Dog & Cat Classification Exercise #00
CNN Exercise #00 - 개와 고양이 사진 분류하기
- 이 예제는 케라스 창시자에게 배우는 딥러닝의 Base Code를 가져왔습니다.
- Keras & Tensorflow를 이용하여 Conv. Net을 구성하고
- 이를 이용하여 개와 고양이 사진을 분류하는 Model Train을 실시합니다.
- 이 예제에 사용된 개와 고양이 사진은 Kaggle에서 2012년에 열린 Competition에서 가져왔습니다.(https://www.kaggle.com/c/dogs-vs-cats/data)
- 당시 Competition의 우승자는 CNN을 이용하였고, 95% 정도의 정확도를 가졌습니다..
- 이 예제의 특징은 Dataset의 크기가 CNN을 사용하기에는 적다는 점입니다.(개와 고양이 사진이 각각 2000장)
-
그러나, 다양한 기법들을 통해 Model의 정확도를 차츰 향상시켜 보도록 하겠습니다.
- 여기에서 사용된 Data Set과 Code는 아래 Link에서 Download 할 수 있습니다.
- https://github.com/MoonLight314/Dog_And_Cat
0. Package Load
- 우선 사용할 Package를 Load하도록 하겠습니다.
- 여기서는 Keras / Tensorflow를 사용하도록 하겠습니다.
- Keras를 설치하면 Tensorflow도 자신의 System에 맞도록 CPU or GPU를 자동으로 선택해서 설치됩니다.
- Keras 참 편리하네요~!
import keras
keras.__version__
import os
Using TensorFlow backend.
1. 미리 준비한 Train / Val. Data 확인
- Train / Test / Val. Data 구조는 아래와 같이 구성하였습니다.
train_cats_dir = './dataset/train/cats'
train_dogs_dir = './dataset/train/dogs'
validation_cats_dir = './dataset/validation/cats'
validation_dogs_dir = './dataset/validation/dogs'
test_cats_dir = './dataset/test/cats'
test_dogs_dir = './dataset/test/dogs'
- 각 Folder에 있는 Dataset의 갯수는 아래와 같습니다.
print('훈련용 고양이 이미지 전체 개수:', len(os.listdir(train_cats_dir)))
print('훈련용 강아지 이미지 전체 개수:', len(os.listdir(train_dogs_dir)))
print('검증용 고양이 이미지 전체 개수:', len(os.listdir(validation_cats_dir)))
print('검증용 강아지 이미지 전체 개수:', len(os.listdir(validation_dogs_dir)))
print('테스트용 고양이 이미지 전체 개수:', len(os.listdir(test_cats_dir)))
print('테스트용 강아지 이미지 전체 개수:', len(os.listdir(test_dogs_dir)))
훈련용 고양이 이미지 전체 개수: 1000
훈련용 강아지 이미지 전체 개수: 1000
검증용 고양이 이미지 전체 개수: 500
검증용 강아지 이미지 전체 개수: 500
테스트용 고양이 이미지 전체 개수: 500
테스트용 강아지 이미지 전체 개수: 500
이제 2,000개의 훈련 이미지, 1,000개의 검증 이미지, 1,000개의 테스트 이미지가 준비되었습니다.
분할된 각 데이터는 클래마다 동일한 개수의 샘플을 포함되어 있으므로.
균형잡힌 이진 분류 문제이므로 정확도를 사용해 Model Eval.을 하도록 하겠다.
2. Model 구성
- 이 Exercise에서는 Pre-Trained Model을 사용하지 않고, Simple Conv. Net을 구성해 보도록 합시다.
- ‘Conv2D
(relu활성화 함수 사용)와MaxPooling2D` 층을 번갈아 쌓은 Model 구성합니다. - Conv. Net 입력은 임의로 150 x 150로 정했습니다.
- Feature Map은 Net이 깊어질수록 커지는 것은 일반적이고 전형적인 Pattern입니다.
- 마지막엔 FC(Fully Connected) Layer와 Sigmoid 활성화 함수를 사용하여 마무리하도록 한다.
-
Softmax를 사용하지 않고, Sigmoid 활성화 함수를 사용하는 이유는 이 Exercise가 Binary Classificiation(Dog & Cat)이기 때문입니다.
- Conv2D & MaxPooling2D의 좀 더 구체적인 Description을 참고하도록 하세요.
- Conv2D : https://keras.io/layers/convolutional/
- MaxPooling2D : https://keras.io/layers/pooling/#maxpooling2d
from keras import layers
from keras import models
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
WARNING:tensorflow:From C:\Users\Moon\Anaconda3\lib\site-packages\keras\backend\tensorflow_backend.py:74: The name tf.get_default_graph is deprecated. Please use tf.compat.v1.get_default_graph instead.
WARNING:tensorflow:From C:\Users\Moon\Anaconda3\lib\site-packages\keras\backend\tensorflow_backend.py:517: The name tf.placeholder is deprecated. Please use tf.compat.v1.placeholder instead.
WARNING:tensorflow:From C:\Users\Moon\Anaconda3\lib\site-packages\keras\backend\tensorflow_backend.py:4138: The name tf.random_uniform is deprecated. Please use tf.random.uniform instead.
WARNING:tensorflow:From C:\Users\Moon\Anaconda3\lib\site-packages\keras\backend\tensorflow_backend.py:3976: The name tf.nn.max_pool is deprecated. Please use tf.nn.max_pool2d instead.
- 우리가 구성한 Conv. Net.의 형태는 아래와 같습니다.
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 148, 148, 32) 896
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 74, 74, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 72, 72, 64) 18496
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 36, 36, 64) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 34, 34, 128) 73856
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 17, 17, 128) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 15, 15, 128) 147584
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 7, 7, 128) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 6272) 0
_________________________________________________________________
dense_1 (Dense) (None, 512) 3211776
_________________________________________________________________
dense_2 (Dense) (None, 1) 513
=================================================================
Total params: 3,453,121
Trainable params: 3,453,121
Non-trainable params: 0
_________________________________________________________________
- 우리가 구성한 Model을 Compile하도록 합시다.
- Compile 시에는 이 Model에서 사용할 Loss Function , Optimizer , Learning Rate , Eval. Metrics를 지정해 주어야 합니다.
- Optimizer는
RMSprop를 사용 -
네트워크의 마지막이 하나의 시그모이드 유닛이기 때문에 이진 크로스엔트로피(binary crossentropy)를 손실로 사용합니다
- Keras의 Compile / Optimizer / Loss functions / Eval. Metrics에 관련된 자세한 사항은 아래 Link를 참고하도록 하세요.
- Compile : https://keras.io/models/model/#compile
- Optimizer : https://keras.io/optimizers/
- Loss functions : https://keras.io/losses/
- Metrics : https://keras.io/metrics/
from keras import optimizers
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])
WARNING:tensorflow:From C:\Users\Moon\Anaconda3\lib\site-packages\keras\optimizers.py:790: The name tf.train.Optimizer is deprecated. Please use tf.compat.v1.train.Optimizer instead.
WARNING:tensorflow:From C:\Users\Moon\Anaconda3\lib\site-packages\keras\backend\tensorflow_backend.py:3376: The name tf.log is deprecated. Please use tf.math.log instead.
WARNING:tensorflow:From C:\Users\Moon\Anaconda3\lib\site-packages\tensorflow\python\ops\nn_impl.py:180: add_dispatch_support.<locals>.wrapper (from tensorflow.python.ops.array_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.where in 2.0, which has the same broadcast rule as np.where
3. Data Pre-Processing
- Model은 준비가 되었고, Train에 사용될 Data를 준비해야 합니다.
- Tensorflow에 입력되는 Data는 형태는 반드시 Tensor(실수 행렬)이어야 합니다.
- Image , Word 등등은 어떠한 방식으로든 Tensor(실수 행렬) 형태로 변형이 되어야 Train 할 수 있습니다.
- 우리가 입력하는 Data는 JPG의 그림파일이므로 Net에 넣어서 Train 시키기 전에 반드시 적절한 전처리를 해주어야 합니다.
- 다음의 과정으로 처리합니다.
- Image File Load
- JPEG 콘텐츠를 RGB 픽셀 값으로 디코딩
- 그다음 부동 소수 타입의 텐서로 변환
- 픽셀 값(0에서 255 사이)의 스케일을 [0, 1] 사이로 조정
- 좀 귀찮아 보이지만, Keras는 이를 처리해 주는 Util.을 제공해줍니다.( keras.preprocessing.image )
-
특히
ImageDataGenerator클래스는 디스크에 있는 이미지 파일을 전처리된 배치 텐서로 자동으로 바꾸어주는 제너레이터를 만들어줍니다. - ImageDataGenerator의 flow_from_directory()는 매우 유용한 기능을 제공해 줍니다.
- flow_from_directory : https://keras.io/preprocessing/image/#flow_from_directory
train_dir = './dataset/train'
validation_dir = './dataset/validation'
from keras.preprocessing.image import ImageDataGenerator
# 모든 이미지를 1/255로 스케일을 조정합니다
train_datagen = ImageDataGenerator(rescale=1./255)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
# 타깃 디렉터리
train_dir,
# 모든 이미지를 150 × 150 크기로 바꿉니다
target_size=(150, 150),
batch_size=20,
# binary_crossentropy 손실을 사용하기 때문에 이진 레이블이 필요합니다
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
Found 2000 images belonging to 2 classes.
Found 1000 images belonging to 2 classes.
- ImageDataGenerator가 생성해 주는 Tensor의 형태는 (20, 150, 150, 3)
- 150 x 150 , RGB Channel을 가진 Image를 Batch Size(20)만큼 생성해서 Net에 주입시켜 줍니다.
- ImageDataGenerator는 이 생성 동작을 무한정 반복하므로 적절히 종료하여야 합니다.
for data_batch, labels_batch in train_generator:
print('배치 데이터 크기:', data_batch.shape)
print('배치 레이블 크기:', labels_batch.shape)
break
배치 데이터 크기: (20, 150, 150, 3)
배치 레이블 크기: (20,)
4. Train
- 이제 Model / Train Data 모두 준비되었으니, Model을 Train 시켜 보도록 하겠습니다.
- fit_generator 메서드는 fit 메서드와 동일하되 Data Generator를 사용할 수 있다는 특징이 있습니다.
- Generator는 Data를 끝없이 생성하기 때문에 모델에 하나의 에포크를 정의하기 위해 제너레이터로부터 얼마나 많은 샘플을 뽑을 것인지 알려 주어야 합니다.
- steps_per_epoch개의 Batch만큼 뽑은 다음, 즉 steps_per_epoch 횟수만큼 경사 하강법 단계를 실행한 다음에 훈련 프로세스는 다음 Epoch로 넘어갑니다.
- 여기서는 20개의 샘플이 하나의 Batch이므로 2,000개의 샘플을 모두 처리할 때까지 100개의 배치를 뽑을 것입니다.
- fit_generator를 사용할 때 fit과 마찬가지로 validation_data 매개변수를 전달 가능합니다.
-
Validation Data Generator에서 얼마나 많은 Batch를 추출하여 평가할지 validation_steps 매개변수에 지정해 주면 됩니다.
- fit_generator의 자세한 사항은 아래 Link를 참고하시기 바랍니다.
- fit_generator : https://keras.io/models/model/#fit_generator
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=30,
validation_data=validation_generator,
validation_steps=50)
WARNING:tensorflow:From C:\Users\Moon\Anaconda3\lib\site-packages\keras\backend\tensorflow_backend.py:986: The name tf.assign_add is deprecated. Please use tf.compat.v1.assign_add instead.
Epoch 1/30
100/100 [==============================] - 8s 79ms/step - loss: 0.6917 - acc: 0.5315 - val_loss: 0.6824 - val_acc: 0.5070
Epoch 2/30
100/100 [==============================] - 5s 48ms/step - loss: 0.6606 - acc: 0.5985 - val_loss: 0.6621 - val_acc: 0.5840
Epoch 3/30
100/100 [==============================] - 5s 48ms/step - loss: 0.6213 - acc: 0.6575 - val_loss: 0.6385 - val_acc: 0.6320
Epoch 4/30
100/100 [==============================] - 5s 48ms/step - loss: 0.5803 - acc: 0.7005 - val_loss: 0.6596 - val_acc: 0.6070
Epoch 5/30
100/100 [==============================] - 5s 48ms/step - loss: 0.5336 - acc: 0.7240 - val_loss: 0.5764 - val_acc: 0.7050
Epoch 6/30
100/100 [==============================] - 5s 48ms/step - loss: 0.5138 - acc: 0.7500 - val_loss: 0.5908 - val_acc: 0.6810
Epoch 7/30
100/100 [==============================] - 5s 48ms/step - loss: 0.4759 - acc: 0.7750 - val_loss: 0.6088 - val_acc: 0.6620
Epoch 8/30
100/100 [==============================] - 5s 48ms/step - loss: 0.4522 - acc: 0.7835 - val_loss: 0.5369 - val_acc: 0.7340
Epoch 9/30
100/100 [==============================] - 5s 49ms/step - loss: 0.4232 - acc: 0.8045 - val_loss: 0.5609 - val_acc: 0.7290
Epoch 10/30
100/100 [==============================] - 5s 49ms/step - loss: 0.3887 - acc: 0.8245 - val_loss: 0.5532 - val_acc: 0.7260
Epoch 11/30
100/100 [==============================] - 5s 48ms/step - loss: 0.3703 - acc: 0.8330 - val_loss: 0.5729 - val_acc: 0.7170
Epoch 12/30
100/100 [==============================] - 5s 48ms/step - loss: 0.3414 - acc: 0.8495 - val_loss: 0.5696 - val_acc: 0.7140
Epoch 13/30
100/100 [==============================] - 5s 48ms/step - loss: 0.3200 - acc: 0.8625 - val_loss: 0.5630 - val_acc: 0.7330
Epoch 14/30
100/100 [==============================] - 5s 49ms/step - loss: 0.3002 - acc: 0.8835 - val_loss: 0.5941 - val_acc: 0.7250
Epoch 15/30
100/100 [==============================] - 5s 50ms/step - loss: 0.2785 - acc: 0.8910 - val_loss: 0.5784 - val_acc: 0.7410
Epoch 16/30
100/100 [==============================] - 5s 48ms/step - loss: 0.2534 - acc: 0.8995 - val_loss: 0.5988 - val_acc: 0.7420
Epoch 17/30
100/100 [==============================] - 5s 48ms/step - loss: 0.2295 - acc: 0.9125 - val_loss: 0.6494 - val_acc: 0.7380
Epoch 18/30
100/100 [==============================] - 5s 48ms/step - loss: 0.2156 - acc: 0.9165 - val_loss: 0.6357 - val_acc: 0.7290
Epoch 19/30
100/100 [==============================] - 5s 48ms/step - loss: 0.1905 - acc: 0.9245 - val_loss: 0.6899 - val_acc: 0.7310
Epoch 20/30
100/100 [==============================] - 5s 48ms/step - loss: 0.1654 - acc: 0.9445 - val_loss: 0.6784 - val_acc: 0.7470
Epoch 21/30
100/100 [==============================] - 5s 48ms/step - loss: 0.1503 - acc: 0.9490 - val_loss: 0.7378 - val_acc: 0.7130
Epoch 22/30
100/100 [==============================] - 5s 48ms/step - loss: 0.1398 - acc: 0.9530 - val_loss: 0.6706 - val_acc: 0.7330
Epoch 23/30
100/100 [==============================] - 5s 48ms/step - loss: 0.1150 - acc: 0.9640 - val_loss: 0.8101 - val_acc: 0.7170
Epoch 24/30
100/100 [==============================] - 5s 48ms/step - loss: 0.1015 - acc: 0.9690 - val_loss: 0.8391 - val_acc: 0.7260
Epoch 25/30
100/100 [==============================] - 5s 48ms/step - loss: 0.0858 - acc: 0.9730 - val_loss: 0.8568 - val_acc: 0.7320
Epoch 26/30
100/100 [==============================] - 5s 48ms/step - loss: 0.0751 - acc: 0.9755 - val_loss: 0.8754 - val_acc: 0.7290
Epoch 27/30
100/100 [==============================] - 5s 48ms/step - loss: 0.0615 - acc: 0.9815 - val_loss: 0.9898 - val_acc: 0.7180
Epoch 28/30
100/100 [==============================] - 5s 48ms/step - loss: 0.0578 - acc: 0.9860 - val_loss: 0.9079 - val_acc: 0.7160
Epoch 29/30
100/100 [==============================] - 5s 48ms/step - loss: 0.0474 - acc: 0.9880 - val_loss: 0.9638 - val_acc: 0.7210
Epoch 30/30
100/100 [==============================] - 5s 48ms/step - loss: 0.0398 - acc: 0.9895 - val_loss: 1.0830 - val_acc: 0.7200
5. Train Model Save
- 학습을 마친 Model은 저장해 두도록 하겠습니다.
model.save('cats_and_dogs_small_1.h5')
6. Result Graph
- Train이 끝났으니, 각 Epoch마다 결과를 그래프로 그려보도록 하겠습니다.
- fit_generator는 매 Epoch마다 결과치를 저장해 놓고 있습니다.
- 이를 이용하여 Train 동안의 Model의 성능을 그래프트로 볼 수 있습니다.
import matplotlib.pyplot as plt
history.history.keys()
dict_keys(['val_loss', 'val_acc', 'loss', 'acc'])
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
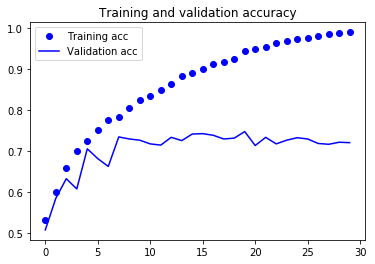
- Training Accuracy가 시간이 지남에 따라 선형적으로 증가해서 거의 100%에 도달합니다.
- 반면 Validation Accuracy는 70-72%에서 멈추었네요.
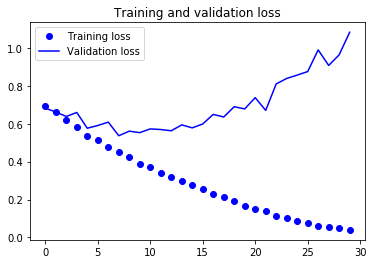
- Validation Loss은 다섯 번의 Epoch만에 최소값에 다다른 이후에 더 이상 진전되지 않고 있습니다.
- 반면 Training Loss은 거의 0에 도달할 때까지 선형적으로 계속 감소합니다.
- 이 그래프는 Overfitting(과대적합)의 특성을 보여줍니다.
- 비교적 훈련 샘플의 수(2,000개)가 적기 때문에 과대적합이 가장 중요한 문제입니다.
-
Dropout이나 가중치 감소(L2 규제)와 같은 Overfitting을 감소시킬 수 있는 여러 가지 기법들 시도 가능합니다.
- 여기서는 Deep Learning으로 이미지를 다룰 때 매우 일반적으로 사용되는 방법인 데이터 증식(Data Augmentation)을 시도해보도록 하겠습니다.
7. Applying Data Augmentation
- Data Augmentation에 대한 설명은 아래 Link에 비교적 자세히 설명되어 있습니다.
- https://nanonets.com/blog/data-augmentation-how-to-use-deep-learning-when-you-have-limited-data-part-2/
- 적은 수의 Image Sample들에 의도적인 변형을 가해서 Sample 수를 늘리는 방법입니다.
- Image에 변형을 가하는 방법들은 아래와 같은 것들이 있습니다.
- Flip
- Rotation
- Scale
- Crop
- Translation
- Gaussian Noise
- 고맙게도 ImageDataGenerator에는 이미 이를 위한 기능이 구현되어 있습니다 !
- 진짜 ImageDataGenerator 좀 짱인듯 !
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
각 Parameter의 의미를 살펴보겠습니다.
rotation_range는 Random하게 사진을 회전시킬 각도 범위(0-180 사이).width_shift_range와height_shift_range는 사진을 수평과 수직으로 랜덤하게 평행 이동시킬 범위(전체 넓이와 높이에 대한 비율).shear_range는 랜덤하게 전단 변환을 적용할 각도 범위.zoom_range는 랜덤하게 사진을 확대할 범위.horizontal_flip은 랜덤하게 이미지를 수평으로 뒤집는다. 수평 대칭을 가정할 수 있을 때 사용(예를 들어, 풍경/인물 사진).fill_mode는 회전이나 가로/세로 이동으로 인해 새롭게 생성해야 할 픽셀을 채울 방법.
# 이미지 전처리 유틸리티 모듈
from keras.preprocessing import image
fnames = sorted([os.path.join(train_cats_dir, fname) for fname in os.listdir(train_cats_dir)])
# 증식할 이미지 선택합니다
img_path = fnames[3]
# 이미지를 읽고 크기를 변경합니다
img = image.load_img(img_path, target_size=(150, 150))
# (150, 150, 3) 크기의 넘파이 배열로 변환합니다
x = image.img_to_array(img)
# (1, 150, 150, 3) 크기로 변환합니다
x = x.reshape((1,) + x.shape)
# flow() 메서드는 랜덤하게 변환된 이미지의 배치를 생성합니다.
# 무한 반복되기 때문에 어느 지점에서 중지해야 합니다!
i = 0
for batch in datagen.flow(x, batch_size=1):
plt.figure(i)
imgplot = plt.imshow(image.array_to_img(batch[0]))
i += 1
if i % 4 == 0:
break
plt.show()




- Data Augmentation은 기존 Sample들을 조금씩 변형을 하기 때문에 기존 Sample들과 완전히 다른 Sample을 만드는 것이 아님을 명심해야 합니다.
- 이런 이유로, Training Sample들 사이에 연관성이 클 수 밖에 없습니다.
- Overfitting을 막기 위해서 Data Augmentation에 추가적으로 Dropout도 추가하겠습니다.
8. New Model with Dropout
-
앞서 만든 Model에 Dropout도 추가하도록 하겠습니다.
-
Dropout의 자세한 사항은 아래 Link를 참고해 주시기 바랍니다.
- https://keras.io/layers/core/#dropout
- http://www.jmlr.org/papers/volume15/srivastava14a/srivastava14a.pdf
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5))
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])
WARNING:tensorflow:From C:\Users\Moon\Anaconda3\lib\site-packages\keras\backend\tensorflow_backend.py:3445: calling dropout (from tensorflow.python.ops.nn_ops) with keep_prob is deprecated and will be removed in a future version.
Instructions for updating:
Please use `rate` instead of `keep_prob`. Rate should be set to `rate = 1 - keep_prob`.
9. Training with Data Augumentation & Dropout
- 이제 Dropout과 Data Augumentation을 적용해서 다시 Train 시키도록 하겠습니다.
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,)
# 검증 데이터는 증식되어서는 안 됩니다!
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
# 타깃 디렉터리
train_dir,
# 모든 이미지를 150 × 150 크기로 바꿉니다
target_size=(150, 150),
batch_size=32,
# binary_crossentropy 손실을 사용하기 때문에 이진 레이블을 만들어야 합니다
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=32,
class_mode='binary')
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=100,
validation_data=validation_generator,
validation_steps=50)
Found 2000 images belonging to 2 classes.
Found 1000 images belonging to 2 classes.
Epoch 1/100
100/100 [==============================] - 18s 181ms/step - loss: 0.6934 - acc: 0.5131 - val_loss: 0.6775 - val_acc: 0.6047
Epoch 2/100
100/100 [==============================] - 16s 162ms/step - loss: 0.6783 - acc: 0.5700 - val_loss: 0.7184 - val_acc: 0.5039
Epoch 3/100
100/100 [==============================] - 16s 163ms/step - loss: 0.6689 - acc: 0.5766 - val_loss: 0.6352 - val_acc: 0.6345
Epoch 4/100
100/100 [==============================] - 16s 163ms/step - loss: 0.6433 - acc: 0.6212 - val_loss: 0.6082 - val_acc: 0.6753
Epoch 5/100
100/100 [==============================] - 16s 164ms/step - loss: 0.6286 - acc: 0.6425 - val_loss: 0.5987 - val_acc: 0.6542
Epoch 6/100
100/100 [==============================] - 16s 164ms/step - loss: 0.6048 - acc: 0.6709 - val_loss: 0.5854 - val_acc: 0.6811
Epoch 7/100
100/100 [==============================] - 16s 163ms/step - loss: 0.6038 - acc: 0.6747 - val_loss: 0.5782 - val_acc: 0.6904
Epoch 8/100
100/100 [==============================] - 17s 168ms/step - loss: 0.5876 - acc: 0.6847 - val_loss: 0.7741 - val_acc: 0.5696
Epoch 9/100
100/100 [==============================] - 16s 163ms/step - loss: 0.5885 - acc: 0.6747 - val_loss: 0.6113 - val_acc: 0.6585
Epoch 10/100
100/100 [==============================] - 16s 164ms/step - loss: 0.5841 - acc: 0.6888 - val_loss: 0.5460 - val_acc: 0.7176
Epoch 11/100
100/100 [==============================] - 16s 164ms/step - loss: 0.5758 - acc: 0.6903 - val_loss: 0.5460 - val_acc: 0.7152
Epoch 12/100
100/100 [==============================] - 16s 164ms/step - loss: 0.5736 - acc: 0.7022 - val_loss: 0.5390 - val_acc: 0.7208
Epoch 13/100
100/100 [==============================] - 16s 164ms/step - loss: 0.5647 - acc: 0.7169 - val_loss: 0.5713 - val_acc: 0.7062
Epoch 14/100
100/100 [==============================] - 16s 165ms/step - loss: 0.5624 - acc: 0.7084 - val_loss: 0.5623 - val_acc: 0.7119
Epoch 15/100
100/100 [==============================] - 16s 165ms/step - loss: 0.5529 - acc: 0.7166 - val_loss: 0.5124 - val_acc: 0.7384
Epoch 16/100
100/100 [==============================] - 16s 163ms/step - loss: 0.5468 - acc: 0.7238 - val_loss: 0.5139 - val_acc: 0.7371
Epoch 17/100
100/100 [==============================] - 16s 163ms/step - loss: 0.5416 - acc: 0.7250 - val_loss: 0.5402 - val_acc: 0.7234
Epoch 18/100
100/100 [==============================] - 16s 164ms/step - loss: 0.5448 - acc: 0.7197 - val_loss: 0.5158 - val_acc: 0.7378
Epoch 19/100
100/100 [==============================] - 16s 164ms/step - loss: 0.5326 - acc: 0.7356 - val_loss: 0.4966 - val_acc: 0.7525
Epoch 20/100
100/100 [==============================] - 16s 165ms/step - loss: 0.5291 - acc: 0.7353 - val_loss: 0.4821 - val_acc: 0.7629
Epoch 21/100
100/100 [==============================] - 16s 164ms/step - loss: 0.5115 - acc: 0.7475 - val_loss: 0.5413 - val_acc: 0.7259
Epoch 22/100
100/100 [==============================] - 17s 168ms/step - loss: 0.5181 - acc: 0.7434 - val_loss: 0.4814 - val_acc: 0.7680
Epoch 23/100
100/100 [==============================] - 17s 167ms/step - loss: 0.5190 - acc: 0.7397 - val_loss: 0.5156 - val_acc: 0.7379
Epoch 24/100
100/100 [==============================] - 16s 163ms/step - loss: 0.5224 - acc: 0.7438 - val_loss: 0.4972 - val_acc: 0.7384
Epoch 25/100
100/100 [==============================] - 17s 167ms/step - loss: 0.5043 - acc: 0.7522 - val_loss: 0.5792 - val_acc: 0.7055
Epoch 26/100
100/100 [==============================] - 16s 165ms/step - loss: 0.5028 - acc: 0.7519 - val_loss: 0.5163 - val_acc: 0.7386
Epoch 27/100
100/100 [==============================] - 16s 164ms/step - loss: 0.5044 - acc: 0.7544 - val_loss: 0.4509 - val_acc: 0.7887
Epoch 28/100
100/100 [==============================] - 17s 168ms/step - loss: 0.4962 - acc: 0.7541 - val_loss: 0.5699 - val_acc: 0.7253
Epoch 29/100
100/100 [==============================] - 17s 166ms/step - loss: 0.4886 - acc: 0.7675 - val_loss: 0.4727 - val_acc: 0.7771
Epoch 30/100
100/100 [==============================] - 17s 168ms/step - loss: 0.4916 - acc: 0.7638 - val_loss: 0.4454 - val_acc: 0.7792
Epoch 31/100
100/100 [==============================] - 17s 170ms/step - loss: 0.4917 - acc: 0.7628 - val_loss: 0.4558 - val_acc: 0.7764
Epoch 32/100
100/100 [==============================] - 17s 173ms/step - loss: 0.4749 - acc: 0.7691 - val_loss: 0.4785 - val_acc: 0.7745
Epoch 33/100
100/100 [==============================] - 17s 168ms/step - loss: 0.4763 - acc: 0.7616 - val_loss: 0.4631 - val_acc: 0.7817
Epoch 34/100
100/100 [==============================] - 17s 166ms/step - loss: 0.4804 - acc: 0.7691 - val_loss: 0.4684 - val_acc: 0.7796
Epoch 35/100
100/100 [==============================] - 17s 166ms/step - loss: 0.4776 - acc: 0.7666 - val_loss: 0.5181 - val_acc: 0.7532
Epoch 36/100
100/100 [==============================] - 16s 165ms/step - loss: 0.4730 - acc: 0.7719 - val_loss: 0.4484 - val_acc: 0.7867
Epoch 37/100
100/100 [==============================] - 17s 166ms/step - loss: 0.4606 - acc: 0.7791 - val_loss: 0.4628 - val_acc: 0.7779
Epoch 38/100
100/100 [==============================] - 16s 165ms/step - loss: 0.4632 - acc: 0.7812 - val_loss: 0.5133 - val_acc: 0.7635
Epoch 39/100
100/100 [==============================] - 17s 166ms/step - loss: 0.4528 - acc: 0.7844 - val_loss: 0.4992 - val_acc: 0.7468
Epoch 40/100
100/100 [==============================] - 17s 166ms/step - loss: 0.4608 - acc: 0.7844 - val_loss: 0.4504 - val_acc: 0.7951
Epoch 41/100
100/100 [==============================] - 16s 165ms/step - loss: 0.4628 - acc: 0.7769 - val_loss: 0.4455 - val_acc: 0.7996
Epoch 42/100
100/100 [==============================] - 17s 166ms/step - loss: 0.4515 - acc: 0.7847 - val_loss: 0.4868 - val_acc: 0.7678
Epoch 43/100
100/100 [==============================] - 16s 165ms/step - loss: 0.4580 - acc: 0.7825 - val_loss: 0.4285 - val_acc: 0.8009
Epoch 44/100
100/100 [==============================] - 17s 165ms/step - loss: 0.4435 - acc: 0.7909 - val_loss: 0.4704 - val_acc: 0.7881
Epoch 45/100
100/100 [==============================] - 17s 166ms/step - loss: 0.4482 - acc: 0.7866 - val_loss: 0.4445 - val_acc: 0.8106
Epoch 46/100
100/100 [==============================] - 17s 165ms/step - loss: 0.4408 - acc: 0.8025 - val_loss: 0.4964 - val_acc: 0.7722
Epoch 47/100
100/100 [==============================] - 17s 166ms/step - loss: 0.4413 - acc: 0.7881 - val_loss: 0.4809 - val_acc: 0.7719
Epoch 48/100
100/100 [==============================] - 17s 166ms/step - loss: 0.4512 - acc: 0.7875 - val_loss: 0.4677 - val_acc: 0.7906
Epoch 49/100
100/100 [==============================] - 17s 167ms/step - loss: 0.4384 - acc: 0.7962 - val_loss: 0.4624 - val_acc: 0.7912
Epoch 50/100
100/100 [==============================] - 17s 165ms/step - loss: 0.4314 - acc: 0.7928 - val_loss: 0.4577 - val_acc: 0.7951
Epoch 51/100
100/100 [==============================] - 17s 168ms/step - loss: 0.4334 - acc: 0.7972 - val_loss: 0.5027 - val_acc: 0.7671
Epoch 52/100
100/100 [==============================] - 17s 166ms/step - loss: 0.4245 - acc: 0.8038 - val_loss: 0.4582 - val_acc: 0.7970
Epoch 53/100
100/100 [==============================] - 17s 165ms/step - loss: 0.4233 - acc: 0.8044 - val_loss: 0.4979 - val_acc: 0.7817
Epoch 54/100
100/100 [==============================] - 17s 166ms/step - loss: 0.4264 - acc: 0.7972 - val_loss: 0.4431 - val_acc: 0.7912
Epoch 55/100
100/100 [==============================] - 17s 166ms/step - loss: 0.4200 - acc: 0.8091 - val_loss: 0.4237 - val_acc: 0.8204
Epoch 56/100
100/100 [==============================] - 17s 166ms/step - loss: 0.4207 - acc: 0.8059 - val_loss: 0.4196 - val_acc: 0.8189
Epoch 57/100
100/100 [==============================] - 17s 165ms/step - loss: 0.4173 - acc: 0.8053 - val_loss: 0.5300 - val_acc: 0.7610
Epoch 58/100
100/100 [==============================] - 17s 165ms/step - loss: 0.4098 - acc: 0.8075 - val_loss: 0.4520 - val_acc: 0.8020
Epoch 59/100
100/100 [==============================] - 17s 166ms/step - loss: 0.4112 - acc: 0.8147 - val_loss: 0.4330 - val_acc: 0.8093
Epoch 60/100
100/100 [==============================] - 16s 165ms/step - loss: 0.4087 - acc: 0.8056 - val_loss: 0.4274 - val_acc: 0.8008
Epoch 61/100
100/100 [==============================] - 17s 166ms/step - loss: 0.4102 - acc: 0.8081 - val_loss: 0.4271 - val_acc: 0.8131
Epoch 62/100
100/100 [==============================] - 17s 169ms/step - loss: 0.4050 - acc: 0.8184 - val_loss: 0.4590 - val_acc: 0.8058
Epoch 63/100
100/100 [==============================] - 17s 166ms/step - loss: 0.4082 - acc: 0.8109 - val_loss: 0.4959 - val_acc: 0.7764
Epoch 64/100
100/100 [==============================] - 17s 166ms/step - loss: 0.4015 - acc: 0.8106 - val_loss: 0.4244 - val_acc: 0.8164
Epoch 65/100
100/100 [==============================] - 17s 170ms/step - loss: 0.3978 - acc: 0.8162 - val_loss: 0.4150 - val_acc: 0.8230
Epoch 66/100
100/100 [==============================] - 17s 167ms/step - loss: 0.4014 - acc: 0.8122 - val_loss: 0.4503 - val_acc: 0.7983
Epoch 67/100
100/100 [==============================] - 17s 167ms/step - loss: 0.4008 - acc: 0.8194 - val_loss: 0.4729 - val_acc: 0.7982
Epoch 68/100
100/100 [==============================] - 17s 166ms/step - loss: 0.3799 - acc: 0.8331 - val_loss: 0.4583 - val_acc: 0.8138
Epoch 69/100
100/100 [==============================] - 16s 164ms/step - loss: 0.4026 - acc: 0.8247 - val_loss: 0.4416 - val_acc: 0.8077
Epoch 70/100
100/100 [==============================] - 16s 163ms/step - loss: 0.3979 - acc: 0.8184 - val_loss: 0.4132 - val_acc: 0.8260
Epoch 71/100
100/100 [==============================] - 16s 164ms/step - loss: 0.3722 - acc: 0.8287 - val_loss: 0.4044 - val_acc: 0.8306
Epoch 72/100
100/100 [==============================] - 16s 163ms/step - loss: 0.3877 - acc: 0.8291 - val_loss: 0.4139 - val_acc: 0.8299
Epoch 73/100
100/100 [==============================] - 16s 163ms/step - loss: 0.3773 - acc: 0.8250 - val_loss: 0.4236 - val_acc: 0.8054
Epoch 74/100
100/100 [==============================] - 16s 164ms/step - loss: 0.3748 - acc: 0.8216 - val_loss: 0.4291 - val_acc: 0.8109
Epoch 75/100
100/100 [==============================] - 16s 163ms/step - loss: 0.3822 - acc: 0.8256 - val_loss: 0.5596 - val_acc: 0.7352
Epoch 76/100
100/100 [==============================] - 16s 163ms/step - loss: 0.3753 - acc: 0.8375 - val_loss: 0.4119 - val_acc: 0.8211
Epoch 77/100
100/100 [==============================] - 16s 163ms/step - loss: 0.3880 - acc: 0.8297 - val_loss: 0.4188 - val_acc: 0.8170
Epoch 78/100
100/100 [==============================] - 16s 165ms/step - loss: 0.3755 - acc: 0.8297 - val_loss: 0.4220 - val_acc: 0.8166
Epoch 79/100
100/100 [==============================] - 16s 164ms/step - loss: 0.3864 - acc: 0.8350 - val_loss: 0.4209 - val_acc: 0.8183
Epoch 80/100
100/100 [==============================] - 16s 163ms/step - loss: 0.3773 - acc: 0.8334 - val_loss: 0.4137 - val_acc: 0.8177
Epoch 81/100
100/100 [==============================] - 16s 164ms/step - loss: 0.3627 - acc: 0.8406 - val_loss: 0.5256 - val_acc: 0.7684
Epoch 82/100
100/100 [==============================] - 16s 163ms/step - loss: 0.3582 - acc: 0.8391 - val_loss: 0.4189 - val_acc: 0.8235
Epoch 83/100
100/100 [==============================] - 16s 164ms/step - loss: 0.3823 - acc: 0.8175 - val_loss: 0.4391 - val_acc: 0.8173
Epoch 84/100
100/100 [==============================] - 16s 164ms/step - loss: 0.3465 - acc: 0.8506 - val_loss: 0.4248 - val_acc: 0.8318
Epoch 85/100
100/100 [==============================] - 16s 164ms/step - loss: 0.3680 - acc: 0.8353 - val_loss: 0.4681 - val_acc: 0.8173
Epoch 86/100
100/100 [==============================] - 16s 164ms/step - loss: 0.3583 - acc: 0.8459 - val_loss: 0.3861 - val_acc: 0.8312
Epoch 87/100
100/100 [==============================] - 16s 164ms/step - loss: 0.3624 - acc: 0.8394 - val_loss: 0.5925 - val_acc: 0.7671
Epoch 88/100
100/100 [==============================] - 16s 164ms/step - loss: 0.3616 - acc: 0.8444 - val_loss: 0.3961 - val_acc: 0.8138
Epoch 89/100
100/100 [==============================] - 16s 163ms/step - loss: 0.3486 - acc: 0.8447 - val_loss: 0.3959 - val_acc: 0.8318
Epoch 90/100
100/100 [==============================] - 16s 164ms/step - loss: 0.3708 - acc: 0.8366 - val_loss: 0.4112 - val_acc: 0.8287
Epoch 91/100
100/100 [==============================] - 16s 164ms/step - loss: 0.3484 - acc: 0.8512 - val_loss: 0.4203 - val_acc: 0.8177
Epoch 92/100
100/100 [==============================] - 16s 163ms/step - loss: 0.3428 - acc: 0.8469 - val_loss: 0.4551 - val_acc: 0.8268
Epoch 93/100
100/100 [==============================] - 16s 164ms/step - loss: 0.3378 - acc: 0.8475 - val_loss: 0.4744 - val_acc: 0.7970
Epoch 94/100
100/100 [==============================] - 16s 163ms/step - loss: 0.3603 - acc: 0.8434 - val_loss: 0.3834 - val_acc: 0.8261
Epoch 95/100
100/100 [==============================] - 16s 165ms/step - loss: 0.3458 - acc: 0.8441 - val_loss: 0.4662 - val_acc: 0.7990
Epoch 96/100
100/100 [==============================] - 16s 163ms/step - loss: 0.3495 - acc: 0.8475 - val_loss: 0.3986 - val_acc: 0.8305
Epoch 97/100
100/100 [==============================] - 16s 164ms/step - loss: 0.3421 - acc: 0.8516 - val_loss: 0.4292 - val_acc: 0.8192
Epoch 98/100
100/100 [==============================] - 16s 163ms/step - loss: 0.3387 - acc: 0.8487 - val_loss: 0.4219 - val_acc: 0.8312
Epoch 99/100
100/100 [==============================] - 16s 163ms/step - loss: 0.3268 - acc: 0.8628 - val_loss: 0.4475 - val_acc: 0.8211
Epoch 100/100
100/100 [==============================] - 16s 164ms/step - loss: 0.3388 - acc: 0.8491 - val_loss: 0.5120 - val_acc: 0.7751
- 이전과 동일하게 완료된 Model은 Save 해 두도록 하겠습니다.
model.save('cats_and_dogs_small_2.h5')
- 다시 Result Graph를 그려도보록 하겠습니다.
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
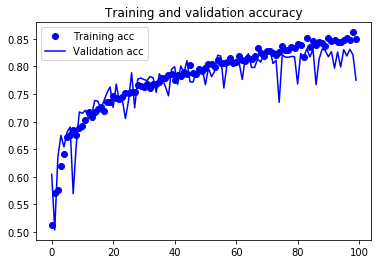
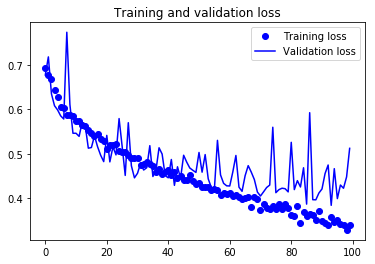
- Overfitting 현상도 보이지 않고, Validation Accuracy도 84% 정도까지 올라갔습니다.
- 다음 Exercise에서 정확도를 좀 더 향상시켜 보도록 하겠습니다.