포즈를 성공적으로 사용한 최초의 딥 러닝 방법 중 하나입니다.
Although there is previous work on using pose for action recognition [150, 246], P-CNN [23] was one of the first deep learning methods that successfully used pose to improve video action recognition.
P-CNN은 궤적 풀링(trajectory pooling)[214]과 유사한 정신으로 인체 부위의 궤적을 따라 동작 및 모양 정보를 집계할 것을 제안했습니다.
P-CNN proposed to aggregates motion and appearance information along tracks of human body parts, in a similar spirit to trajectory pooling [214].
[282]은 이 파이프라인을 모양, 동작 및 포즈를 계산하고 통합하는 연결된 다중 스트림 프레임워크로 확장했습니다.
[282] extended this pipeline to a chained multi-stream framework, that computed and integrated appearance, motion and pose.
그들은 이러한 신호를 연속적으로 추가하는 Markov 체인 모델을 도입했으며 동작 인식 및 동작 위치 파악 모두에서 유망한 결과를 얻었습니다.
They introduced a Markov chain model that added these cues successively and obtained promising results on both action recognition and action localization.
PoTion [25]은 P-CNN의 후속 작업이었지만 인간 의미론적 키포인트의 움직임을 인코딩하는 더 강력한 기능 표현을 도입했습니다.
PoTion [25] was a follow-up work to P-CNN, but introduced a more powerful feature representation that encoded the movement of human semantic keypoints.
그들은 먼저 적절한 human pose estimator를 실행하고 각 프레임에서 인간 관절에 대한 히트맵을 추출했습니다.
They first ran a decent human pose estimator and extracted heatmaps for the human joints in each frame.
그런 다음 이러한 확률 맵을 시간적으로 집계하여 PoTion representation을 얻었습니다.
They then obtained the PoTion representation by temporally aggregating these probability maps.
PoTion은 가볍고 이전 포즈 표현을 능가합니다[23, 282].
PoTion is lightweight and outperforms previous pose representations [23, 282].
또한 표준 모양 및 모션 스트림을 보완하는 것으로 나타났습니다. PoTion을 I3D[14]와 결합하여 UCF101에서 state-of-the-art 결과를 달성했습니다(98.2%).
In addition, it was shown to be complementary to standard appearance and motion streams, e.g. combining PoTion with I3D [14] achieved state-of-the-art result on UCF101 (98.2%).
대부분의 인간 행동은 인간-객체 상호 작용을 포함하기 때문에 개체 정보는 또 다른 중요한 단서입니다.
Object information is another important cue because most human actions involve human-object interaction.
Wu [232]는 비디오 동작 인식을 돕기 위해 object features와 scene features을 모두 활용하도록 제안했습니다.
Wu [232] proposed to leverage both object features and scene features to help video action recognition.
객체 및 장면 특징은 state-of-the-art pretrained object and scene detectors에서 추출되었습니다.
The object and scene features were extracted from state-of-the-art pretrained object and scene detectors.
Wang et al. [252]은 네트워크를 end-to-end 훈련 가능하게 만들기 위해 한 걸음 더 나아갔습니다.
Wang et al. [252] took a step further to make the network end-to-end trainable.
그들은 개체, 사람 및 장면에 대한 의미론적 정보를 추출하기 위해 표준 공간 스트림을 Faster RCNN 네트워크[171]로 대체함으로써 두 스트림 의미론적 영역 기반 방법을 도입했습니다.
They introduced a two-stream semantic region based method, by replacing a standard spatial stream with a Faster RCNN network [171], to extract semantic information about the object, person and scene.
오디오 신호는 일반적으로 비디오와 함께 제공되며 시각적 정보를 보완합니다. Wuet al. [233] 상호 보완적인 단서를 소화하기 위해 비디오에서 spatial, short-term motion, long-term temporal and audio를 통합하는 다중 스트림 프레임워크를 도입했습니다.
Audio signals usually come with video, and are complementary to the visual information. Wu et al. [233] introduced a multi-stream framework that integrates spatial, short-term motion, long-term temporal and audio in videos to digest complementary clues.
최근 Xiao et al. [237]은 [45]에 이어 AudioSlowFast를 도입했으며, 통합된 표현으로 모델 비전과 사운드에 또 다른 오디오 경로를 추가했습니다.
Recently, Xiao et al. [237] introduced AudioSlowFast following [45], by adding another audio pathway to model vision and sound in an unified representation.
RGB-D 영상 동작 인식 분야에서는 깊이 정보를 이용하는 것이 표준 관행이다[59].
In RGB-D video action recognition field, using depth information is standard practice [59].
그러나 비전 기반 비디오 동작 인식(예: 주어진 단안 비디오만)의 경우 RGB-D 도메인에서와 같이 실측 깊이 정보에 액세스할 수 없습니다.
However, for visionbased video action recognition (e.g., only given monocular videos), we do not have access to ground truth depth information as in the RGB-D domain.
초기 시도인 Depth2Action[280]은 기성 깊이 추정기를 사용하여 비디오에서 깊이 정보를 추출하고 이를 동작 인식에 사용합니다.
An early attempt Depth2Action [280] uses off-the-shelf depth estimators to extract depth information from videos and use it for action recognition.
기본적으로 다중 스트림 네트워크는 다양한 단서를 입력 신호로 사용하여 비디오 동작 인식을 돕는 다중 양식 학습 방법입니다.
Essentially, multi-stream networks is a way of multimodality learning, using different cues as input signals to help video action recognition.
섹션 5.12에서 다중 양식 학습에 대해 더 논의할 것입니다.
We will discuss more on multi-modality learning in section 5.12.
3.3. The rise of 3D CNNs
사전 컴퓨팅 optical flow은 계산 집약적이고 스토리지가 많이 필요하므로 대규모 교육이나 실시간 배포에 적합하지 않습니다.
Pre-computing optical flow is computationally intensive and storage demanding, which is not friendly for large-scale training or real-time deployment.
비디오를 이해하는 개념적으로 쉬운 방법은 2개의 공간 차원과 1개의 시간 차원을 가진 3D 텐서입니다.
A conceptually easy way to understand a video is as a 3D tensor with two spatial and one time dimension.
따라서 비디오의 시간 정보를 모델링하기 위한 처리 단위로 3D CNN을 사용하게 됩니다.
Hence, this leads to the usage of 3D CNNs as a processing unit to model the temporal information in a video.
동작 인식을 위해 3D CNN을 사용하는 중요한 작업은 [91]입니다.
The seminal work for using 3D CNNs for action recognition is [91].
영감을 주기는 했지만 네트워크는 그 잠재력을 보여줄 만큼 충분히 깊지 않았습니다.
While inspiring, the network was not deep enough to show its potential.
Tran et al. C3D라고 하는 더 깊은 3D 네트워크로 확장되었습니다[91].
Tran et al. [202] extended [91] to a deeper 3D network, termed C3D.
C3D는 VGG16 네트워크의 3D 버전으로 생각할 수 있는 [188]의 모듈식 설계를 따릅니다.
C3D follows the modular design of [188], which could be thought of as a 3D version of VGG16 network.
표준 벤치마크에서의 성능은 만족스럽지 않지만 강력한 일반화 기능을 보여 다양한 비디오 작업을 위한 generic feature extractor로 사용할 수 있습니다[250].
Its performance on standard benchmarks is not satisfactory, but shows strong generalization capability and can be used as a generic feature extractor for various video tasks [250].
그러나 3D 네트워크는 최적화하기 어렵습니다.
However, 3D networks are hard to optimize.
3D 컨벌루션 필터를 잘 훈련시키기 위해서는 다양한 비디오 콘텐츠와 동작 범주가 포함된 대규모 데이터 세트가 필요합니다.
In order to train a 3D convolutional filter well, people need a largescale dataset with diverse video content and action categories.
다행스럽게도 심층 3D 네트워크 교육을 지원하기에 충분히 큰 Sports1M [99] 데이터 세트가 있습니다.
Fortunately, there exists a dataset, Sports1M [99] which is large enough to support the training of a deep 3D network.
그러나 C3D Train은 수렴하는 데 몇 주가 걸립니다.
However, the training of C3D takes weeks to converge.
C3D의 인기에도 불구하고 대부분의 사용자는 네트워크를 수정/미세 조정하는 대신 다양한 사용 사례에 대한 기능 추출기로 채택합니다.
Despite the popularity of C3D, most users just adopt it as a feature extractor for different use cases instead of modifying/fine-tuning the network.
이것이 2D CNN을 기반으로 하는 two-stream networks가 2014년부터 2017년까지 비디오 동작 인식 영역을 지배한 이유 중 하나입니다.
This is partially the reason why two-stream networks based on 2D CNNs dominated the video action recognition domain from year 2014 to 2017.
Carreira et al. [14]는 2017년에 I3D를 제안했습니다. 그림 6에서 볼 수 있듯이 I3D는 비디오 클립을 입력으로 가져와 쌓인 3D 컨볼루션 레이어를 통해 전달합니다.
The situation changed when Carreira et al. [14] proposed I3D in year 2017. As shown in Figure 6, I3D takes a video clip as input, and forwards it through stacked 3D convolutional layers.
비디오 클립은 일련의 비디오 프레임이며 일반적으로 16개 또는 32개 프레임이 사용됩니다.
A video clip is a sequence of video frames, usually 16 or 32 frames are used.
I3D의 주요 기여는 다음과 같습니다.
The major contributions of I3D are:
1) 3D CNN에 사용하기 위해 mature image classification architectures를 채택합니다.
1) it adapts mature image classification architectures to use for 3D CNN;
2) 모델 가중치의 경우 ImageNet 사전 훈련된 2D 모델 가중치를 3D 모델의 해당 가중치로 팽창시키기 위해 [217]에서 optical flow networks 초기화를 위해 개발된 방법을 채택합니다.
2) For model weights, it adopts a method developed for initializing optical flow networks in [217] to inflate the ImageNet pre-trained 2D model weights to their counterparts in the 3D model.
따라서 I3D는 3D CNN이 처음부터 훈련되어야 하는 딜레마를 우회합니다.
Hence, I3D bypasses the dilemma that 3D CNNs have to be trained from scratch.
새로운 대규모 데이터 세트 Kinetics400[100]에 대한 pre-training을 통해 I3D는 UCF101에서 95.6%, HMDB51에서 74.8%를 달성했습니다.
With pre-training on a new large-scale dataset Kinetics400 [100], I3D achieved a 95.6% on UCF101 and 74.8% on HMDB51.
I3D는 서로 다른 방법으로 UCF101 및 HMDB512와 같은 작은 크기의 데이터 세트에 숫자를 보고하던 시대를 마감했습니다.
I3D ended the era where different methods reported numbers on small-sized datasets such as UCF101 and HMDB512 .
I3D를 따르는 간행물은 Kinetics400 또는 다른 대규모 벤치마크 데이터 세트에 대한 성능을 보고해야 했으며, 이를 통해 비디오 동작 인식을 다음 단계로 끌어올렸습니다.
Publications following I3D needed to report their performance on Kinetics400, or other large-scale benchmark datasets, which pushed video action recognition to the next level.
향후 몇 년 동안 3D CNN은 빠르게 발전하여 거의 모든 벤치마크 데이터 세트에서 최고의 성능을 발휘했습니다.
In the next few years, 3D CNNs advanced quickly and became top performers on almost every benchmark dataset.
아래의 여러 범주에서 3D CNN 기반 문헌을 검토할 것입니다.
We will review the 3D CNNs based literature in several categories below.
우리는 3D CNN이 two-stream networks를 대체하지 않으며 상호 배타적이지 않다는 점을 지적하고 싶습니다.
We want to point out that 3D CNNs are not replacing two-stream networks, and they are not mutually exclusive.
그들은 비디오에서 시간 관계를 모델링하기 위해 다른 방법을 사용합니다.
They just use different ways to model the temporal relationship in a video.
또한 two-stream approach는 특정 방식이 아닌 영상 이해를 위한 포괄적인 프레임워크입니다.
Furthermore, the two-stream approach is a generic framework for video understanding, instead of a specific method.
하나는 RGB 프레임을 이용한 공간적 외관 모델링을 위한 네트워크이고, 다른 하나는 optical flow를 이용한 시간적 움직임 모델링을 위한 두 개의 네트워크가 있는 한, 이 방법은 two-stream networks 계열로 분류될 수 있습니다.
As long as there are two networks, one for spatial appearance modeling using RGB frames, the other for temporal motion modeling using optical flow, the method may be categorized into the family of two-stream networks.
[14]에서 그들은 또한 I3D 아키텍처로 시간적 스트림을 구축하고 UCF101에서 98.0%, HMDB51에서 80.9%로 훨씬 더 높은 성능을 달성했습니다.
In [14], they also build a temporal stream with I3D architecture and achieved even higher performance, 98.0% on UCF101 and 80.9% on HMDB51.
따라서 최종 I3D 모델은 3D CNN과 two stream networks의 조합입니다.
Hence, the final I3D model is a combination of 3D CNNs and twostream networks.
그러나 I3D의 기여는 optical flow의 사용에 있지 않습니다.
However, the contribution of I3D does not lie in the usage of optical flow.
3.3.1 Mapping from 2D to 3D CNNs
2D CNN은 ImageNet [30] 및 Places205 [270]와 같은 대규모 이미지 데이터 세트가 제공하는 사전 훈련의 이점을 누리고 있으며, 이는 오늘날 사용 가능한 가장 큰 비디오 데이터 세트와도 비교할 수 없습니다.
2D CNNs enjoy the benefit of pre-training brought by the large-scale of image datasets such as ImageNet [30] and Places205 [270], which cannot be matched even with the largest video datasets available today.
이러한 데이터 세트에서 더 정확하고 더 잘 일반화되는 2D CNN 아키텍처를 찾기 위해 많은 노력을 기울였습니다.
On these datasets numerous efforts have been devoted to the search for 2D CNN architectures that are more accurate and generalize better.
아래에서는 3D CNN에 대한 이러한 발전을 활용하기 위한 노력에 대해 설명합니다.
Below we describe the efforts to capitalize on these advances for 3D CNNs.
ResNet3D[74]는 2D ResNet[76]을 직접 가져와 모든 2D 컨볼루션 필터를 3D 커널로 교체했습니다.
ResNet3D [74] directly took 2D ResNet [76] and replaced all the 2D convolutional filters with 3D kernels.
그들은 대규모 데이터 세트와 함께 깊은 3D CNN을 사용함으로써 ImageNet에서 2D CNN의 성공을 활용할 수 있다고 믿었습니다.
They believed that by using deep 3D CNNs together with large-scale datasets one can exploit the success of 2D CNNs on ImageNet.
ResNeXt [238], Chen et al. [20]은 복잡한 신경망을 섬유 사이의 정보 흐름을 용이하게 하는 경량 네트워크(섬유)의 앙상블로 분할하는 다중 섬유 아키텍처를 제시하고 동시에 계산 비용을 줄입니다.
Motivated by ResNeXt [238], Chen et al. [20] presented a multi-fiber architecture that slices a complex neural network into an ensemble of lightweight networks (fibers) that facilitate information flow between fibers, reduces the computational cost at the same time.
SENet[81]에서 영감을 얻은 STCNet[33]은 네트워크 전체에서 spatial-channels과 temporal-channels correlation information를 모두 캡처하기 위해 3D 블록 내부에 채널별 정보를 통합할 것을 제안합니다.
Inspired by SENet [81], STCNet [33] propose to integrate channel-wise information inside a 3D block to capture both spatial-channels and temporal-channels correlation information throughout the network.
3.3.2 Unifying 2D and 3D CNNs
3D 네트워크 교육의 복잡성을 줄이기 위해 P3D [169] 및 R2+1D [204]는 3D 분해 아이디어를 탐구합니다.
To reduce the complexity of 3D network training, P3D [169] and R2+1D [204] explore the idea of 3D factorization.
구체적으로 말하면, 3D 커널(예: 3×3×3)은 2D 공간 컨볼루션(예: 1 × 3 × 3)과 1D 시간적 컨볼루션(예: 3 × 1 × 1)의 두 가지 개별 연산으로 분해될 수 있습니다. ).
To be specific, a 3D kernel (e.g., 3×3×3) can be factorized to two separate operations, a 2D spatial convolution (e.g.,1 × 3 × 3) and a 1D temporal convolution (e.g., 3 × 1 × 1).
P3D와 R2+1D의 차이점은 두 분해 연산을 배열하는 방법과 각 residual block을 만드는 방법입니다.
The differences between P3D and R2+1D are how they arrange the two factorized operations and how they formulate each residual block.
Trajectory convolution[268]은 이 아이디어를 따르지만 움직임에 더 잘 대처하기 위해 temporal component에 대해 변형 가능한 콘볼루션을 사용합니다.
Trajectory convolution [268] follows this idea but uses deformable convolution for the temporal component to better cope with motion.
3D CNN을 단순화하는 또 다른 방법은 단일 네트워크에서 2D 및 3D 컨볼루션을 혼합하는 것입니다.
Another way of simplifying 3D CNNs is to mix 2D and 3D convolutions in a single network.
MiCTNet[271]은 2D 및 3D CNN을 통합하여 더 깊고 유익한 기능 맵을 생성하는 동시에 시공간 융합의 각 라운드에서 훈련 복잡성을 줄입니다.
MiCTNet [271] integrates 2D and 3D CNNs to generate deeper and more informative feature maps, while reducing training complexity in each round of spatio-temporal fusion.
ARTNet [213]은 새로운 building block을 사용하여 외관 및 관계 네트워크를 도입합니다.
ARTNet [213] introduces an appearance-and-relation network by using a new building block.
building block은 2D CNN을 사용하는 spatial branch와 3D CNN을 사용하는 relation branch로 구성됩니다.
The building block consists of a spatial branch using 2D CNNs and a relation branch using 3D CNNs.
S3D[239]는 위에서 언급한 접근 방식의 장점을 결합합니다.
S3D [239] combines the merits from approaches mentioned above.
먼저 네트워크 하단의 3D 컨볼루션을 2D 커널로 대체하고 이러한 종류의 상단이 무거운 네트워크가 인식 정확도가 더 높다는 것을 발견합니다.
It first replaces the 3D convolutions at the bottom of the network with 2D kernels, and find that this kind of top-heavy network has higher recognition accuracy.
그런 다음 S3D는 P3D 및 R2+1D처럼 나머지 3D 커널을 분해하여 모델 크기와 교육 복잡성을 더욱 줄입니다.
Then S3D factorizes the remaining 3D kernels as P3D and R2+1D do, to further reduce the model size and training complexity.
ECO [283]도 온라인 비디오 이해를 달성하기 위해 이러한 top-heavy 네트워크를 채택합니다.
A concurrent work named ECO [283] also adopts such a top-heavy network to achieve online video understanding.
3.3.3 Long-range temporal modeling
3D CNN에서 긴 범위의 시간적 연결은 예를 들어 3×3×3 필터와 같은 여러 개의 짧은 시간적 컨볼루션을 쌓아서 달성할 수 있습니다.
In 3D CNNs, long-range temporal connection may be achieved by stacking multiple short temporal convolutions, e.g., 3×3×3 filters.
그러나 특히 멀리 떨어져 있는 프레임의 경우 심층 네트워크의 후반 단계에서 유용한 시간 정보가 손실될 수 있습니다.
However, useful temporal information may be lost in the later stages of a deep network, especially for frames far apart.
장거리 시간 모델링을 수행하기 위해 LTC [206]는 많은 수의 비디오 프레임에 대한 장기 시간 컨벌루션을 도입하고 평가합니다.
In order to perform long-range temporal modeling, LTC [206] introduces and evaluates long-term temporal convolutions over a large number of video frames.
그러나 GPU 메모리에 의해 제한되어 더 많은 프레임을 사용하려면 입력 해상도를 희생해야 합니다.
However, limited by GPU memory, they have to sacrifice input resolution to use more frames.
그 후 T3D[32]는 조밀하게 연결된 구조[83]를 채택하여 원래 시간 정보를 최대한 완전하게 유지하여 최종 예측을 수행했습니다.
After that, T3D [32] adopted a densely connected structure [83] to keep the original temporal information as complete as possible to make the final prediction.
나중에 Wang et al. [219] 비로컬(non-local)이라는 새로운 빌딩 블록을 도입했습니다.
Later, Wang et al. [219] introduced a new building block, termed non-local.
Non-local은 플러그 앤 플레이 방식으로 많은 컴퓨터 비전 작업에 사용할 수 있는 self-attention[207]과 유사한 일반적인 작업입니다.
Non-local is a generic operation similar to self-attention [207], which can be used for many computer vision tasks in a plug-and-play manner.
그림 6에서 볼 수 있듯이, 그들은 공간 및 시간 영역 모두에서 장거리 의존성을 포착하기 위해 나중 잔차 블록 이후에 시공간 비국소 모듈을 사용했고 종소리 없이 기준선에 비해 향상된 성능을 달성했습니다.
As shown in Figure 6, they used a spacetime non-local module after later residual blocks to capture the long-range dependence in both space and temporal domain, and achieved improved performance over baselines without bells and whistles.
Wuet al. [229]는 상황 인식 예측을 위해 전체 비디오의 정보를 메모리 셀에 임베딩하는 특징 뱅크 표현을 제안했습니다.
Wu et al. [229] proposed a feature bank representation, which embeds information of the entire video into a memory cell, to make context-aware prediction.
최근 V4D[264]는 4D 컨볼루션을 사용한 장거리 시공간 표현의 진화를 모델링하기 위해 비디오 수준의 4D CNN을 제안했습니다.
Recently, V4D [264] proposed video-level 4D CNNs, to model the evolution of long-range spatio-temporal representation with 4D convolutions.
3.3.4 Enhancing 3D efficiency
3D CNN의 효율성을 더욱 향상시키기 위해(즉, GFLOP, 모델 매개변수 및 대기 시간 측면에서) 3D CNN의 많은 변형이 등장하기 시작했습니다.
In order to further improve the efficiency of 3D CNNs (i.e., in terms of GFLOPs, model parameters and latency), many variants of 3D CNNs begin to emerge.
효율적인 2D 네트워크의 개발에 동기를 부여받은 연구자들은 채널별로 분리 가능한 컨벌루션을 채택하고 비디오 분류를 위해 확장하기 시작했습니다[111, 203].
Motivated by the development in efficient 2D networks, researchers started to adopt channel-wise separable convolution and extend it for video classification [111, 203].
CSN [203]은 채널 상호 작용과 시공간 상호 작용을 분리하여 3D 컨볼루션을 분해하는 것이 좋은 방법이며 이전 최상의 접근 방식보다 2~3배 빠르면서도 최신 성능을 얻을 수 있음을 밝혔습니다.
CSN [203] reveals that it is a good practice to factorize 3D convolutions by separating channel interactions and spatiotemporal interactions, and is able to obtain state-of-the-art performance while being 2 to 3 times faster than the previous best approaches.
이러한 방법은 모두 group convolution에서 영감을 받았기 때문에 multi-fiber networks [20]와도 관련이 있습니다.
These methods are also related to multi-fiber networks [20] as they are all inspired by group convolution.
최근 Feichtenhofer et al. [45]는 slow pathway와 fast path way를 가진 효율적인 네트워크인 SlowFast를 제안했습니다.
Recently, Feichtenhofer et al. [45] proposed SlowFast, an efficient network with a slow pathway and a fast path way.
네트워크 디자인은 부분적으로 영장류 시각 시스템의 생물학적 파보 및 마그노셀룰러 세포에서 영감을 받았습니다.
The network design is partially inspired by the biological Parvo- and Magnocellular cells in the primate visual systems.
그림 6에서 볼 수 있듯이 느린 경로는 세부적인 의미론적 정보를 캡처하기 위해 낮은 프레임 속도에서 작동하는 반면 빠른 경로는 빠르게 변화하는 움직임을 캡처하기 위해 높은 시간 해상도에서 작동합니다.
As shown in Figure 6, the slow pathway operates at low frame rates to capture detailed semantic information, while the fast pathway operates at high temporal resolution to capture rapidly changing motion.
two-stream networks와 같은 동작 정보를 통합하기 위해 SlowFast는 측면 연결을 채택하여 각 경로에서 학습한 표현을 융합합니다.
In order to incorporate motion information such as in two-stream networks, SlowFast adopts a lateral connection to fuse the representation learned by each pathway.
빠른 경로는 채널 용량을 줄임으로써 매우 가볍게 만들 수 있으므로 SlowFast의 전반적인 효율성이 크게 향상됩니다.
Since the fast pathway can be made very lightweight by reducing its channel capacity, the overall efficiency of SlowFast is largely improved.
SlowFast는 두 개의 경로를 가지고 있지만 두 개의 경로가 공간 및 시간 모델링이 아닌 다른 시간 속도를 모델링하도록 설계되었기 때문에 두 개의 스트림 네트워크[187]와 다릅니다.
Although SlowFast has two pathways, it is different from the two-stream networks [187], because the two pathways are designed to model different temporal speeds, not spatial and temporal modeling.
정확성과 효율성의 균형을 맞추기 위해 여러 경로를 사용하는 여러 동시 논문이 있습니다[43].
There are several concurrent papers using multiple pathways to balance the accuracy and efficiency [43].
이 라인에 따라 Feichtenhofer [44]는 시간 지속 시간, 프레임 속도, 공간 해상도, 너비, 병목 너비 및 깊이와 같은 여러 네트워크 축을 따라 2D 이미지 분류 아키텍처를 점진적으로 확장하는 X3D를 도입했습니다.
Following this line, Feichtenhofer [44] introduced X3D that progressively expand a 2D image classification architecture along multiple network axes, such as temporal duration, frame rate, spatial resolution, width, bottleneck width, and depth.
X3D는 3D model modification/factorization를 극한까지 밀어붙이며 대상 복잡성의 다양한 요구 사항을 충족하는 효율적인 비디오 네트워크 제품군입니다.
X3D pushes the 3D model modification/factorization to an extreme, and is a family of efficient video networks to meet different requirements of target complexity.
유사한 정신으로 A3D[276]도 다중 네트워크 구성을 활용합니다.
With similar spirit, A3D [276] also leverages multiple network configurations.
그러나 A3D는 이러한 구성을 공동으로 교육하고 추론 중에 하나의 모델만 배포합니다.
However, A3D trains these configurations jointly and during inference deploys only one model.
이것은 결국 모델을 더 효율적으로 만듭니다.
This makes the model at the end more efficient.
다음 섹션에서는 효율적인 비디오 모델링에 대해 계속 이야기하지만 3D 컨볼루션을 기반으로 하지 않습니다.
In the next section, we will continue to talk about efficient video modeling, but not based on 3D convolutions.
3.4. Efficient Video Modeling
데이터 세트 크기의 증가와 배포의 필요성으로 인해 효율성이 중요한 관심사가 되었습니다.
With the increase of dataset size and the need for deployment, efficiency becomes an important concern.
two-stream networks 기반 방법을 사용하는 경우 optical flow를 미리 계산하고 로컬 디스크에 저장해야 합니다.
If we use methods based on two-stream networks, we need to pre-compute optical flow and store them on local disk.
Kinetics400 데이터 세트를 예로 들어 모든 optical flow 이미지를 저장하려면 4.5TB의 디스크 공간이 필요합니다.
Taking Kinetics400 dataset as an illustrative example, storing all the optical flow images requires 4.5TB disk space.
이러한 엄청난 양의 데이터로 인해 I/O는 훈련 중에 가장 빡빡한 병목 현상이 되어 GPU 리소스가 낭비되고 실험 주기가 길어집니다.
Such a huge amount of data would make I/O become the tightest bottleneck during training, leading to a waste of GPU resources and longer experiment cycle.
또한 pre-computing optical flow은 저렴하지 않습니다. 이는 모든 two-stream networks 방법이 실시간이 아님을 의미합니다.
In addition, pre-computing optical flow is not cheap, which means all the two-stream networks methods are not real-time.
3D CNN을 기반으로 하는 방법을 사용하는 경우 사람들은 여전히 3D CNN이 훈련하기 어렵고 배포하기 어렵다는 것을 알게 됩니다.
If we use methods based on 3D CNNs, people still find that 3D CNNs are hard to train and challenging to deploy.
training 측면에서 고급 8-GPU 머신을 사용하여 Kinetics400 데이터 세트에서 교육된 표준 SlowFast 네트워크는 완료하는 데 10일이 걸립니다.
In terms of training, a standard SlowFast network trained on Kinetics400 dataset using a high-end 8-GPU machine takes 10 days to complete.
이러한 긴 실험 주기와 막대한 컴퓨팅 비용으로 인해 비디오 이해 연구는 컴퓨팅 리소스가 풍부한 대기업/연구소에서만 접근할 수 있습니다.
Such a long experimental cycle and huge computing cost makes video understanding research only accessible to big companies/labs with abundant computing resources.
딥 비디오 모델 [230]의 훈련 속도를 높이려는 최근 몇 가지 시도가 있지만 대부분의 이미지 기반 컴퓨터 비전 작업에 비해 여전히 비용이 많이 듭니다.
There are several recent attempts to speed up the training of deep video models [230], but these are still expensive compared to most image-based computer vision tasks.
배포 측면에서 3D 컨볼루션은 다른 플랫폼에 대해 2D 컨볼루션만큼 잘 지원되지 않습니다.
In terms of deployment, 3D convolution is not as well supported as 2D convolution for different platforms.
또한 3D CNN은 추가 IO 비용을 추가하는 입력으로 더 많은 비디오 프레임을 필요로 합니다.
Furthermore, 3D CNNs require more video frames as input which adds additional IO cost.
이에 연구원들은 2018년부터 동영상 동작 인식의 정확성과 효율성을 동시에 향상시킬 수 있는 다른 대안을 조사하기 시작했습니다.
Hence, starting from year 2018, researchers started to investigate other alternatives to see how they could improve accuracy and efficiency at the same time for video action recognition.
아래의 여러 범주에서 최근의 효율적인 비디오 모델링 방법을 검토할 것입니다.
We will review recent efficient video modeling methods in several categories below.
3.4.1 Flow-mimic approaches
two-stream networks의 주요 단점 중 하나는 optical flow가 필요하다는 것입니다.
One of the major drawback of two-stream networks is its need for optical flow.
Pre-computing optical flow은 계산 비용이 많이 들고 저장 공간이 많이 필요하며 비디오 동작 인식을 위해 종단 간 훈련이 불가능합니다.
Pre-computing optical flow is computationally expensive, storage demanding, and not end-to-end trainable for video action recognition.
적어도 추론 시간 동안 optical flow을 사용하지 않고 모션 정보를 인코딩하는 방법을 찾을 수 있다면 매력적입니다.
It is appealing if we can find a way to encode motion information without using optical flow, at least during inference time.
[146]과 [35]는 비디오 동작 인식을 위한 네트워크 내부의 optical flow을 추정하는 학습을 위한 초기 시도입니다.
[146] and [35] are early attempts for learning to estimate optical flow inside a network for video action recognition.
이 두 가지 접근 방식은 추론 중에 optical flow이 필요하지 않지만 flow estimation network를 훈련시키기 위해 훈련 중에 optical flow가 필요합니다.
Although these two approaches do not need optical flow during inference, they require optical flow during training in order to train the flow estimation network.
Hidden two-stream networks[278]는 기존의 optical flow 계산을 대체하기 위해 MotionNet을 제안했습니다.
Hidden two-stream networks [278] proposed MotionNet to replace the traditional optical flow computation.
MotionNet은 unsupervised manner로 동작 정보를 학습하는 경량 네트워크이며 temporal stream과 연결될 때 end-to-end 학습이 가능합니다.
MotionNet is a lightweight network to learn motion information in an unsupervised manner, and when concatenated with the temporal stream, is end-to-end trainable.
따라서 hidden twostream CNNs[278]은 원시 비디오 프레임만 입력으로 사용하고 훈련 또는 추론 단계에 관계없이 optical flow을 명시적으로 계산하지 않고 동작 클래스를 직접 예측합니다.
Thus, hidden twostream CNNs [278] only take raw video frames as input and directly predict action classes without explicitly computing optical flow, regardless of whether its the training or inference stage.
PAN [257]은 consecutive feature maps 간의 차이를 계산하여 optical flow features을 모방합니다.
PAN [257] mimics the optical flow features by computing the difference between consecutive feature maps.
이 방향에 따라 [197, 42, 116, 164]는 데이터에서 optical flow와 유사한 기능을 학습하기 위해 end-to-end 훈련 가능한 CNN을 계속 조사합니다.
Following this direction, [197, 42, 116, 164] continue to investigate end-to-end trainable CNNs to learn opticalflow-like features from data.
그들은 광학 흐름의 정의에서 직접 그러한 features를 도출합니다[255].
They derive such features directly from the definition of optical flow [255].
MARS[26] 및 D3D[191]는 예를 들어 시간 스트림의 출력을 예측하기 위해 공간 스트림을 조정하여 이중 스트림 네트워크를 단일 스트림으로 결합하기 위해 knowledge distillation를 사용했습니다.
MARS [26] and D3D [191] used knowledge distillation to combine twostream networks into a single stream, e.g., by tuning the spatial stream to predict the outputs of the temporal stream.
최근 Kwon et al. [110] 모션 특징을 추정하기 위해 MotionSqueeze 모듈을 도입했습니다.
Recently, Kwon et al. [110] introduced MotionSqueeze module to estimate the motion features.
제안된 모듈은 end-to-end 훈련이 가능하며 [278]과 유사하게 모든 네트워크에 연결할 수 있습니다.
The proposed module is end-to-end trainable and can be plugged into any network, similar to [278].
3.4.2 Temporal modeling without 3D convolution
프레임 간의 시간적 관계를 모델링하기 위한 간단하고 자연스러운 선택은 3D 컨볼루션을 사용하는 것입니다.
A simple and natural choice to model temporal relationship between frames is using 3D convolution.
그러나 이 목표를 달성하기 위한 많은 대안이 있습니다.
However, there are many alternatives to achieve this goal.
여기에서는 3D 컨볼루션 없이 시간적 모델링을 수행하는 최근 작업을 검토합니다.
Here, we will review some recent work that performs temporal modeling without 3D convolution.
Lin et al. TSM(Temporal Shift Module)이라는 새로운 방법을 소개합니다.
Lin et al. [128] introduce a new method, termed temporal shift module (TSM).
TSM은 shift operation[228]을 비디오 이해로 확장합니다.
TSM extends the shift operation [228] to video understanding.
시간적 차원을 따라 채널의 일부를 이동하여 이웃 프레임 간에 정보 교환을 용이하게 합니다.
It shifts part of the channels along the temporal dimension, thus facilitating information exchanged among neighboring frames.
spatial feature 학습 능력을 유지하기 위해 residual block의 residual branch 내부에 시간 이동 모듈을 넣었습니다.
In order to keep spatial feature learning capacity, they put temporal shift module inside the residual branch in a residual block.
따라서 원래 활성화의 모든 정보는 ID 매핑을 통해 시간 이동 후에도 여전히 액세스할 수 있습니다.
Thus all the information in the original activation is still accessible after temporal shift through identity mapping.
TSM의 가장 큰 장점은 2D CNN에 삽입하여 zero computation and zero parameters에서 시간 모델링을 달성할 수 있다는 것입니다.
The biggest advantage of TSM is that it can be inserted into a 2D CNN to achieve temporal modeling at zero computation and zero parameters.
TSM과 유사하게 TIN[182]은 시간 컨벌루션을 모델링하기 위해 시간 인터레이스 모듈을 도입합니다.
Similar to TSM, TIN [182] introduces a temporal interlacing module to model the temporal convolution.
장기 시간 모델링 [92, 122, 132, 133]을 수행하기 위해 주의를 사용하는 몇 가지 최근 2D CNN 접근 방식이 있습니다.
There are several recent 2D CNNs approaches using attention to perform long-term temporal modeling [92, 122, 132, 133].
STM[92]에서는 시공간적 특징을 표현하기 위한 채널별 시공간 모듈과 움직임 특징을 효율적으로 부호화하기 위한 채널별 모션 모듈을 제안한다.
STM [92] proposes a channel-wise spatiotemporal module to present the spatio-temporal features and a channel-wise motion module to efficiently encode motion features.
TEA[122]는 STM과 유사하지만 SENet[81]에서 영감을 얻은 TEA는 동작 패턴을 향상시키기 위해 시공간적 특징을 재보정하기 위해 동작 특징을 사용합니다.
TEA [122] is similar to STM, but inspired by SENet [81], TEA uses motion features to recalibrate the spatio-temporal features to enhance the motion pattern.
특히 TEA에는 두 가지 구성 요소가 있습니다. motion excitation 및 multiple temporal aggregation, 첫 번째는 단거리 모션 모델링을 처리하고 두 번째는 장거리 시간 모델링을 위해 시간 수용 필드를 효율적으로 확장합니다.
Specifically, TEA has two components: motion excitation and multiple temporal aggregation, while the first one handles short-range motion modeling and the second one efficiently enlarge the temporal receptive field for long-range temporal modeling.
그것들은 상호 보완적이고 가볍기 때문에 TEA는 FLOP를 많은 2D CNN만큼 낮게 유지하면서 이전 최고의 접근 방식으로 경쟁력 있는 결과를 얻을 수 있습니다.
They are complementary and both light-weight, thus TEA is able to achieve competitive results with previous best approaches while keeping FLOPs as low as many 2D CNNs.
최근에 TEINet[132]도 시간적 모델링을 향상시키기 위해 주의를 기울였습니다.
Recently, TEINet [132] also adopts attention to enhance temporal modeling.
위의 어텐션 기반 방법은 비로컬 어텐션을 사용하는 반면 채널 어텐션을 사용하기 때문에 논로컬[219]과 다릅니다.
Note that, the above attention-based methods are different from nonlocal [219], because they use channel attention while nonlocal uses spatial attention.
3.5. Miscellaneous
이 섹션에서는 지난 10년 동안 비디오 동작 인식에 널리 사용된 몇 가지 다른 방향을 보여드리겠습니다.
In this section, we are going to show several other directions that are popular for video action recognition in the last decade.
3.5.1 Trajectory-based methods
CNN 기반 접근 방식이 그 우수성을 입증하고 점차 전통적인 수작업 방법을 대체했지만, 전통적인 local feature pipeline은 여전히 궤적 사용과 같은 무시할 수 없는 장점을 가지고 있습니다.
While CNN-based approaches have demonstrated their superiority and gradually replaced the traditional hand-crafted methods, the traditional local feature pipeline still has its merits which should not be ignored, such as the usage of trajectory.
trajectory-based methods[210]의 우수한 성능에 영감을 받아 Wang et al. [214]는 깊은 컨벌루션 기능을 효과적인 디스크립터로 집계하기 위해 trajectory-constrained pooling을 수행할 것을 제안했으며, 이를 TDD라고 합니다.
Inspired by the good performance of trajectory-based methods [210], Wang et al. [214] proposed to conduct trajectory-constrained pooling to aggregate deep convolutional features into effective descriptors, which they term as TDD.
여기서 궤적(trajectory )은 시간적 차원에서 픽셀을 추적하는 경로로 정의됩니다.
Here, a trajectory is defined as a path tracking down pixels in the temporal dimension.
이 새로운 비디오 표현은 hand-crafted features와 딥 러닝 기능의 장점을 모두 공유하며 2015년 UCF101 및 HMDB51 데이터 세트 모두에서 최고의 성능 중 하나가 되었습니다.
This new video representation shares the merits of both hand-crafted features and deep-learned features, and became one of the top performers on both UCF101 and HMDB51 datasets in the year 2015.
동시에 Lan et al. [113]은 ISA(Independent Subspace Analysis)와 dense trajectories을 표준 two-stream networks에 통합했으며 데이터 독립적 접근 방식과 데이터 기반 접근 방식 간의 보완성을 보여줍니다.
Concurrently, Lan et al. [113] incorporated both Independent Subspace Analysis (ISA) and dense trajectories into the standard two-stream networks, and show the complementarity between data-independent and data-driven approaches.
CNN을 고정된 특징 추출기로 취급하는 대신 Zhao et al. [268] 궤적의 도움으로 시간적 차원을 따라 특징을 학습하기 위해 궤적 콘볼루션을 제안했습니다.
Instead of treating CNNs as a fixed feature extractor, Zhao et al. [268] proposed trajectory convolution to learn features along the temporal dimension with the help of trajectories.
3.5.2 Rank pooling
비디오 내에서 시간 정보를 모델링하는 또 다른 방법은 Rank pooling(일명 learning-to-rank)이라고 합니다.
There is another way to model temporal information inside a video, termed rank pooling (a.k.a learning-to-rank).
이 라인의 중요한 작업은 VideoDarwin[53]에서 시작하는데, ranking machine를 사용하여 시간 경과에 따른 모양의 진화를 학습하고 ranking function을 반환합니다.
The seminal work in this line starts from VideoDarwin [53], that uses a ranking machine to learn the evolution of the appearance over time and returns a ranking function.
순위 함수는 비디오의 프레임을 시간적으로 정렬할 수 있어야 하므로 이 순위 함수의 매개 변수를 새로운 비디오 표현으로 사용합니다.
The ranking function should be able to order the frames of a video temporally, thus they use the parameters of this ranking function as a new video representation.
VideoDarwin[53]은 딥 러닝 기반 방법은 아니지만 유사한 성능과 효율성을 달성합니다.
VideoDarwin [53] is not a deep learning based method, but achieves comparable performance and efficiency.
딥 러닝에 rank pooling을 적용하기 위해 Fernando[54]는 종단 간 기능 학습을 달성하기 위해 차별화 가능한 rank pooling layer을 도입했습니다.
To adapt rank pooling to deep learning, Fernando [54] introduces a differentiable rank pooling layer to achieve endto-end feature learning.
이 방향에 따라 Bilen et al. [9] 동적 이미지라고 하는 비디오당 단일 RGB 이미지를 생성하는 비디오의 원시 이미지 픽셀에 rank pooling을 적용합니다.
Following this direction, Bilen et al. [9] apply rank pooling on the raw image pixels of a video producing a single RGB image per video, termed dynamic images.
Fernando [51]의 또 다른 동시 작업은 여러 수준의 시간 인코딩을 쌓아 순위 풀링을 계층적 순위 풀링으로 확장합니다.
Another concurrent work by Fernando [51] extends rank pooling to hierarchical rank pooling by stacking multiple levels of temporal encoding.
마지막으로 [22]는 하위 공간 표현을 사용하여 원래 순위 공식[53]의 일반화를 제안하고 계산 비용이 저렴하면서 동작의 동적 진화를 훨씬 더 잘 표현할 수 있음을 보여줍니다.
Finally, [22] propose a generalization of the original ranking formulation [53] using subspace representations and show that it leads to significantly better representation of the dynamic evolution of actions, while being computationally cheap.
3.5.3 Compressed video action recognition
대부분의 비디오 동작 인식 방식은 원시 비디오(또는 디코딩된 비디오 프레임)를 입력으로 사용합니다.
Most video action recognition approaches use raw videos (or decoded video frames) as input.
그러나 원시 비디오를 사용하는 데는 엄청난 양의 데이터와 높은 시간적 중복성과 같은 몇 가지 단점이 있습니다.
However, there are several drawbacks of using raw videos, such as the huge amount of data and high temporal redundancy.
비디오 압축 방법은 일반적으로 다른 프레임(즉, I-프레임)의 콘텐츠를 재사용하여 하나의 프레임을 저장하고 인접한 프레임이 유사하다는 사실로 인해 차이점(즉, P-프레임 및 B-프레임)만 저장합니다.
Video compression methods usually store one frame by reusing contents from another frame (i.e., I-frame) and only store the difference (i.e., P-frames and B-frames) due to the fact that adjacent frames are similar.
여기서 I-프레임은 원본 RGB 비디오 프레임이고, P-프레임과 B-프레임에는 차이를 저장하는 데 사용되는 움직임 벡터와 레지듀얼이 포함됩니다.
Here, the I-frame is the original RGB video frame, and P-frames and B-frames include the motion vector and residual, which are used to store the difference.
비디오 압축 영역의 발전에 동기를 부여받은 연구원들은 효과적인 비디오 모델을 훈련하기 위한 입력으로 압축된 비디오 표현을 채택하기 시작했습니다.
Motivated by the developments in the video compression domain, researchers started to adopt compressed video representations as input to train effective video models.
motion vector 는 구조가 거칠고 부정확한 움직임을 포함할 수 있으므로 Zhang et al. motion-vector-based temporal stream이 optical-flow-based temporal stream을 모방하도록 돕기 위해 knowledge distillation를 채택했습니다.
Since the motion vector has coarse structure and may contain inaccurate movements, Zhang et al. [256] adopted knowledge distillation to help the motion-vector-based temporal stream mimic the optical-flow-based temporal stream.
그러나 그들의 접근 방식은 각 프레임을 추출하고 처리해야 했습니다.
However, their approach required extracting and processing each frame.
그들은 표준 two-stream networks로 비슷한 인식 정확도를 얻었지만 27배 더 빨랐습니다.
They obtained comparable recognition accuracy with standard two-stream networks, but were 27 times faster.
Wuet al. [231] I 프레임에는 Heavyweight CNN을, P 프레임에는 Lightweight CNN을 사용했습니다.
Wu et al. [231] used a heavyweight CNN for the I frame and lightweight CNN’s for the P frames.
이것은 각각의 P 프레임에 대한 motion vectors 와 잔차(residuals)가 축적에 의해 I 프레임으로 다시 참조되어야 한다는 것을 요구했습니다.
This required that the motion vectors and residuals for each P frame be referred back to the I frame by accumulation.
DMC-Net[185]은 적대적 손실(adversarial loss)을 사용하는 [231]의 후속 작업입니다.
DMC-Net [185] is a follow-up work to [231] using adversarial loss.
그것은 [256]에서와 같이 knowledge distillation 대신 fine motion details을 캡처하는 동작 벡터를 돕기 위해 경량 생성기 네트워크를 채택합니다.
It adopts a lightweight generator network to help the motion vector capturing fine motion details, instead of knowledge distillation as in [256].
최근 논문인 SCSampler[106]도 중요한 클립을 샘플링하기 위해 압축된 비디오 표현을 채택했으며 다음 섹션 3.5.4에서 이에 대해 논의할 것입니다.
A recent paper SCSampler [106], also adopts compressed video representation for sampling salient clips and we will discuss it in the next section 3.5.4.
아직까지 추가된 복잡성으로 인해 압축된 접근 방식 중 어느 것도 B 프레임을 처리할 수 없습니다.
As yet none of the compressed approaches can deal with B-frames due to the added complexity.
3.5.4 Frame/Clip sampling
앞서 언급한 대부분의 딥 러닝 방법은 최종 예측을 위해 모든 비디오 프레임/클립을 동등하게 취급합니다.
Most of the aforementioned deep learning methods treat every video frame/clip equally for the final prediction.
그러나 차별적 행동은 짧은 순간에만 발생하며 대부분의 다른 동영상 콘텐츠는 레이블이 지정된 행동 범주와 관련이 없거나 약합니다.
However, discriminative actions only happen in a few moments, and most of the other video content is irrelevant or weakly related to the labeled action category.
이 패러다임에는 몇 가지 단점이 있습니다.
There are several drawbacks of this paradigm.
첫째, 관련 없는 비디오 프레임이 많은 부분을 교육하면 성능이 저하될 수 있습니다.
First, training with a large proportion of irrelevant video frames may hurt performance.
둘째, 이러한 균일한 샘플링은 추론 중에 효율적이지 않습니다.
Second, such uniform sampling is not efficient during inference.
인간이 전체 비디오에서 몇 번만 보고 비디오를 이해하는 방식[251]에서 부분적으로 영감을 받아 성능을 개선하고 추론 중에 모델을 보다 효율적으로 만들기 위해 가장 유익한 비디오 프레임/클립을 샘플링하는 많은 방법이 제안되었습니다.
Partially inspired by how human understand a video using just a few glimpses over the entire video [251], many methods were proposed to sample the most informative video frames/clips for both improving the performance and making the model more efficient during inference.
KVM[277]은 키 볼륨을 동시에 식별하고 작업 분류를 수행하기 위해 end-to-end framework를 제안하려는 첫 번째 시도 중 하나입니다.
KVM [277] is one of the first attempts to propose an end-to-end framework to simultaneously identify key volumes and do action classification.
나중에 [98]은 각 비디오 프레임의 중요도 점수를 온라인 방식으로 예측하는 AdaScan을 소개하며 이를 adaptive temporal pooling이라고 합니다.
Later, [98] introduce AdaScan that predicts the importance score of each video frame in an online fashion, which they term as adaptive temporal pooling.
**이 두 방법 모두 향상된 성능을 달성하지만 여전히 추론 중에 효율성을 나타내지 않는 표준 평가 체계를 채택합니다. **
Both of these methods achieve improved performance, but they still adopt the standard evaluation scheme which does not show efficiency during inference.
최근 접근 방식은 효율성에 더 중점을 둡니다[41, 234, 8, 106].
Recent approaches focus more on the efficiency [41, 234, 8, 106].
AdaFrame [234]은 [251, 98]을 따르지만 보다 유익한 비디오 클립을 검색하기 위해 reinforcement learning 기반 접근 방식을 사용합니다.
AdaFrame [234] follows [251, 98] but uses a reinforcement learning based approach to search more informative video clips.
동시에, [8]은 teacher-student framework를 사용합니다. 즉, 모든 것을 볼 수 있는 교사를 사용하여 컴퓨팅 효율적으로 아주 작은 학생을 교육할 수 있습니다.
Concurrently, [8] uses a teacher-student framework, i.e., a see-it-all teacher can be used to train a compute efficient see-very-little student.
그들은 효율적인 학생 네트워크가 무시할 수 있는 성능 저하로 추론 시간을 30%까지 줄이고 FLOP 수를 약 90%까지 줄일 수 있음을 보여줍니다.
They demonstrate that the efficient student network can reduce the inference time by 30% and the number of FLOPs by approximately 90% with negligible performance drop.
최근에 SCSampler [106]는 압축된 비디오 표현을 기반으로 가장 두드러진 비디오 클립을 샘플링하고 Kinetics400 및 Sports1M 데이터 세트 모두에서 state-of-the-art performance을 달성하기 위해 경량 네트워크를 훈련합니다.
Recently, SCSampler [106] trains a lightweight network to sample the most salient video clips based on compressed video representations, and achieve state-of-the-art performance on both Kinetics400 and Sports1M dataset.
그들은 또한 이러한 현저성 기반 샘플링이 효율적일 뿐만 아니라 모든 비디오 프레임을 사용하는 것보다 더 높은 정확도를 갖는다는 것을 경험적으로 보여줍니다.
They also empirically show that such saliency-based sampling is not only efficient, but also enjoys higher accuracy than using all the video frames.
3.5.5 Visual tempo
Visual tempo는 동작이 얼마나 빨리 진행되는지를 나타내는 개념입니다.
Visual tempo is a concept to describe how fast an action goes.
많은 액션 클래스는 visual tempo가 다릅니다.
Many action classes have different visual tempos.
대부분의 경우, 걷기, 조깅, 달리기와 같이 visual appearance에서 높은 유사성을 공유할 수 있기 때문에 시각적 템포를 구분하는 핵심이 됩니다[248].
In most cases, the key to distinguish them is their visual tempos, as they might share high similarities in visual appearance, such as walking, jogging and running [248].
개선된 시간 모델링 [273, 147, 82, 281, 45, 248]을 위해 다양한 시간 속도(템포)를 탐색하는 여러 논문이 있습니다.
There are several papers exploring different temporal rates (tempos) for improved temporal modeling [273, 147, 82, 281, 45, 248].
초기 시도는 일반적으로 여러 속도로 원시 비디오를 샘플링하고 입력 레벨 프레임 피라미드를 구성하여 비디오 템포를 캡처합니다[273, 147, 281].
Initial attempts usually capture the video tempo through sampling raw videos at multiple rates and constructing an input-level frame pyramid [273, 147, 281].
최근 SlowFast[45]는 섹션 3.3.4에서 논의한 바와 같이 시각적 템포의 특성을 활용하여 더 나은 정확도와 효율성 트레이드오프를 위한 two-pathway network를 설계합니다.
Recently, SlowFast [45], as we discussed in section 3.3.4, utilizes the characteristics of visual tempo to design a two-pathway network for better accuracy and efficiency tradeoff.
CIDC[121]는 video temporal modeling을 위한 local backbone과 함께 방향성 temporal modeling을 제안했습니다.
CIDC [121] proposed directional temporal modeling along with a local backbone for video temporal modeling.
TPN[248]은 템포 모델링을 기능 수준으로 확장하고 이전 접근 방식에 비해 일관된 개선을 보여줍니다.
TPN [248] extends the tempo modeling to the featurelevel and shows consistent improvement over previous approaches.
우리는 시각적 템포가 딥 네트워크 훈련을 위한 감독 신호를 자연스럽게 제공할 수 있기 때문에 자기 감독 비디오 표현 학습[6, 247, 16]에서도 널리 사용된다는 점을 지적하고 싶습니다.
We would like to point out that visual tempo is also widely used in self-supervised video representation learning [6, 247, 16] since it can naturally provide supervision signals to train a deep network.
self-supervised video representation learning에 대한 자세한 내용은 섹션 5.13에서 논의할 것입니다.
We will discuss more details on self-supervised video representation learning in section 5.13.
4. Evaluation and Benchmarking
이 섹션에서는 벤치마크 데이터 세트에 대한 인기 있는 접근 방식을 비교합니다. 구체적으로 먼저 4.1절에서 표준 평가 체계를 소개합니다.
In this section, we compare popular approaches on benchmark datasets. To be specific, we first introduce standard evaluation schemes in section 4.1.
그런 다음 공통 벤치마크를 장면 중심(섹션 4.2의 UCF101, HMDB51 및 Kinetics400), 모션 중심(섹션 4.3의 Sth-Sth V1 및 V2) 및 다중 레이블(섹션 4.4의 Charades)의 세 가지 범주로 나눕니다.
Then we divide common benchmarks into three categories, scenefocused (UCF101, HMDB51 and Kinetics400 in section 4.2), motion-focused (Sth-Sth V1 and V2 in section 4.3) and multi-label (Charades in section 4.4).
마지막으로 4.5절에서 인식 정확도와 효율성 측면에서 널리 사용되는 방법을 공정하게 비교합니다.
In the end, we present a fair comparison among popular methods in terms of both recognition accuracy and efficiency in section 4.5.
4.1. Evaluation scheme
모델 학습 중에 일반적으로 비디오 프레임/클립을 임의로 선택하여 미니 배치 샘플을 형성합니다.
During model training, we usually randomly pick a video frame/clip to form mini-batch samples.
그러나 평가를 위해서는 공정한 비교를 수행하기 위해 표준화된 파이프라인이 필요합니다.
However, for evaluation, we need a standardized pipeline in order to perform fair comparisons.
2D CNN의 경우 널리 채택되는 평가 체계는 [187, 217]에 따라 각 비디오에서 25개 프레임을 고르게 샘플링하는 것입니다.
For 2D CNNs, a widely adopted evaluation scheme is to evenly sample 25 frames from each video following [187, 217].
각 프레임에 대해 4개의 모서리와 1개의 중앙을 자르고 수평으로 뒤집고 샘플의 모든 자르기에 대해 예측 점수(softmax 작업 전)를 평균화하여 ten-crop data augmentation를 수행합니다. 즉, 추론을 위해 비디오당 250프레임을 사용함을 의미합니다.
For each frame, we perform ten-crop data augmentation by cropping the 4 corners and 1 center, flipping them horizontally and averaging the prediction scores (before softmax operation) over all crops of the samples, i.e., this means we use 250 frames per video for inference.
3D CNN의 경우 30-view strategy 이라고 하는 널리 채택된 평가 체계는 [219]에 따라 각 비디오에서 10개의 클립을 고르게 샘플링하는 것입니다.
For 3D CNNs, a widely adopted evaluation scheme termed 30-view strategy is to evenly sample 10 clips from each video following [219].
각 비디오 클립에 대해 3회 자르기 데이터 증대를 수행합니다.
For each video clip, we perform three-crop data augmentation.
구체적으로, 우리는 더 짧은 공간 측면을 256픽셀로 확장하고 공간 차원을 커버하고 예측 점수의 평균을 내기 위해 256 × 256의 세 가지 크롭을 취합니다.
To be specific, we scale the shorter spatial side to 256 pixels and take three crops of 256 × 256 to cover the spatial dimensions and average the prediction scores.
그러나 평가 체계는 고정되어 있지 않습니다.
However, the evaluation schemes are not fixed.
그들은 새로운 네트워크 아키텍처와 다양한 데이터 세트에 맞게 진화하고 적응하고 있습니다.
They are evolving and adapting to new network architectures and different datasets.
예를 들어, TSM[128]은 작은 크기의 데이터 세트[190, 109]에 대해 비디오당 두 개의 클립만 사용하고, 2D CNN임에도 불구하고 각 클립에 대해 세 번의 자르기 데이터 확장을 수행합니다.
For example, TSM [128] only uses two clips per video for small-sized datasets [190, 109], and perform three-crop data augmentation for each clip despite its being a 2D CNN.
표준 평가 파이프라인과의 편차를 언급할 것입니다.
We will mention any deviations from the standard evaluation pipeline.
평가 메트릭 측면에서 단일 레이블 작업 인식에 대한 정확도와 다중 레이블 작업 인식에 대한 mAP(평균 평균 정밀도)를 보고합니다.
In terms of evaluation metric, we report accuracy for single-label action recognition, and mAP (mean average precision) for multi-label action recognition.
4.2. Scene-focused datasets
여기에서는 UCF101, HMDB51 및 Kinetics400과 같은 scene-focused datasets에 대한 state-of-the-art approaches을 비교합니다.
Here, we compare recent state-of-the-art approaches on scene-focused datasets: UCF101, HMDB51 and Kinetics400.
scene-focused이라고 부르는 이유는 이러한 데이터 세트의 대부분의 액션 비디오가 짧고 그림 4에 표시된 것처럼 정적 장면 모양만으로 인식할 수 있기 때문입니다.
The reason we call them scene-focused is because most action videos in these datasets are short, and can be recognized by static scene appearance alone as shown in Figure 4.
연표에 따라 딥 러닝과 two-stream networks를 사용한 초기 시도에 대한 결과를 먼저 표 2 상단에 제시합니다.
Following the chronology, we first present results for early attempts of using deep learning and the two-stream networks at the top of Table 2.
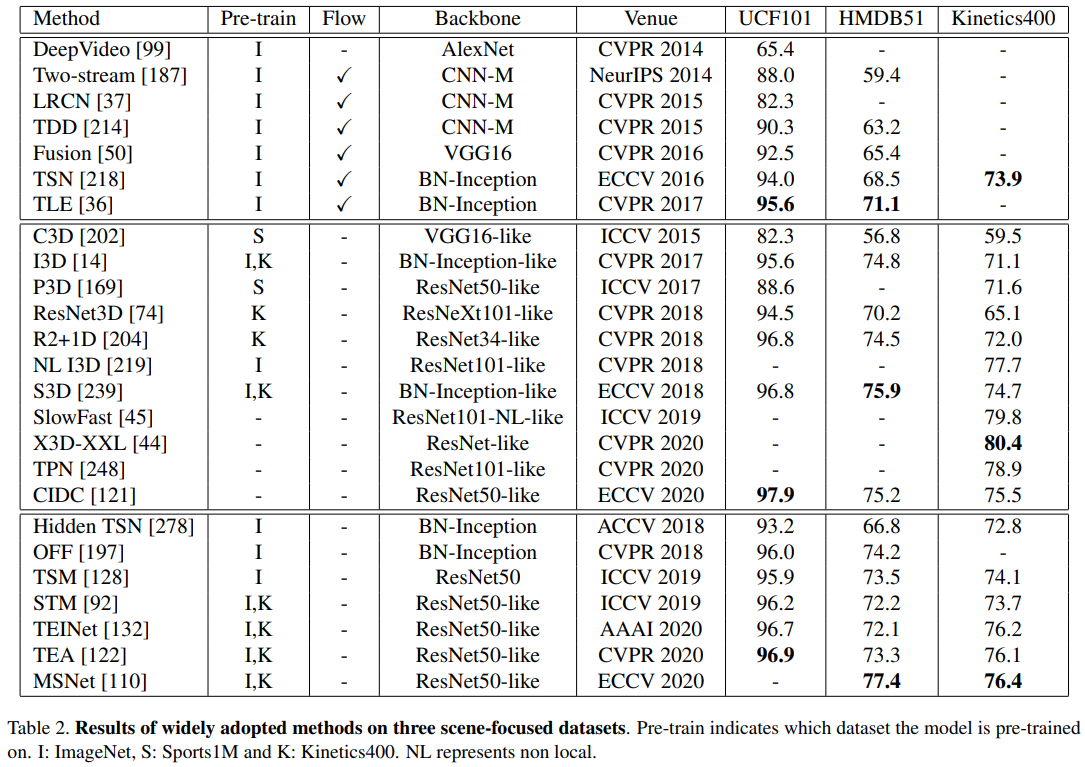
우리는 몇 가지 관찰을 합니다.
We make several observations.
첫째, 모션/시간 모델링이 없으면 DeepVideo[99]의 성능이 다른 모든 접근 방식보다 열등합니다.
First, without motion/temporal modeling, the performance of DeepVideo [99] is inferior to all other approaches.
둘째, 전통적인 방법(비 CNN 기반)에서 딥 러닝으로 지식을 이전하는 것이 도움이 됩니다.
Second, it is helpful to transfer knowledge from traditional methods (non-CNN-based) to deep learning.
예를 들어, TDD[214]는 궤적 풀링을 사용하여 동작 인식 CNN 기능을 추출합니다.
For example, TDD [214] uses trajectory pooling to extract motion-aware CNN features.
TLE[36]는 기존의 비디오 동작 인식 파이프라인에서 중요한 단계인 전역 기능 인코딩을 딥 네트워크에 내장합니다.
TLE [36] embeds global feature encoding, which is an important step in traditional video action recognition pipeline, into a deep network.
그런 다음 표 2의 중간에서 3D CNN 기반 접근 방식을 비교합니다.
We then compare 3D CNNs based approaches in the middle of Table 2.
많은 비디오 코퍼스에 대한 training에도 불구하고 C3D[202]는 동시 작업[187, 214, 217]에서 열악한 성능을 보이는데, 아마도 3D 커널 최적화의 어려움 때문일 것입니다.
Despite training on a large corpus of videos, C3D [202] performs inferior to concurrent work [187, 214, 217], possibly due to difficulties in optimization of 3D kernels.
이것에 동기를 부여하여 I3D[14], P3D[169], R2+1D[204] 및 S3D[239]와 같은 여러 논문에서 3D 컨볼루션 필터를 2D 공간 커널 및 1D 시간 커널로 분해하여 훈련을 용이하게 합니다.
Motivated by this, several papers - I3D [14], P3D [169], R2+1D [204] and S3D [239] factorize 3D convolution filters to 2D spatial kernels and 1D temporal kernels to ease the training.
또한 I3D는 잘 훈련된 2D 네트워크에서 3D 모델 가중치를 부트스트랩하여 처음부터 훈련하는 것을 방지하는 인플레이션 전략을 도입합니다.
In addition, I3D introduces an inflation strategy to avoid training from scratch by bootstrap ping the 3D model weights from well-trained 2D networks.
이러한 기술을 사용하여 optical flow 없이도 최상의 two-stream network 방법[36]에 필적하는 성능을 달성합니다.
By using these techniques, they achieve comparable performance to the best two-stream network methods [36] without the need for optical flow.
또한 최근 3D 모델은 더 많은 training samples[203], additional pathways[45] 또는 architecture search[44]을 사용하여 훨씬 더 높은 정확도를 얻습니다.
Furthermore, recent 3D models obtain even higher accuracy, by using more training samples [203], additional pathways [45], or architecture search [44].
마지막으로 표 2 하단에 최근의 효율적인 모델을 보여줍니다.
Finally, we show recent efficient models in the bottom of Table 2.
우리는 이러한 방법이 two-stream networks(상단)보다 더 높은 인식 정확도를 달성할 수 있고 3D CNN(중간)에 필적하는 성능을 달성할 수 있음을 볼 수 있습니다.
We can see that these methods are able to achieve higher recognition accuracy than two-stream networks (top), and comparable performance to 3D CNNs (middle).
2D CNN이고 광학 흐름을 사용하지 않기 때문에 이러한 방법은 Train 및 Inference 측면에서 모두 효율적입니다.
Since they are 2D CNNs and do not use optical flow, these methods are efficient in terms of both training and inference.
대부분 실시간 접근 방식이며 일부는 온라인 비디오 동작 인식이 가능합니다[128].
Most of them are real-time approaches, and some can do online video action recognition [128].
우리는 효율성의 필요성 때문에 2D CNN과 시간 모델링이 유망한 방향이라고 생각합니다.
We believe 2D CNN plus temporal modeling is a promising direction due to the need of efficiency.
여기서 시간 모델링은 attention based, flow based 또는 3D 커널 기반일 수 있습니다.
Here, temporal modeling could be attention based, flow based or 3D kernel based.
4.3. Motion-focused datasets
이 섹션에서는 20BN-Something-Something(Sth-Sth) 데이터 세트에 대한 최신 최신 접근 방식을 비교합니다.
In this section, we compare the recent state-of-the-art approaches on the 20BN-Something-Something (Sth-Sth) dataset.
V1과 V2 모두에서 최고 정확도 1위를 보고합니다. SthSth 데이터 세트는 일상적인 개체로 기본 작업을 수행하는 인간에 중점을 둡니다.
We report top1 accuracy on both V1 and V2. SthSth datasets focus on humans performing basic actions with daily objects.
scene-focused datasets와 달리 Sth-Sth 데이터세트의 배경 장면은 최종 액션 클래스 예측에 거의 기여하지 않습니다.
Different from scene-focused datasets, background scene in Sth-Sth datasets contributes little to the final action class prediction.
그 외에도 “왼쪽에서 오른쪽으로 밀기”, “오른쪽에서 왼쪽으로 밀기”와 같이 강력한 동작 추론이 필요한 클래스가 있습니다.
In addition, there are classes such as “Pushing something from left to right” and “Pushing something from right to left”, and which require strong motion reasoning.
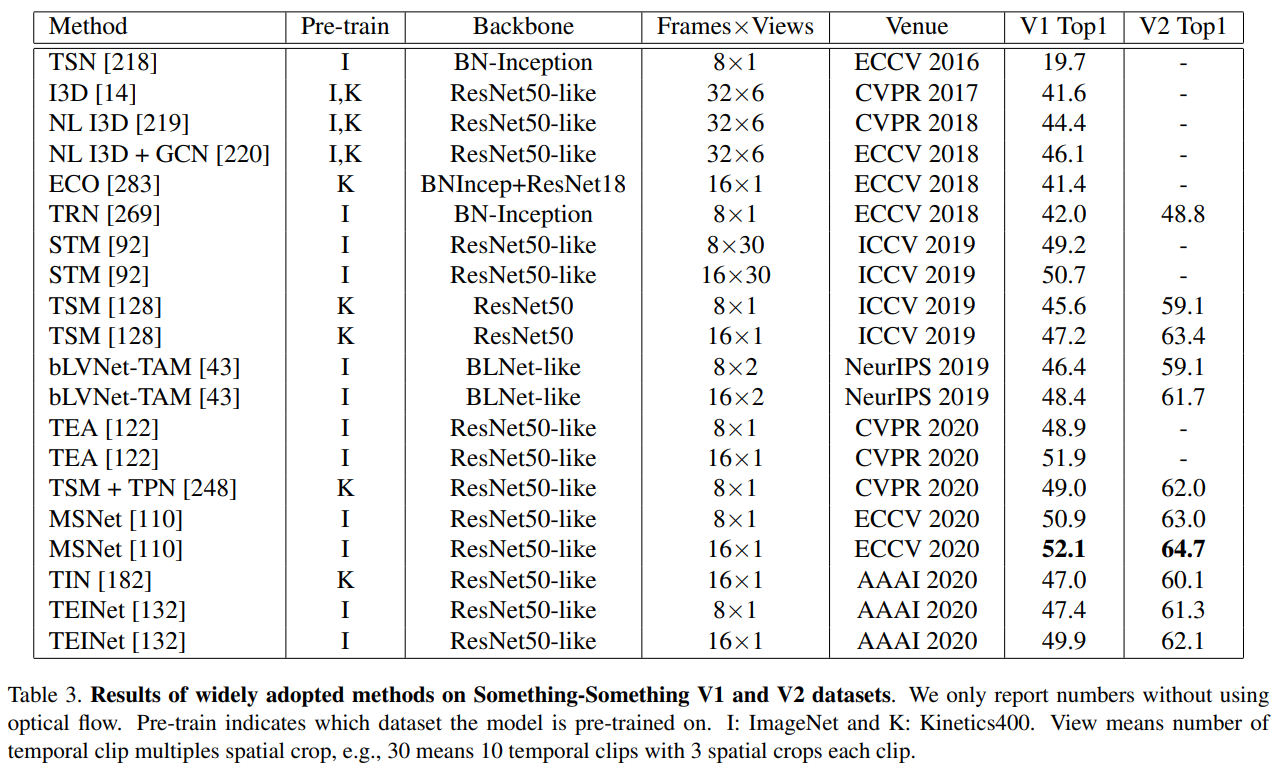
표 3의 이전 작업을 비교하면 더 긴 입력(예: 16프레임)을 사용하는 것이 일반적으로 더 좋다는 것을 알 수 있습니다.
By comparing the previous work in Table 3, we observe that using longer input (e.g., 16 frames) is generally better.
게다가, 시간적 모델링에 초점을 맞춘 방법[128, 122, 92]은 stacked 3D kernels[14]보다 더 잘 작동합니다.
Moreover, methods that focus on temporal modeling [128, 122, 92] work better than stacked 3D kernels [14].
예를 들어, TSM[128], TEA[122] 및 MSNet[110]은 명시적 temporal reasoning module을 2D ResNet 백본에 삽입하고 state-of-the-art 결과를 얻습니다.
For example, TSM [128], TEA [122] and MSNet [110] insert an explicit temporal reasoning module into 2D ResNet backbones and achieves state-of-the-art results.
이는 Sth-Sth 데이터셋이 공간적 의미론적 정보뿐만 아니라 강력한 시간적 움직임 추론을 필요로 함을 의미합니다.
This implies that the Sth-Sth dataset needs strong temporal motion reasoning as well as spatial semantics information.
4.4. Multi-label datasets
이 섹션에서는 먼저 Charades 데이터 세트 [186]에 대한 state-of-the art 접근 방식을 비교한 다음 Charades에 대한 모델 또는 추가 개체 정보를 사용하는 최근 작업을 나열합니다.
In this section, we first compare the recent state-of-the art approaches on Charades dataset [186] and then we list some recent work that use assemble model or additional object information on Charades.
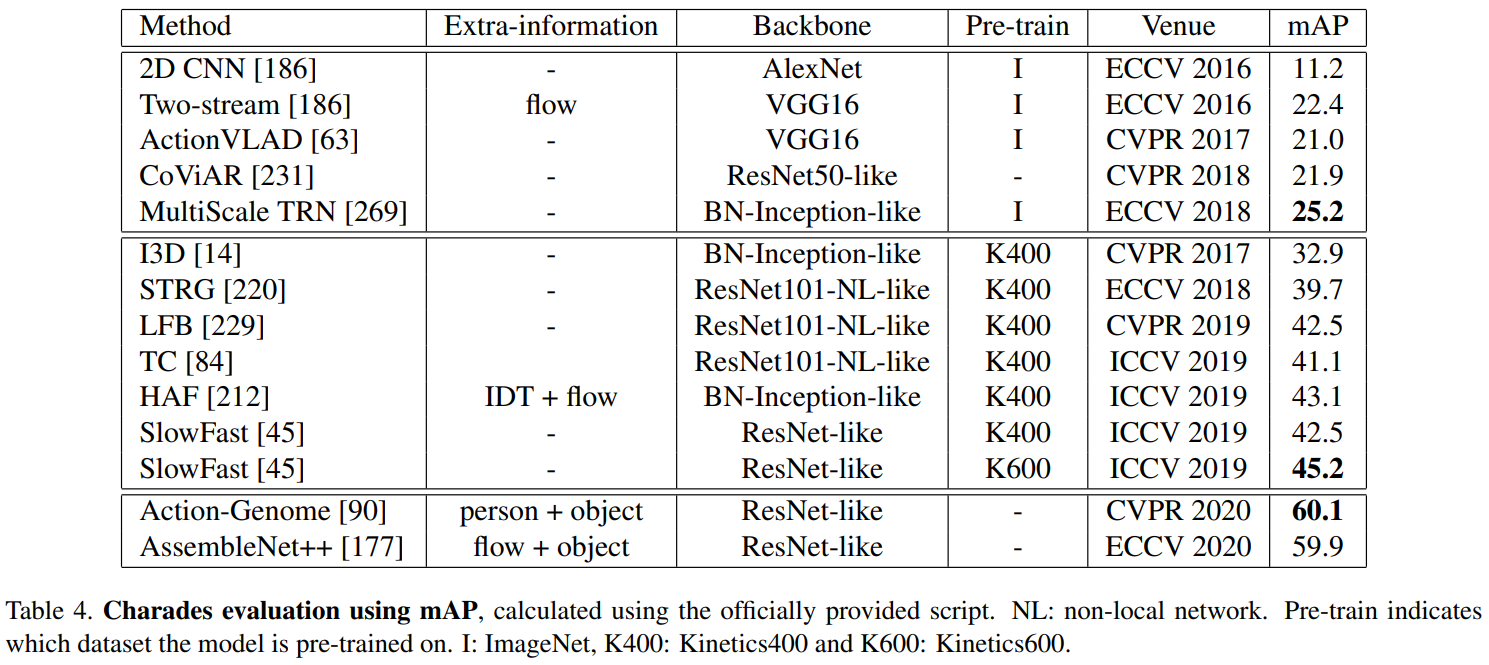
표 4의 이전 작업을 비교하여 다음과 같은 관찰을 수행합니다.
Comparing the previous work in Table 4, we make the following observations.
첫째, 3D 모델[229, 45]은 일반적으로 2D 모델[186, 231] 및 optical flow 입력이 있는 2D 모델보다 성능이 좋습니다.
First, 3D models [229, 45] generally perform better than 2D models [186, 231] and 2D models with optical flow input.
이것은 시공간 추론이 장기적으로 복잡한 동시 행동 이해에 중요하다는 것을 나타냅니다.
This indicates that the spatiotemporal reasoning is critical for long-term complex concurrent action understanding.
둘째, 더 긴 입력은 인식에 도움이 됩니다[229]. 아마도 일부 동작은 인식하는 데 장기적인 기능이 필요하기 때문입니다.
Second, longer input helps with the recognition [229] probably because some actions require long-term feature to recognize.
셋째, 더 큰 데이터 세트에서 사전 훈련된 강력한 백본을 가진 모델은 일반적으로 더 나은 성능을 보입니다[45].
Third, models with strong backbones that are pre-trained on larger datasets generally have better performance [45].
이는 Charades가 심층 모델을 교육하기에 충분한 다양성을 포함하지 않는 중간 규모의 데이터 세트이기 때문입니다.
This is because Charades is a medium-scaled dataset which doesn’t contain enough diversity to train a deep model.
최근 연구자들은 모델을 조립하거나[177], 추가적인 인간-객체 상호 작용 정보를 제공함으로써[90] 복잡한 동시 행동 인식을 위한 대안적 방향을 탐색했습니다.
Recently, researchers explored the alternative direction for complex concurrent action recognition by assembling models [177] or providing additional human-object interaction information [90].
이 논문은 Charades에서 단일 모델만 미세 조정하는 이전 문헌보다 훨씬 뛰어난 성능을 보였습니다.
These papers significantly outperformed previous literature that only finetune a single model on Charades.
시공간적 인간-객체 상호 작용을 탐색하고 과적합을 방지하는 방법을 찾는 것이 동시 작업 이해의 핵심임을 보여줍니다.
It demonstrates that exploring spatio-temporal human-object interactions and finding a way to avoid overfitting are the keys for concurrent action understanding.
4.5. Speed comparison
실제 응용 프로그램에 모델을 배포하려면 일반적으로 진행하기 전에 모델이 속도 요구 사항을 충족하는지 여부를 알아야 합니다.
To deploy a model in real-life applications, we usually need to know whether it meets the speed requirement before we can proceed.
이 섹션에서는 (1) 매개변수 수, (2) FLOPS, (3) 대기 시간 및 (4) 초당 프레임 측면에서 철저한 비교를 수행하기 위해 위에서 언급한 접근 방식을 평가합니다.
In this section, we evaluate the approaches mentioned above to perform a thorough comparison in terms of (1) number of parameters, (2) FLOPS, (3) latency and (4) frame per second.
결과를 표 5에 제시합니다.
We present the results in Table 5.
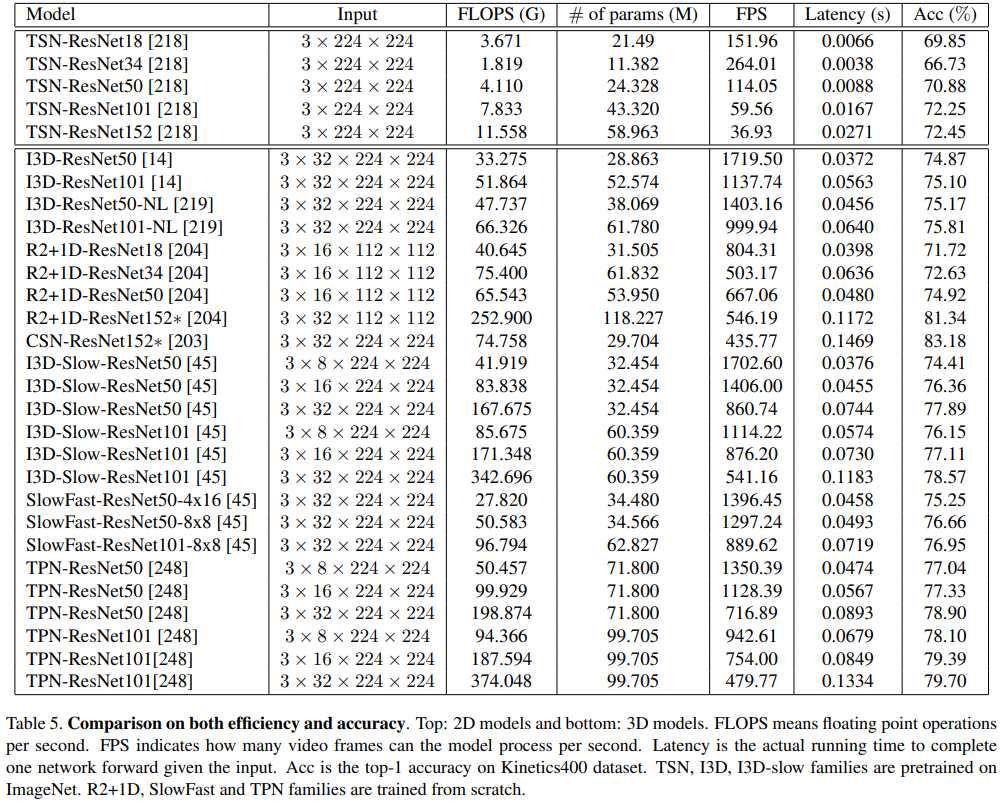
여기서 우리는 GluonCV 비디오 동작 인식 모델 zoo3의 모델을 사용합니다. 이러한 모든 모델은 동일한 데이터, 동일한 data augmentation strategy 및 동일한 30개 보기 평가 체계를 사용하여 훈련되므로 공정한 비교입니다.
Here, we use the models in the GluonCV video action recognition model zoo3 since all these models are trained using the same data, same data augmentation strategy and under same 30-view evaluation scheme, thus fair comparison.
모든 타이밍은 단일 Tesla V100 GPU에서 105회의 반복 실행으로 수행되며 처음 5회의 실행은 워밍업을 위해 무시됩니다.
All the timings are done on a single Tesla V100 GPU with 105 repeated runs, while the first 5 runs are ignored for warming up.
우리는 항상 배치 크기 1을 사용합니다.
We always use a batch size of 1.
모델 입력의 경우 원본 논문에서 제안한 설정을 사용합니다.
In terms of model input, we use the suggested settings in the original paper.
표 5에서 볼 수 있듯이 대기 시간을 비교하면 2D 모델이 다른 모든 3D 모델보다 훨씬 빠릅니다.
As we can see in Table 5, if we compare latency, 2D models are much faster than all other 3D variants.
이것이 아마도 대부분의 실제 비디오 응용 프로그램이 여전히 프레임 단위 방법을 채택하는 이유일 것입니다.
This is probably why most real-world video applications still adopt frame-wise methods.
둘째, [170, 259]에서 언급한 바와 같이 FLOPS는 실제 추론 시간(즉, 대기 시간)과 강한 상관 관계가 없습니다.
Secondly, as mentioned in [170, 259], FLOPS is not strongly correlated with the actual inference time (i.e., latency).
셋째, 성능을 비교해 보면 대부분의 3D 모델이 75% 정도 비슷한 정확도를 보여주지만 더 큰 데이터 세트로 사전 훈련을 하면 성능을 크게 높일 수 있습니다.
Third, if comparing performance, most 3D models give similar accuracy around 75%, but pretraining with a larger dataset can significantly boost the performance.
이는 훈련 데이터의 중요성을 나타내며 부분적으로 자체 감독 사전 훈련이 기존 방법을 더욱 개선할 수 있는 유망한 방법일 수 있음을 시사합니다.
This indicates the importance of training data and partially suggests that self-supervised pre-training might be a promising way to further improve existing methods.
5. Discussion and Future Work
우리는 2014년부터 비디오 동작 인식을 위한 200개 이상의 딥 러닝 기반 방법을 조사했습니다.
We have surveyed more than 200 deep learning based methods for video action recognition since year 2014.
벤치마크 데이터 세트의 성능이 정체되고 있음에도 불구하고 이 작업에는 탐색할 가치가 있는 적극적이고 유망한 방향이 많이 있습니다.
Despite the performance on benchmark datasets plateauing, there are many active and promising directions in this task worth exploring.
5.1. Analysis and insights
비디오 동작 인식을 개선하는 동시에 점점 더 많은 방법이 개발되었습니다.
More and more methods haven been developed to improve video action recognition, at the same time,
이러한 방법을 요약하고 분석 및 통찰력을 제공하는 일부 논문이 있습니다.
there are some papers summarizing these methods and providing analysis and insights.
Huang et al. 비디오 이해를 위한 시간 정보의 효과에 대한 명시적 분석을 수행합니다.
Huang et al. [82] perform an explicit analysis of the effect of temporal information for video understanding.
그들은 “동작을 인식하는 데 비디오의 동작이 얼마나 중요한지”라는 질문에 답하려고 합니다.
They try to answer the question “how important is the motion in the video for recognizing the action”.
Feichtenhofer et al. [48, 49]는 이러한 깊은 표현이 어떻게 작동하고 무엇을 캡처하는지 이해하기 위해 two-stream models이 학습한 놀라운 시각화를 제공합니다.
Feichtenhofer et al. [48, 49] provide an amazing visualization of what two-stream models have learned in order to understand how these deep representations work and what they are capturing.
Li et al. [124] 개념, 데이터 세트의 표현 편향을 소개하고 현재 데이터 세트가 정적 표현으로 편향되어 있음을 발견합니다.
Li et al. [124] introduce a concept, representation bias of a dataset, and find that current datasets are biased towards static representations.
이러한 편향된 데이터 세트에 대한 실험은 잘못된 결론으로 이어질 수 있으며 이는 실제로 비디오 동작 인식의 개발을 제한하는 큰 문제입니다.
Experiments on such biased datasets may lead to erroneous conclusions, which is indeed a big problem that limits the development of video action recognition.
최근 Piergiovanni et al. 다양한 그룹의 사람들로부터 데이터를 수집하여 데이터 편향에 대처하기 위해 AViD [165] 데이터 세트를 도입했습니다.
Recently, Piergiovanni et al. introduced the AViD [165] dataset to cope with data bias by collecting data from diverse groups of people.
이 논문은 동료 연구자들이 당면 과제, 해결되지 않은 문제 및 다음 돌파구를 이해하는 데 도움이 되는 훌륭한 통찰력을 제공합니다.
These papers provide great insights to help fellow researchers to understand the challenges, open problems and where the next breakthrough might reside.
5.2. Data augmentation
mixup[258], cutout[31], CutMix[254], AutoAugment[27], FastAutoAug[126] 등과 같은 이미지 인식 도메인에서 수많은 Data augmentation 방법이 제안되었습니다.
Numerous data augmentation methods have been proposed in image recognition domain, such as mixup [258], cutout [31], CutMix [254], AutoAugment [27], FastAutoAug [126], etc.
그러나 비디오 동작 인식은 여전히 2015년 이전에 도입된 기본 Data augmentation 기술[217, 188]을 채택하고 있습니다. 여기에는 무작위 크기 조정, 무작위 자르기 및 무작위 수평 뒤집기가 포함됩니다.
However, video action recognition still adopts basic data augmentation techniques introduced before year 2015 [217, 188], including random resizing, random cropping and random horizontal flipping.
최근 SimCLR[17]과 다른 논문들은 color jittering과 random rotation이 representation learning에 크게 도움이 된다는 것을 보여주었다. 따라서 비디오 동작 인식을 위해 다양한 Data augmentation 기술을 사용하는 조사가 특히 유용합니다.
Recently, SimCLR [17] and other papers have shown that color jittering and random rotation greatly help representation learning. Hence, an investigation of using different data augmentation techniques for video action recognition is particularly useful.
이것은 기존의 모든 방법에 대한 데이터 사전 처리 파이프라인을 변경할 수 있습니다.
This may change the data pre-processing pipeline for all existing methods.
5.3. Video domain adaptation
도메인 적응(DA)은 도메인 이동 문제를 해결하기 위해 최근 몇 년 동안 광범위하게 연구되었습니다.
Domain adaptation (DA) has been studied extensively in recent years to address the domain shift problem.
표준 데이터 세트에 대한 정확도가 점점 더 높아지고 있음에도 불구하고 데이터 세트 또는 도메인에 걸친 현재 비디오 모델의 일반화 기능은 덜 탐색됩니다.
Despite the accuracy on standard datasets getting higher and higher, the generalization capability of current video models across datasets or domains is less explored.
비디오 도메인 적응에 대한 초기 작업이 있습니다[193, 241, 89, 159].
There is early work on video domain adaptation [193, 241, 89, 159].
그러나 이러한 문헌은 실제 도메인 불일치를 반영하지 않을 수 있고 편향된 결론으로 이어질 수 있는 몇 개의 겹치는 범주만 있는 소규모 비디오 DA에 중점을 둡니다.
However, these literature focus on smallscale video DA with only a few overlapping categories, which may not reflect the actual domain discrepancy and may lead to biased conclusions.
Chenet al. [15] 비디오 DA를 조사하고 시간 역학을 정렬하는 것이 특히 유용하다는 것을 찾기 위해 두 개의 더 큰 규모의 데이터 세트를 소개합니다.
Chen et al. [15] introduce two larger-scale datasets to investigate video DA and find that aligning temporal dynamics is particularly useful.
Pan et al. [152] 시간적 오정렬 문제를 해결하기 위해 co-attention을 채택한다.
Pan et al. [152] adopts co-attention to solve the temporal misalignment problem.
아주 최근에 Munro et al. 세분화된 비디오 동작 인식을 위한 다중 모드 자기 감독 방법을 탐색하고 비디오 DA에서 다중 모드 학습의 효과를 보여줍니다.
Very recently, Munro et al. [145] explore a multi-modal self-supervision method for fine-grained video action recognition and show the effectiveness of multi-modality learning in video DA.
Shuffle and Attend [95]는 모든 클립이 관련 의미 체계를 포함하지 않기 때문에 샘플링된 모든 클립의 기능을 정렬하면 차선책의 솔루션이 된다고 주장합니다.
Shuffle and Attend [95] argues that aligning features of all sampled clips results in a sub-optimal solution due to the fact that all clips do not include relevant semantics.
따라서 그들은 유익한 클립에 더 집중하고 non-informative 클립을 폐기하기 위해 attention mechanism을 사용할 것을 제안합니다.
Therefore, they propose to use an attention mechanism to focus more on informative clips and discard the non-informative ones.
결론적으로 비디오 DA는 특히 컴퓨팅 리소스가 적은 연구자들에게 유망한 방향입니다.
In conclusion, video DA is a promising direction, especially for researchers with less computing resources.
5.4. Neural architecture search
신경망 구조 검색(NAS)은 최근 몇 년 동안 큰 관심을 끌었으며 유망한 연구 방향입니다.
Neural architecture search (NAS) has attracted great interest in recent years and is a promising research direction.
그러나 컴퓨팅 리소스에 대한 greedy need를 감안할 때 이 분야에 대한 논문은 몇 편만 출판되었습니다[156, 163, 161, 178].
However, given its greedy need for computing resources, only a few papers have been published in this area [156, 163, 161, 178].
매개변수와 런타임을 공동으로 최적화하는 TVN 제품군[161]은 인간이 설계한 최신 모델로 경쟁력 있는 정확도를 달성하고 훨씬 더 빠르게 실행할 수 있습니다(1초 비디오 클립당 CPU에서 37~100ms, GPU에서 10ms 이내).
The TVN family [161], which jointly optimize parameters and runtime, can achieve competitive accuracy with human-designed contemporary models, and run much faster (within 37 to 100 ms on a CPU and 10 ms on a GPU per 1 second video clip).
AssembleNet[178] 및 AssembleNet++[177]는 입력 양식 전반에 걸쳐 feature representations 간의 연결성을 학습하는 일반적인 접근 방식을 제공하고 Charades 및 기타 벤치마크에서 놀라울 정도로 우수한 성능을 보여줍니다.
AssembleNet [178] and AssembleNet++ [177] provide a generic approach to learn the connectivity among feature representations across input modalities, and show surprisingly good performance on Charades and other benchmarks.
AttentionNAS [222]는 spatio-temporal attention cell 검색을 위한 솔루션을 제안했습니다.
AttentionNAS [222] proposed a solution for spatio-temporal attention cell search.
발견된 셀은 spatio-temporal features을 개선하기 위해 모든 네트워크에 연결할 수 있습니다.
The found cell can be plugged into any network to improve the spatio-temporal features.
이전의 모든 논문은 비디오 이해에 대한 잠재력을 보여줍니다.
All previous papers do show their potential for video understanding.
최근 DARTS[130], Proxyless NAS[11], ENAS[160], oneshot NAS[7] 등과 같은 이미지 인식 도메인에서 아키텍처를 검색하는 효율적인 방법이 제안되었습니다.
Recently, some efficient ways of searching architectures have been proposed in the image recognition domain, such as DARTS [130], Proxyless NAS [11], ENAS [160], oneshot NAS [7], etc.
효율적인 2D CNN과 효율적인 검색 알고리즘을 결합하여 합리적인 비용으로 비디오 NAS를 수행하는 것이 흥미로울 것입니다.
It would be interesting to combine efficient 2D CNNs and efficient searching algorithms to perform video NAS for a reasonable cost.
5.5. Efficient model development
정확성에도 불구하고 실제 응용 측면에서 비디오 이해 문제에 대한 딥 러닝 기반 방법을 배포하는 것은 어렵습니다.
Despite their accuracy, it is difficult to deploy deep learning based methods for video understanding problems in terms of real-world applications.
몇 가지 주요 과제가 있습니다.
There are several major challenges:
(1) 대부분의 방법은 오프라인 설정에서 개발됩니다. 즉, 입력이 온라인 설정의 비디오 스트림이 아닌 짧은 비디오 클립임을 의미합니다.
(1) most methods are developed in offline settings, which means the input is a short video clip, not a video stream in an online setting;
(2) 대부분의 방법은 실시간 요구 사항을 충족하지 않습니다.
(2) most methods do not meet the real-time requirement;
(3) GPU가 아닌 장치(예: 에지 장치)에서 3D 컨볼루션 또는 기타 비표준 연산자의 비호환성.
(3) incompatibility of 3D convolutions or other non-standard operators on non-GPU devices (e.g., edge devices).
따라서 2D 컨볼루션을 기반으로 한 효율적인 네트워크 아키텍처의 개발이 유망한 방향입니다.
Hence, the development of efficient network architecture based on 2D convolutions is a promising direction.
이미지 분류 도메인에서 제안된 접근 방식은 비디오 동작 인식에 쉽게 적용할 수 있습니다. ( 모델 압축, 모델 양자화, 모델 가지치기, 분산 훈련[68, 127], 모바일 네트워크[80, 265], 혼합 정밀 훈련 등 )
The approaches proposed in the image classification domain can be easily adapted to video action recognition, e.g. model compression, model quantization, model pruning, distributed training [68, 127], mobile networks [80, 265], mixed precision training, etc.
그러나 대부분의 동작 인식 응용 프로그램에 대한 입력은 감시 모니터링과 같은 비디오 스트림이기 때문에 온라인 설정에 더 많은 노력이 필요합니다.
However, more effort is needed for the online setting since the input to most action recognition applications is a video stream, such as surveillance monitoring.
온라인 비디오 동작 인식 방법을 벤치마킹하기 위해 새롭고 보다 포괄적인 데이터 세트가 필요할 수 있습니다.
We may need a new and more comprehensive dataset for benchmarking online video action recognition methods.
마지막으로 대부분의 동영상이 이미 압축되어 있고 모션 정보에 자유롭게 액세스할 수 있으므로 압축된 동영상을 사용하는 것이 바람직할 수 있습니다.
Lastly, using compressed videos might be desirable because most videos are already compressed, and we have free access to motion information.
5.6. New datasets
데이터는 기계 학습을 위한 모델 개발만큼 중요합니다.
Data is more or at least as important as model development for machine learning.
비디오 동작 인식의 경우 대부분의 데이터 세트는 공간 표현[124]에 편향되어 있습니다. 즉, 대부분의 동작은 시간적 움직임을 고려하지 않고 비디오 내부의 단일 프레임으로 인식할 수 있습니다.
For video action recognition, most datasets are biased towards spatial representations [124], i.e., most actions can be recognized by a single frame inside the video without considering the temporal movement.
따라서 비디오 이해를 향상시키기 위해서는 장기 시간 모델링 측면에서 새로운 데이터 세트가 필요합니다.
Hence, a new dataset in terms of long-term temporal modeling is required to advance video understanding.
또한 대부분의 최신 데이터 세트는 YouTube에서 수집됩니다.
Furthermore, most current datasets are collected from YouTube.
저작권/개인정보 보호 문제로 인해 데이터세트 구성자는 실제 동영상이 아닌 사용자가 다운로드할 수 있는 YouTube ID 또는 동영상 링크만 공개하는 경우가 많습니다.
Due to copyright/privacy issues, the dataset organizer often only releases the YouTube id or video link for users to download and not the actual video.
첫 번째 문제는 대규모 데이터 세트를 다운로드하는 것이 일부 지역에서 느릴 수 있다는 것입니다.
The first problem is that downloading the large-scale datasets might be slow for some regions.
특히 유튜브는 최근 단일 IP로부터의 대량 다운로드를 차단하기 시작했다.
In particular, YouTube recently started to block massive downloading from a single IP.
따라서 많은 연구자들이 이 분야에서 작업을 시작하기 위해 데이터 세트를 얻지 못할 수도 있습니다.
Thus, many researchers may not even get the dataset to start working in this field.
두 번째 문제는 지역 제한 및 개인 정보 보호 문제로 인해 일부 동영상에 더 이상 액세스할 수 없다는 것입니다.
The second problem is, due to region limitation and privacy issues, some videos are not accessible anymore.
예를 들어 원래 Kinetcis400 데이터 세트에는 300,000개가 넘는 비디오가 있지만 현재로서는 약 280,000개의 비디오만 크롤링할 수 있습니다.
For example, the original Kinetcis400 dataset has over 300K videos, but at this moment, we can only crawl about 280K videos.
평균적으로 매년 동영상의 5%가 손실됩니다.
On average, we lose 5% of the videos every year.
방법이 서로 다른 데이터에 대해 훈련되고 평가될 때 방법 간에 공정한 비교를 수행하는 것은 불가능합니다.
It is impossible to do fair comparisons between methods when they are trained and evaluated on different data.
5.7. Video adversarial attack
적대적인 예는 이미지 모델에 대해 잘 연구되었습니다.
Adversarial examples have been well studied on image models.
[199]는 먼저 원본 이미지에 소량의 노이즈를 삽입하여 계산된 적대적 샘플이 잘못된 예측으로 이어질 수 있음을 보여줍니다.
[199] first shows that an adversarial sample, computed by inserting a small amount of noise on the original image, may lead to a wrong prediction.
그러나 video models 공격에 대한 작업은 제한적으로 수행되었습니다.
However, limited work has been done on attacking video models.
이 작업은 일반적으로 공격자가 주어진 입력의 정확한 그래디언트를 포함하여 모델에 대한 전체 액세스 권한을 항상 얻을 수 있는 화이트 박스 공격[86, 119, 66, 21] 또는 블랙 박스 공격[93, 245, 226] 공격자가 쿼리를 통해서만 (입력, 출력) 쌍에 액세스할 수 있도록 모델의 구조와 매개 변수가 차단됩니다.
This task usually considers two settings, a white-box attack [86, 119, 66, 21] where the adversary can always get the full access to the model including exact gradients of a given input, or a black-box one [93, 245, 226], in which the structure and parameters of the model are blocked so that the attacker can only access the (input, output) pair through queries.
최근 작업 ME-Sampler [260]는 적대적 비디오를 생성하는 데 직접 모션 정보를 활용하고 훨씬 적은 쿼리를 사용하여 여러 비디오 분류 모델을 성공적으로 공격하는 것으로 나타났습니다.
Recent work ME-Sampler [260] leverages the motion information directly in generating adversarial videos, and is shown to successfully attack a number of video classification models using many fewer queries.
정리하면 영상 분류, 이상 감지, 샷 감지, 얼굴 감지 등과 같은 서비스에 대한 API를 많은 회사에서 제공하기 때문에 이 방향이 유용합니다.
In summary, this direction is useful since many companies provide APIs for services such as video classification, anomaly detection, shot detection, face detection, etc.
또한 이 항목은 DeepFake 비디오 탐지와도 관련이 있습니다.
In addition, this topic is also related to detecting DeepFake videos.
따라서 이러한 비디오 서비스를 안전하게 유지하려면 공격 방법과 방어 방법을 모두 조사하는 것이 중요합니다.
Hence, investigating both attacking and defending methods is crucial to keeping these video services safe.
5.8. Zero-shot action recognition
ZSL(Zero-shot learning)은 이미지 이해 영역에서 유행하고 있으며 최근 비디오 동작 인식에 적용되었습니다.
Zero-shot learning (ZSL) has been trending in the image understanding domain, and has recently been adapted to video action recognition.
그것의 목표는 이전에 볼 수 없었던 범주를 분류하기 위해 학습된 지식을 전송하는 것입니다.
Its goal is to transfer the learned knowledge to classify previously unseen categories.
(1) 값비싼 데이터 소싱 및 주석과 (2) 가능한 인간 행동 세트가 방대하기 때문에 제로 샷 행동 인식은 실제 응용 프로그램에 매우 유용한 작업입니다.
Due to (1) the expensive data sourcing and annotation and (2) the set of possible human actions is huge, zero-shot action recognition is a very useful task for real-world applications.
이 방향으로 많은 초기 시도[242, 88, 243, 137, 168, 57]가 있습니다.
There are many early attempts [242, 88, 243, 137, 168, 57] in this direction.
그들 중 대부분은 사전 훈련된 네트워크를 사용하여 비디오에서 시각적 특징을 먼저 추출한 다음 시각적 임베딩을 시맨틱 임베딩 공간에 매핑하는 공동 모델을 훈련시키는 표준 프레임워크를 따릅니다.
Most of them follow a standard framework, which is to first extract visual features from videos using a pretrained network, and then train a joint model that maps the visual embedding to a semantic embedding space.
이러한 방식으로 임베딩이 모델 출력의 가장 가까운 이웃인 테스트 클래스를 찾아 새 클래스에 모델을 적용할 수 있습니다.
In this manner, the model can be applied to new classes by finding the test class whose embedding is the nearestneighbor of the model’s output.
최근 작업 URL [279]은 데이터 세트 전체에서 일반화하는 보편적인 표현을 학습할 것을 제안합니다.
A recent work URL [279] proposes to learn a universal representation that generalizes across datasets.
다음 URL [279], [10]은 최초의 종단 간 ZSL 동작 인식 모델을 제시합니다.
Following URL [279], [10] present the first end-to-end ZSL action recognition model.
또한 새로운 ZSL 교육 및 평가 프로토콜을 설정하고 이 분야를 더욱 발전시키기 위해 심층 분석을 제공합니다.
They also establish a new ZSL training and evaluation protocol, and provide an in-depth analysis to further advance this field.
NLP 도메인에서 사전 훈련 후 제로 샷의 성공에 영감을 받아 ZSL 동작 인식이 유망한 연구 주제라고 생각합니다.
Inspired by the success of pre-training and then zero-shot in NLP domain, we believe ZSL action recognition is a promising research topic.
5.9. Weakly-supervised video action recognition
고품질 비디오 동작 인식 데이터 세트[190, 100]를 구축하려면 일반적으로 여러 힘든 단계가 필요합니다.
Building a high-quality video action recognition dataset [190, 100] usually requires multiple laborious steps:
1) 먼저 일반적으로 인터넷에서 대량의 원시 비디오를 소싱합니다.
1) first sourcing a large amount of raw videos, typically from the internet;
2) 데이터 세트의 카테고리와 관련 없는 비디오를 제거합니다.
2) removing videos irrelevant to the categories in the dataset;
3) 관심 있는 동작이 있는 비디오 세그먼트를 수동으로 트리밍합니다.
3) manually trimming the video segments that have actions of interest;
4) 범주 레이블을 세분화합니다. Weakly-supervised action recognition은 훈련 데이터 큐레이팅 비용을 줄이는 방법을 탐색합니다.
4) refining the categorical labels. Weakly-supervised action recognition explores how to reduce the cost for curating training data.
연구의 첫 번째 방향[19, 60, 58]은 비디오 소싱 비용과 정확한 범주 라벨링을 줄이는 것을 목표로 합니다.
The first direction of research [19, 60, 58] aims to reduce the cost of sourcing videos and accurate categorical labeling.
그들은 인터넷과 같이 공개적으로 사용 가능한 소스에서 수집된 동작 관련 이미지 또는 부분적으로 주석이 달린 비디오와 같은 교육 데이터를 사용하는 교육 방법을 설계합니다.
They design training methods that use training data such as action-related images or partially annotated videos, gathered from publicly available sources such as Internet.
따라서 이 패러다임은 webly-supervised learning[19, 58]이라고도 합니다.
Thus this paradigm is also referred to as webly-supervised learning [19, 58].
옴니 감독 학습에 대한 최근 작업[60, 64, 38]도 이 패러다임을 따르지만 모델 자체 추론 결과를 추출하여 레이블이 지정되지 않은 비디오에 대한 부트스트래핑을 특징으로 합니다.
Recent work on omni-supervised learning [60, 64, 38] also follows this paradigm but features bootstrapping on unlabelled videos by distilling the models’ own inference results.
두 번째 방향은 애노테이션에서 가장 시간이 많이 걸리는 부분인 트리밍을 제거하는 것을 목표로 합니다. UntrimmedNet[216]은 범주 레이블만 있는 트리밍되지 않은 비디오에 대한 동작 인식 모델을 학습하는 방법을 제안했습니다[149, 172].
The second direction aims at removing trimming, the most time consuming part in annotation. UntrimmedNet [216] proposed a method to learn action recognition model on untrimmed videos with only categorical labels [149, 172].
이 작업은 또한 작업의 시간 범위를 자동으로 생성하는 것을 목표로 하는 약한 감독 시간 작업 지역화와 관련이 있습니다.
This task is also related to weaklysupervised temporal action localization which aims to automatically generate the temporal span of the actions.
몇몇 논문은 이 두 작업에 대한 모델을 동시에 [155] 또는 반복적으로 [184] 학습할 것을 제안합니다.
Several papers propose to simultaneously [155] or iteratively [184] learn models for these two tasks.
5.10. Fine-grained video action recognition
UCF101[190] 또는 Kinetics400[100]과 같은 인기 있는 동작 인식 데이터 세트는 대부분 다양한 장면에서 발생하는 동작으로 구성됩니다.
Popular action recognition datasets, such as UCF101 [190] or Kinetics400 [100], mostly comprise actions happening in various scenes.
그러나 이러한 데이터 세트에서 학습된 모델은 작업과 관련 없는 컨텍스트 정보에 과적합될 수 있습니다[224, 227, 24].
However, models learned on these datasets could overfit to contextual information irrelevant to the actions [224, 227, 24].
세분화된 행동 인식의 문제를 연구하기 위해 여러 데이터 세트가 제안되었으며, 이는 행동 특정 정보를 모델링하는 모델의 능력을 검사할 수 있습니다.
Several datasets have been proposed to study the problem of fine-grained action recognition, which could examine the models’ capacities in modeling action specific information.
이러한 데이터 세트는 요리[28, 108, 174], 작업[103] 및 스포츠[181, 124]와 같은 인간 활동의 세분화된 작업으로 구성됩니다.
These datasets comprise fine-grained actions in human activities such as cooking [28, 108, 174], working [103] and sports [181, 124].
예를 들어, FineGym [181]은 체조 비디오에서 다양한 동작 및 하위 동작으로 주석이 달린 최근 대규모 데이터 세트입니다.
For example, FineGym [181] is a recent large dataset annotated with different moves and sub-actions in gymnastic videos.
5.11. Egocentric action recognition
최근 웨어러블 카메라 장치의 등장으로 대규모 자기 중심적 행동 인식[29, 28]에 대한 관심이 높아지고 있다.
Recently, large-scale egocentric action recognition [29, 28] has attracted increasing interest with the emerging of wearable cameras devices.
자기 중심적 행동 인식은 복잡한 환경에서 손 동작과 상호 작용하는 개체에 대한 정밀한 이해가 필요합니다.
Egocentric action recognition requires a fine understanding of hand motion and the interacting objects in the complex environment.
몇몇 논문은 객체 감지 기능을 활용하여 자기 중심적인 비디오 인식을 개선하기 위해 미세한 객체 컨텍스트를 제공합니다[136, 223, 229, 180].
A few papers leverage object detection features to offer fine object context to improve egocentric video recognition [136, 223, 229, 180].
다른 것들은 동작 인식을 용이하게 하기 위해 상호 작용하는 객체를 위치시키기 위해 시공간 주의[192] 또는 시선 주석[131]을 통합합니다.
Others incorporate spatio-temporal attention [192] or gaze annotations [131] to localize the interacting object to facilitate action recognition.
3인칭 동작 인식과 유사하게 다중 모드 입력(예: optical flow & audio)이 자기 중심적 동작 인식에 효과적인 것으로 입증되었습니다[101].
Similar to third-person action recognition, multi-modal inputs (e.g., optical flow and audio) have been demonstrated to be effective in egocentric action recognition [101].
5.12. Multi-modality
Multi-modal video 이해는 최근 몇 년 동안 주목을 끌었습니다 [55, 3, 129, 167, 154, 2, 105].
Multi-modal video understanding has attracted increasing attention in recent years [55, 3, 129, 167, 154, 2, 105].
다중 모달 비디오 이해에는 두 가지 주요 범주가 있습니다.
There are two main categories for multi-modal video understanding.
첫 번째 접근 방식 그룹은 장면, 개체, 동작 및 오디오와 같은 다중 형식을 사용하여 비디오 표현을 풍부하게 합니다.
The first group of approaches use multimodalities such as scene, object, motion, and audio to enrich the video representations.
두 번째 그룹의 목표는 모달 정보를 사전 학습 모델에 대한 감독 신호로 활용하는 모델을 설계하는 것입니다[195, 138, 249, 62, 2].
In the second group, the goal is to design a model which utilizes modality information as a supervision signal for pre-training models [195, 138, 249, 62, 2].
포괄적인 비디오 이해를 위한 다중 방식 비디오의 의미 체계가 복잡하기 때문에 강력하고 포괄적인 비디오 표현을 학습하는 것은 매우 어렵습니다.
Multi-modality for comprehensive video understanding Learning a robust and comprehensive representation of video is extremely challenging due to the complexity of semantics in videos.
비디오 데이터는 종종 모양, 동작, 오디오, 텍스트 또는 장면을 포함한 다양한 형태의 변형을 포함합니다[55, 129, 166].
Video data often includes variations in different forms including appearance, motion, audio, text or scene [55, 129, 166].
따라서 이러한 다중 모달 표현을 활용하는 것은 비디오 콘텐츠를 보다 효율적으로 이해하는 데 중요한 단계입니다.
Therefore, utilizing these multi-modal representations is a critical step in understanding video content more efficiently.
비디오의 다중 모드 표현은 장면, 개체, 오디오, 동작, 모양 및 텍스트와 같은 다양한 형식의 표현을 수집하여 근사화할 수 있습니다.
The multi-modal representations of video can be approximated by gathering representations of various modalities such as scene, object, audio, motion, appearance and text.
Ngiam et al. [148] 더 나은 기능을 얻기 위해 여러 양식을 사용하도록 제안하려는 초기 시도였습니다.
Ngiam et al. [148] was an early attempt to suggest using multiple modalities to obtain better features.
대부분의 비디오 동작 인식 방식은 원시 비디오(또는 디코딩된 비디오 프레임)를 입력으로 사용합니다.
They utilized videos of lips and their corresponding speech for multi-modal representation learning.
Miechet al. [139]는 모션, 모양, 오디오 및 얼굴 특징을 포함한 여러 양식을 결합하고 이러한 양식과 텍스트 사이의 공유 임베딩 공간을 학습하기 위해 임베딩 전문가 혼합 모델을 제안했습니다.
Miech et al. [139] proposed a mixture-of embedding-experts model to combine multiple modalities including motion, appearance, audio, and face features and learn the shared embedding space between these modalities and text.
Roiget al. [175] 동작 인식을 위한 피라미드 구조에서 동작, 장면, 개체 및 음향 이벤트 기능과 같은 여러 양식을 결합합니다.
Roig et al. [175] combines multiple modalities such as action, scene, object and acoustic event features in a pyramidal structure for action recognition.
각 양식을 추가하면 최종 동작 인식 정확도가 향상됨을 보여줍니다.
They show that adding each modality improves the final action recognition accuracy.
CE[129]와 MMT[55] 모두 [139]와 유사한 연구 라인을 따르며, 목표는 공동 비디오-텍스트 표현 학습을 위한 비디오의 포괄적인 표현을 얻기 위해 다중 양식을 결합하는 것입니다.
Both CE [129] and MMT [55], follow a similar research line to [139] where the goal is to combine multiple-modalities to obtain a comprehensive representation of video for joint video-text representation learning.
Piergiovanni et al. [166] 공동 임베딩 공간을 학습하기 위해 비디오 데이터와 함께 텍스트 데이터를 활용했습니다.
Piergiovanni et al. [166] utilized textual data together with video data to learn a joint embedding space.
이 학습된 관절 임베딩 공간을 사용하여 이 방법은 제로 샷 동작 인식을 수행할 수 있습니다.
Using this learned joint embedding space, the method is capable of doing zero-shot action recognition.
이 연구 라인은 강력한 의미 추출 모델의 가용성과 비전 및 언어 작업 모두에서 변환기의 성공으로 인해 유망합니다.
This line of research is promising due to the availability of strong semantic extraction models and also success of transformers on both vision and language tasks.
자기 감독 비디오 표현 학습을 위한 다중 양식 대부분의 비디오에는 오디오 또는 텍스트/캡션과 같은 다중 양식이 포함되어 있습니다.
Multi-modality for self-supervised video representation learning Most videos contain multiple modalities such as audio or text/caption.
이러한 양식은 비디오 표현 학습을 위한 훌륭한 감독 소스입니다[3, 144, 154, 2, 162].
These modalities are great source of supervision for learning video representations [3, 144, 154, 2, 162].
Korbaret al. [105] 자기 감독 표현 학습을 위한 대조 학습 목표에서 감독 신호로 오디오와 비디오 사이의 자연스러운 동기화를 통합했습니다. 다중 모드 자기 지도 학습에서 데이터 세트는 중요한 역할을 합니다.
Korbar et al. [105] incorporated the natural synchronization between audio and video as a supervision signal in their contrastive learning objective for selfsupervised representation learning. In multi-modal selfsupervised representation learning, the dataset plays an important role.
VideoBERT [195]는 YouTube에서 310,000개의 요리 동영상을 수집했습니다.
VideoBERT [195] collected 310K cooking videos from YouTube.
그러나 이 데이터 세트는 공개적으로 사용할 수 없습니다.
However, this dataset is not publicly available.
BERT와 유사하게 VideoBERT는 “마스킹된 언어 모델” 교육 목표를 사용했으며 시각적 표현을 “시각적 단어”로 양자화했습니다.
Similar to BERT, VideoBERT used a “masked language model” training objective and also quantized the visual representations into “visual words”.
Miechet al. [140]은 2019년에 HowTo100M 데이터 세트를 도입했습니다.
Miech et al. [140] introduced HowTo100M dataset in 2019.
이 데이터 세트에는 해당 텍스트가 있는 122만 개의 비디오에서 1억 3600만 개의 클립이 포함되어 있습니다.
This dataset includes 136M clips from 1.22M videos with their corresponding text.
교육용 비디오(활동 수행 방법)를 얻기 위해 YouTube에서 데이터 세트를 수집했습니다.
They collected the dataset from YouTube with the aim of obtaining instructional videos (how to perform an activity).
전체적으로 23.6K 교육 작업을 다룹니다.
In total, it covers 23.6K instructional tasks.
MIL-NCE[138]는 이 데이터 세트를 자기 감독 교차 모달 표현 학습에 사용했습니다.
MIL-NCE [138] used this dataset for self-supervised cross-modal representation learning.
그들은 대조 학습 목표에서 여러 긍정적인 쌍을 고려하여 시각적으로 잘못 정렬된 내레이션 문제를 해결했습니다.
They tackled the problem of visually misaligned narrations, by considering multiple positive pairs in the contrastive learning objective.
ActBERT [275]는 자체 감독 방식으로 모델의 사전 훈련을 위해 HowTo100M 데이터 세트를 활용했습니다.
ActBERT [275], utilized HowTo100M dataset for pre-training of the model in a self-supervised way.
교차 모달 표현 학습을 위해 시각적, 동작, 텍스트 및 개체 기능을 통합했습니다.
They incorporated visual, action, text and object features for cross modal representation learning.
최근 AVLnet [176] 및 MMV [2]는 자기 지도 학습을 위한 시각, 오디오 및 언어의 세 가지 양식을 고려했습니다.
Recently AVLnet [176] and MMV [2] considered three modalities visual, audio and language for self-supervised representation learning.
이 연구 방향은 또한 많은 비전 및 언어 작업에 대한 대조 학습의 성공과 YouTube, Instagram 또는 Flickr와 같은 플랫폼에서 레이블이 지정되지 않은 다중 모드 비디오 데이터에 대한 액세스로 인해 점점 더 많은 관심을 받고 있습니다.
This research direction is also increasingly getting more attention due to the success of contrastive learning on many vision and language tasks and the access to the abundance of unlabeled multimodal video data on platforms such as YouTube, Instagram or Flickr.
표 6의 상단 섹션은 다중 모드 자기 감독 표현 학습 방법을 비교합니다.
The top section of Table 6 compares multi-modal self-supervised representation learning methods.
다음 섹션에서 비디오 전용 표현 학습에 대한 더 많은 작업에 대해 논의할 것입니다.
We will discuss more work on video-only representation learning in the next section.
5.13. Self-supervised video representation learning
Self-supervised learning은 데이터 자체에서 free supervisory signals를 얻기 위해 구실 작업을 설계하여 레이블이 지정되지 않은 대량의 데이터를 활용할 수 있기 때문에 최근 더 많은 관심을 받고 있습니다.
Self-supervised learning has attracted more attention recently as it is able to leverage a large amount of unlabeled data by designing a pretext task to obtain free supervisory signals from data itself.
image representation learning에서 처음 등장했습니다.
It first emerged in image representation learning.
이미지에서 첫 번째 논문은 image coloring[262] 및 image reordering[153, 61, 263]과 같이 누락된 정보를 완성하기 위한 구실 작업을 설계하는 것을 목표로 했습니다.
On images, the first stream of papers aimed at designing pretext tasks for completing missing information, such as image coloring [262] and image reordering [153, 61, 263].
논문의 두 번째 흐름은 감독을 위한 pretext task 및 contrastive losses[235, 151]로 instance discrimination[235]을 사용합니다.
The second stream of papers uses instance discrimination [235] as the pretext task and contrastive losses [235, 151] for supervision.
클래스 레이블이 없는 개체 인스턴스의 시각적 유사성을 모델링하여 시각적 표현을 학습합니다[235, 75, 201, 18, 17].
They learn visual representation by modeling visual similarity of object instances without class labels [235, 75, 201, 18, 17].
Self-supervised learning은 비디오에서도 실행 가능합니다.
Self-supervised learning is also viable for videos.
이미지와 비교하여 비디오는 구실 작업을 만드는 데 사용할 수 있는 또 다른 축인 시간적 차원을 가지고 있습니다.
Compared with images, videos has another axis, temporal dimension, which we can use to craft pretext tasks.
이를 위한 정보 완성 작업에는 셔플된 프레임[141, 52]과 비디오 클립[240]의 올바른 순서를 예측하는 것이 포함됩니다.
Information completion tasks for this purpose include predicting the correct order of shuffled frames [141, 52] and video clips [240].
Jing et al. [94] 회전된 비디오 클립의 회전 각도를 예측하여 공간적 차원에만 집중합니다.
Jing et al. [94] focus on the spatial dimension only by predicting the rotation angles of rotated video clips.
시간 및 공간 정보를 결합하여 시공간 큐빅 퍼즐을 풀고 미래 프레임을 예측하고 [208] 장기 동작을 예측하고 [134] 동작 및 모양 통계를 예측하기 위해 여러 작업이 도입되었습니다 [211].
Combining temporal and spatial information, several tasks have been introduced to solve a space-time cubic puzzle, anticipate future frames [208], forecast long-term motions [134] and predict motion and appearance statistics [211].
RSPNet[16]과 시각적 템포[247]는 감독 신호로 비디오 클립 간의 상대 속도를 이용합니다.
RSPNet [16] and visual tempo [247] exploit the relative speed between video clips as a supervision signal.
추가된 시간 축은 또한 인스턴스 차별 구실을 설계하는 데 유연성을 제공할 수 있습니다[67, 167].
The added temporal axis can also provide flexibility in designing instance discrimination pretexts [67, 167].
3D 컨볼루션을 공간 및 시간 분리 가능한 컨볼루션으로 분리하는 데 영감을 받아 [239], Zhang et al. 비디오 표현 학습을 공간 대비와 시간 대비의 두 가지 하위 작업으로 분리하도록 제안되었습니다.
Inspired by the decoupling of 3D convolution to spatial and temporal separable convolutions [239], Zhang et al. [266] proposed to decouple the video representation learning into two sub-tasks: spatial contrast and temporal contrast.
최근 Han et al. [72] self-supervised video representation learning을 위한 memory Augmented dense Predictive Coding을 제안했다.
Recently, Han et al. [72] proposed memory augmented dense predictive coding for self-supervised video representation learning.
그들은 각 비디오를 여러 블록으로 분할하고 미래 블록의 임베딩은 메모리에 압축된 표현의 조합에 의해 예측됩니다.
They split each video into several blocks and the embedding of future block is predicted by the combination of condensed representations in memory.
비디오의 시간적 연속성은 연구자들이 서신에 대한 다른 구실 작업을 설계하도록 영감을 줍니다.
The temporal continuity in videos inspires researchers to design other pretext tasks around correspondence.
Wang et al. [221] 주기 일관성 추적을 수행하여 표현을 학습하는 방법을 제안했습니다.
Wang et al. [221] proposed to learn representation by performing cycle-consistency tracking.
특히 연속 비디오 프레임에서 동일한 객체를 뒤로 추적한 다음 앞으로 추적하고 시작점과 끝점 사이의 불일치를 손실 함수로 사용합니다.
Specifically, they track the same object backward and then forward in the consecutive video frames, and use the inconsistency between the start and end points as the loss function.
TCC [39]는 동시 논문입니다.
TCC [39] is a concurrent paper.
로컬 객체를 추적하는 대신 [39]는 주기 일관성을 사용하여 감독 신호로 프레임별 시간 정렬을 수행했습니다. [120]은 [221]의 후속 작업으로 비디오 프레임 전체에서 개체 수준 및 픽셀 수준 대응을 모두 활용했습니다.
Instead of tracking local objects, [39] used cycle-consistency to perform frame-wise temporal alignment as a supervision signal. [120] was a follow-up work of [221], and utilized both object-level and pixel-level correspondence across video frames.
최근에는 [87]에서 비디오 표현 학습을 돕기 위해 장거리 시간 대응을 랜덤 워크 그래프로 모델링했습니다.
Recently, long-range temporal correspondence is modelled as a random walk graph to help learning video representation in [87].
표 6의 하단 섹션에서 비디오 자기 감독 표현 학습 방법을 비교합니다.
We compare video self-supervised representation learning methods at the bottom section of Table 6.
최근 논문이 supervised pre-training에 비해 훨씬 더 나은 선형 평가 정확도와 미세 조정 정확도를 달성했다는 분명한 추세를 관찰할 수 있습니다.
A clear trend can be observed that recent papers have achieved much better linear evaluation accuracy and fine-tuning accuracy comparable to supervised pre-training.
이는 self-supervised learning이 더 나은 비디오 표현 학습을 향한 유망한 방향이 될 수 있음을 보여줍니다.
This shows that self-supervised learning could be a promising direction towards learning better video representations.
6. Conclusion
이 조사에서는 비디오 동작 인식에 대한 최근 접근 방식을 기반으로 하는 200개 이상의 딥 러닝에 대한 포괄적인 리뷰를 제공합니다.
In this survey, we present a comprehensive review of 200+ deep learning based recent approaches to video action recognition.
이것이 완전한 목록은 아니지만 설문조사가 이 분야에 진출하려는 사람들에게는 따라하기 쉬운 지침서가 되고 새로운 연구 방향을 찾으려는 사람들에게는 고무적인 토론이 되기를 바랍니다.
Although this is not an exhaustive list, we hope the survey serves as an easy-to-follow tutorial for those seeking to enter the field, and an inspiring discussion for those seeking to find new research directions.