Sequence-to-Sequence Model
Sequence-to-sequence Model
( Encoder / Decoder Model )
1. Introduction
-
Sequence-to-sequence Model은 Machine Translation , Text Summarization , Image Captioning에서 두각을 나타내는 Deep Learning Model입니다.
-
2014년 Google에 의해서 소개되었습니다.(논문, https://arxiv.org/pdf/1409.3215.pdf)
-
Sequence-to-sequence Model은 Sequence Data를 Input으로 받아서, Sequence Data로 Mapping해 주는 Model입니다. ( Many-To-Many)
-
흔히, Encoder-Decoder Model이라고도 하는데, Sequence Data를 Encoder에서 Input Sequence Data의 정보를 Context Vector로 만들고 Context Vector를 Decoder의 입력으로 넣은 후 Decoder에서 Output Context Vector를 출력하는 형태로 구성되기 때문입니다.
-
Sequence Data의 종류에는 words, letters, features of an images등 다양한 형태가 될 수 있으며, Machine Translation에서는 Sequence of Word라고 할 수 있겠습니다.
-
Encoder에 입력의 개수와 Decoder 출력의 개수는 같을 필요는 없습니다.
Machine Translation에서의 Sequence Data

2. Structure
-
Sequence-to-sequence Model은 Encoder와 Decoder, Context Vector로 구성되어 있습니다.
-
Encoder와 Decoder는 Stacked RNN 구조를 가지며,주로 LSTM or GRU로 구성됩니다.
-
RNN & LSTM에 대한 자세한 자료는 아래 Link를 참고해 주시기 바랍니다. ( 아래 2개의 Paper 모두 레전드이기 때문에 한 번 읽어보시기 바랍니다.)
https://moonlight314.github.io/deeplearning/rnn/RNN/
https://moonlight314.github.io/deeplearning/lstm/LSTM/
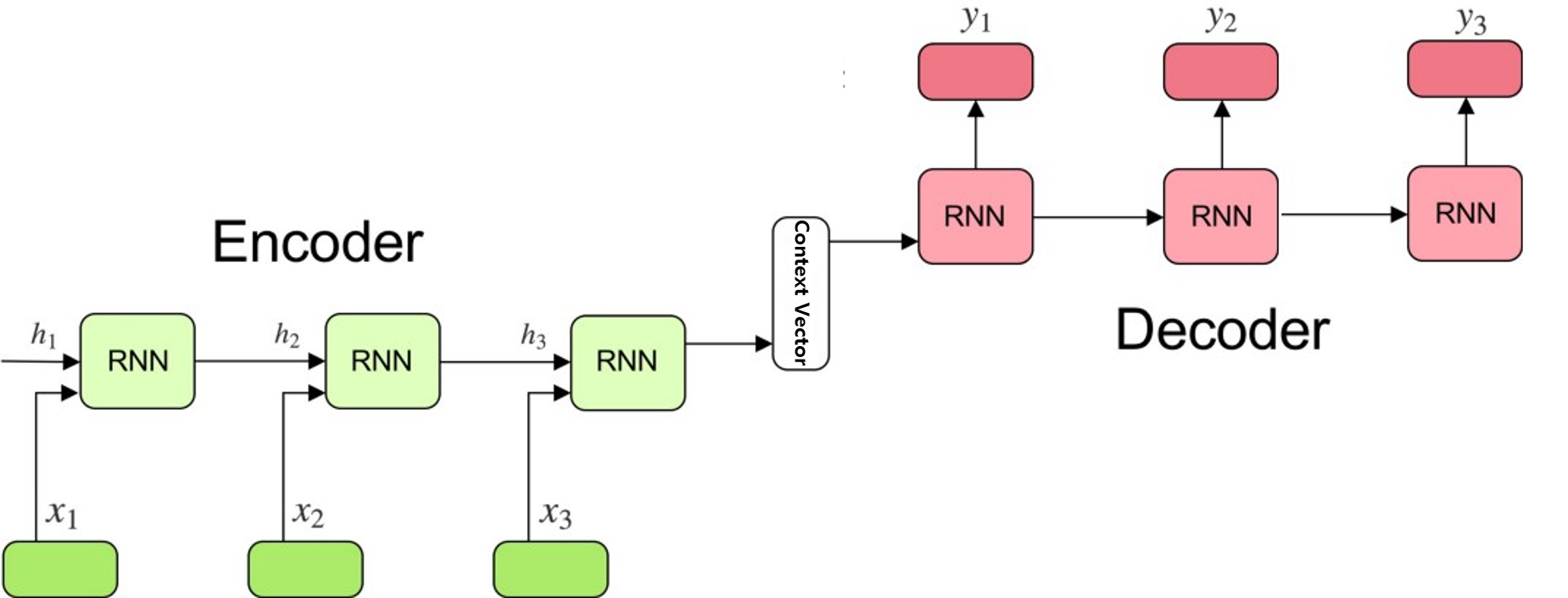
Encoder
-
Input Sequence Data를 처리하고 얻어진 정보를 Context Vector로 변환합니다.
-
LSTM이나 GRU의 Input의 Word나 Letter를 직접 입력할 수는 없고, 반드시 Numerical Representation으로 바꾸어 주어야 합니다.
-
이를 위해서 Word Embedding이라는 방법을 이용하는데, 이는 나중에 따로 다루도록 하겠습니다.
-
Word Embedding에는 다양한 Algorithm이 있으며 적절한 방법을 선택하여 Word를 변환하게 되면, 그 Word의 의미와 문맥적 정보를 담은 Vector를 반환해 줍니다.
-
Word Embedding으로 변환된 값을 RNN의 입력으로 넣어주는 겁니다.
Context Vector
-
Encoder에서 Input Sequence Data가 처리된 결과 Vector. 실제로는 Float Value Array.
-
크기는 Encoder의 Hidden Unit의 개수와 같습니다.
Decoder
- Decoder는 Context Vector를 입력으로 받아 Output Sequence Data를 생성합니다.
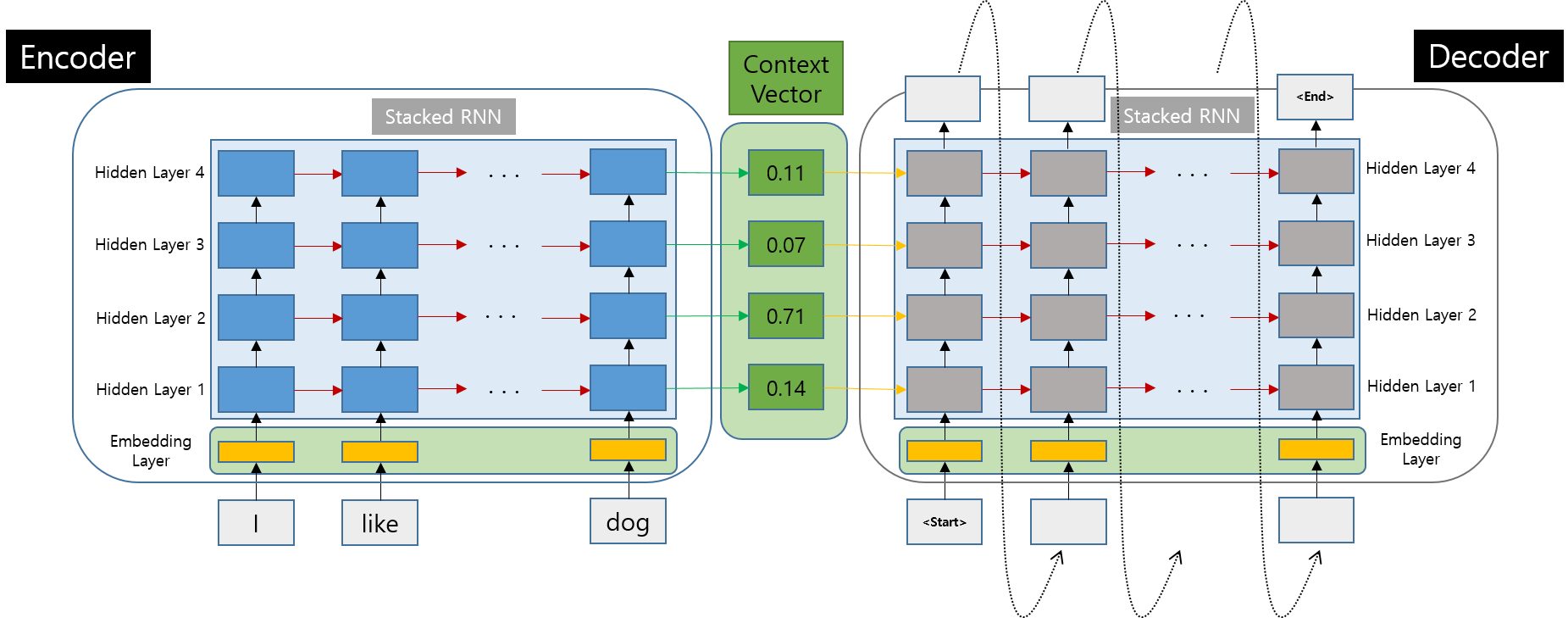
실제 구조
- 실제로 Seq2Seq의 구조는 아래와 같은 구조를 가집니다.
3. 한계
-
이러한 고전적 Sequence-to-sequence Model은 기본적인 구조가 LSTM or GRU를 Base로 하고 있습니다.
-
LSTM이나 GRU가 어느 정도는 Long Term Dependency를 개선했다고 하나, Encoder의 출력, 즉, Context Vector의 길이는 Fixed이기 때문에 여전히 Encoder의 마지막 입력이 Context Vector의 값에 많은 영향을 미친다는 것은 사실입니다.
-
즉, Encoder에 입력되는 초반의 값들은 점점 Context Vector에 영향이 적어지게 됩니다.
-
이런 이유로 Sequence-to-sequence Model은 비교적 짧은 Sequence Data에서만 동작하게 됩니다.
-
“A potential issue with this encoder-decoder approach is that a neural network needs to be able to compress all the necessary information of a source sentence into a fixed-length vector. This may make it difficult for the neural network to cope with long sentences. The performance of a basic encoder-decoder deteriorates rapidly as the length of an input sentence increases.” -Neural Machine Translation by Jointly Learning to Align and Translate
-
이런 Sequence-to-sequence Model의 구조적인 문제를 개선하기 위해서 Attention Mechanism이 나오게 되었습니다.
-
Attention Mechanism에 관해서는 이후 별도로 다루어 보도록 하겠습니다.