NLP ( Natural Language Processing )
NLP ( Natural Language Processing )
자연어 처리(natural language processing)란 우리가 일상 생활에서 사용하는 언어의 의미를 분석하여 컴퓨터가 처리할 수 있도록 하는 일을 말합니다.
이번 Post에서는 NLP의 여러 분야와 그것을 이용하여 다양한 활용 방안도 함께 살펴보도록 하겠습니다.
1. Application of NLP
NLP의 분야들을 크게 다음과 같이 나누어 보았습니다.
Sentiment Analyzer (감정 분석 )
Text classification/Clustering (Text 분류 )
E-Mail Spam and Malware Filtering ( Spam Mail & Malware 탐지 )
Chatbots ( Chatbot )
Machine Translation ( 기계 번역 )
Question Answering Model ( Q&A 모델 )
Named Entity Recognition - NER ( 개체명 인식 )
Speech Recognition system ( 음성인식 )
Text Summarization ( 문서 요약 )
2. Sentiment Analysis ( 감정 분석 )
2.1. 개요
-
감정 분석 (Opinion Mining 혹은 Emotion AI)은 자연어 처리, Text 분석, 전산 언어학 및 생체 인식을 사용하여 정서적 상태와 주관적 정보를 체계적으로 식별, 추출, 정량화 하는 것을 말합니다.
-
감정 분석은 입력된 Text가 긍정적인지 부정적인지 혹은 중립인지를 구분하는 가장 일반적인 Text 분류를 말합니다.
-
요즘은 감정 분석이 주로 Social Media에서 많이 사용되는데, 리뷰 및 설문 조사 응답, Online 및 소셜 미디어와 같은 고객 자료, 마케팅에서 고객 서비스, 임상 의학에 이르는 응용 분야의 의료 자료에 널리 적용되면 매우 유용하다는 것이 입증되었기 때문입니다.
-
뿐만 아니라, 감정 분석은 고객들이 기업에 대해서 어떻게 느끼는지 뿐만 아니라 제품들에 대해서도 어떻게 생각하는지 이해하는데 도움을 줄 수 있습니다.
-
최근 들어, Deep Learning을 이용한 Model은 Text Data에서 사람들의 감정을 분석하는 능력이 상당히 향상되었습니다.
각 항목별로 하나씩 살펴보도록 하겠습니다.
2.2. Application
2.2.1 추천 시스템 ( Recommender System )
-
추천 시스템은 사용자의 항목에 대한 선호도를 예측하는 것을 목표이기 때문에 감정 분석을 사용하는 것이 매우 유용합니다.
많은 소셜 네트워킹 서비스 또는 전자 상거래 웹 사이트에서 고객은 의견 또는 피드백을 댓글로 남길수가 있습니다. 이런 댓글은 수많은 제품 및 항목에 대해서 다양한 고객의 의견을 제공하며, 이러한 사용자의 의견은 제품에 대한 잠재적인 사용자의 감정을 나타낸다고 할 수 있습니다.
같은 제품에 대해서 사용자마다 다른 의견을 가질 수도 있고, 같은 특징을 가진 제품에 대해서도 다양한 사용자들의 다양한 의견들이 있을 수 있습니다.
이러한 다양한 제품들의 특징에 대해서 대량의 사용자들의 의견은 상거래 사이트 운영자들에게 사용자들의 깊이 있는 Insight를 제공할 수 있다는 점에서 감정 분석이 아주 유용한 정보를 제공해 줍니다.
이러한 Insight를 바탕으로 특정 사용자에게 적합한 제품을 추천해 줄 수 있는 추천 시스템 구축에 매우 중요한 역할을 할 수 있습니다.
3. Text classification/Clustering ( Text 분류 )
3.1. 개요
-
Text 분류는 NLP 기술의 중요한 종류 중 하나로써, Text Context에 따라 특정 범주로 할당하는 기술입니다.
-
사실 앞서 살펴본 감정 분석은 Text 분류의 한 종류라고 할 수도 있습니다.
-
Text 분류는 Spam Mail Detection이나 대화 분류 등에도 사용될 수도 있습니다.
-
Text 데이터는 e-Mail, Web Site , SNS , 책, 채팅 등등 어디에나 있으며, 이런 Text Data에서 어떻게 유용한 정보를 추출하는지를 알거나 숨겨진 유용한 패턴을 찾을 수 있다면 우리에게 매우 유용할 것입니다.
-
Text Classification에는 크게 “Content-based” 와 “Request-based” 의 2가지의 방법이 있습니다.
-
Content-based classification은 문서의 특정 주제에 부여 된 가중치가 문서의 종류를 결정하는 방법입니다. 예를 들어, 도서관에서 책을 분류하는 일반적인 규칙은, 적어도 책 내용의 20 %는 책이 할당 된 클래스에 관한 것이어야 합니다.
-
Request-oriented classification (혹은 Request-oriented indexing)은 사용자가 요청할 것이라고 예상되는 요청이 문서 분류에 영향을 주는 방법입니다. 또는 Request-oriented classification은 특정 대상 또는 사용자 그룹을 대상으로 하는 분류 일 수도 있습니다.
-
예를 들어, 페미니스트 연구를 위한 라이브러리 또는 데이터베이스는 기록 라이브러리와 비교할 때 문서를 다르게 분류 / 인덱싱 할 수 있습니다.
-
그러나 Request-oriented classification를 policy-based classification로 이해하는 것이 좋습니다. 어떤 정책을 사용하느냐에 따라서 분류의 결과도 달라질 수 있기 때문입니다.
3.2. Application
-
spam filtering : 수신되는 전자 메일들 중에서 스팸 메일을 식별하는 분야
-
email routing : 보낼 Mail의 주제에 따라 특정 주소 또는 우편함에 전송하는 기능
-
language identification : Text가 쓰여진 언어를 자동으로 식별하는 기능
-
genre classification : Text의 장르를 자동으로 결정하는 기능
-
readability assessment : 자동으로 Text의 가독성 정도를 결정하여 연령대 또는 독자 유형에 따라 적합한 자료를 찾는 기능
-
sentiment analysis : 문서의 일부 주제 또는 전체적인 내용에 대한 글쓴이의 태도를 결정하는 기능
-
health-related classification : 공중 보건 감시에서 소셜 미디어를 사용한 건강 관련 분류 기능
4. E-Mail Spam and Malware Filtering ( Spam Mail & Malware 탐지 )
4.1. 개요
-
Spam Mail이라는 원하지 않는 Mail의 양이 급증함에 따라서 더욱 신뢰성이 높고 강력한 Spam Mail 방지 Filter의 필요성이 생겨나게 되었습니다.
-
이런 Spammer가 Spam Mail을 보냄으로써 Spam Mail로 인해서 일반 사용자들이 시간을 낭비하게 되고 저장 용량 및 Network 자원까지도 낭비하게 만듭니다.
-
Network을 따라 전달되는 대량의 Spam Mail은 Mail Server의 Memory 용량이나 대역폭, CPU 성능 및 사용자 시간 등에도 매우 안 좋은 영향을 미치게 됩니다.
-
최근에는 Machine learning 혹은 NLP 등을 이용하여 이러한 Spam Mail을 효과적으로 Filtering하고 있습니다.
-
아래의 Link는 고전적인 Spam Filter에 관련된 내용입니다.
5. Chatbots ( 챗봇 )
5.1. 개요
-
Chatbot은 실시간으로 사람과 직접 접촉하는 대신 Text 또는 Text 음성 변환을 통해 Online 채팅을 하는 소프트웨어를 말합니다.
-
“ChatterBot”이라는 용어는 원래 1994 년 Michael Mauldin (첫 번째 Verbot의 제작자)이 대화 프로그램을 설명하기 위해 만들었습니다.
-
Chatbot은 일반적으로 고객 서비스 또는 정보 수집을 포함한 다양한 목적으로 사용됩니다.
-
일부 Chatbot 응용 프로그램은 광범위한 단어 분류 프로세스, 자연어 프로세서 및 정교한 AI를 사용하기도 하지만, 데이터베이스 또는 관련 라이브러리에서 얻은 일반적인 문구를 사용하여 일반 키워드를 검색하고 응답을 생성하기도 합니다.
-
오늘날 대부분의 Chatbot은 웹 사이트 또는 Google Assistant, Amazon Alexa와 같은 가상 도우미 또는 Facebook Messenger 또는 WeChat과 같은 메시징 앱을 통해 Online에서 많이 사용됩니다.
5.2. Application
5.1.1 Messaging apps
많은 회사의 Chatbot은 메시징 앱 또는 SMS를 통해 B2C 고객 서비스, 판매 및 마케팅에 사용됩니다.
Chatbot은 일반적으로 사용자의 연락처 중 하나로 나타나지만 때때로 그룹 채팅의 참가자 역할을 할 수 있습니다.
많은 은행, 보험사, 미디어 회사, 전자 상거래 회사, 항공사, 호텔 체인, 소매점, 의료 서비스 제공 업체, 정부 기관 및 식당 체인에서 Chatbot을 사용하여 간단한 질문에 답변하고 고객 참여를 늘리며 홍보를 위해 사용되기도 하며, 고객이 주문할 수 있는 다른 방법을 제공하기도 합니다.
2017 년 연구에 따르면 회사의 4 %가 Chatbot을 사용했습니다. 2016 년 연구에 따르면 80 %의 기업이 2020 년까지 Chatbot 비즈니스를 계획하고 있다고 응답했습니다.
5.1.2 As part of company apps and websites
이전 세대의 Chatbot은 회사 웹 사이트에 존재했습니다 (예 : 2008 년에 데뷔 한 Alaska Airlines의 ‘Ask Jenn‘ 또는 2011 년에 출시 된 Expedia의 가상 고객 서비스 담당자)
차세대 Chatbot인 뉴욕시의 전자 상거래 회사의 Rare Carat은 IBM Watson 기반이며 2017 년 2 월에 소개된 "Rocky"는 다이아몬드 구매자에게 정보를 제공하기도 합니다.
5.1.3 Chatbot sequences
마케팅 담당자가 자동 응답 시퀀스와 매우 유사한 메시지 시퀀스를 작성하는데 사용합니다.
이러한 시퀀스는 사용자 상호 작용 도중에 특정 키워드 사용에 의해서 시작 될 수 있습니다.
트리거가 발생하면 다음에 예상되는 사용자 응답이 있을 때까지 일련의 메시지가 전달됩니다.
각 사용자 응답은 의사 결정 트리에서 Chatbot이 올바른 응답 메시지를 전달하기 위해 응답 시퀀스를 탐색하는 데 도움이 됩니다.
5.1.4 Company internal platforms
많은 회사에서 내부적으로 Chatbot을 사용하는 방법을 모색합니다.
Overstock.com은 병가를 요청할 때 간단하지만 시간이 많이 걸리는 특정 프로세스를 자동화하기 위해 Mila라는 Chatbot을 사용한다고 합니다.
Roloyds Banking Group, 스코틀랜드 왕립 은행 (Royal Bank of Scotland), 르노 (Renault) 및 시트로엥 (Citroën)과 같은 다른 대기업들은 이제 첫 접촉 지점을 제공하기 위해 인간과의 콜센터 대신 자동화 된 Online Assistant를 사용하고 있습니다.
페이스 북의 마크 주커 버그 (Mark Zuckerberg)가 메신저가 Chatbot을 앱에 허용할 것이라고 발표 한 이후에 SaaS Chatbot 비즈니스 생태계는 꾸준히 성장하고있습니다.
5.1.5 Healthcare
Chatbot은 의료 산업에도 등장하고 있습니다.
한 연구에 따르면 미국의 의사는 Chatbot이 예약을 하거나 건강 클리닉을 찾거나 약물 정보를 제공하는 데 가장 도움이 될 것이라고 생각합니다.
또한, COVID-19 전염병이 발생하는 동안 최종 사용자에게 정보를 제공하기 위해 많은 Chatbot이 배포되었습니다.
5.1.6 Politics
뉴질랜드에서는 시맨틱 분석 머신 (Semantic Analysis Machine)을 위한 Chatbot SAM(Touchtech의 Nick Gerritsen 제작)이 개발되었다.
예를 들어 기후 변화, 건강 관리 및 교육 등과 같은 주제에 대한 정치적 사고를 공유하도록 설계되었습니다.
5.1.7 Toys
Chatbot은 장난감과 같은 컴퓨팅 용이 아닌 장치에도 적용됩니다.
Hello Barbie는 ToyTalk 회사에서 제공한 Chatbot을 사용하는 인형입니다.
이전에 어린이를 위한 다양한 스마트 폰 기반 문자에 Chatbot을 사용했습니다.
이러한 캐릭터의 행동은 사실상 특정 캐릭터를 에뮬레이트하고 스토리를 생성하는 일련의 규칙으로 제한됩니다.
My Friend Cayla 인형은 Android 또는 iOS 모바일 앱과 함께 음성 인식 기술을 사용하여 어린이의 음성을 인식하고 대화를 나누는 인형으로 판매되었습니다.
IBM의 Watson 컴퓨터는 CogniToys와 같은 회사에서 교육 목적으로 어린이와 상호 작용하기위한 Chatbot 기반 교육 완구의 기초로 사용되었습니다.
6. Machine Translation ( 기계 번역 )
6.1. 개요
-
Machine Translation(기계 번역)은 문장이나 음성을 다른 언어로 번역을 연구하는 전산언어학(computational linguistics)의 일부분입니다.
-
기본적으로 Machine Translation은 한 언어의 단어를 다른 언어의 단어로 기계적으로 대체하지만, 전체 문구와 대상 언어에서 가장 가까운 단어를 인식해야하기 때문에 그 자체만으로는 번역이 잘되지 않습니다.
-
보통 한 언어의 모든 단어가 다른 언어의 동등한 단어가 있는 것이 아니며 많은 단어가 둘 이상의 의미를 갖습니다.
-
현재 Machine Translation SW는 종종 특정 도메인 또는 전문 분야(예 : 날씨 보고서)별로 사용자 정의 문구를 허용하여 허용 가능한 대체 범위를 제한하여 번역 결과를 향상시킵니다.
-
이 기술은 공식 또는 공식 언어가 사용되는 특정 도메인에서 특히 효과적입니다.
-
Machine Translation 에서 사람이 조금만 손을 보면 출력 품질을 향상시킬 수도 있습니다. 예를 들어, 일부 시스템은 사용자가 Text에서 어떤 단어가 적절한 이름인지 명확하게 식별한 경우 더 정확하게 번역 할 수 있습니다.
-
이러한 기술의 도움으로 Machine Translation은 인간 번역가를 지원하는 도구로 유용한 것으로 입증되었으며 매우 제한된 수의 경우 출력물을 그대로 사용할 수 있는 결과물 (예 : 날씨 보고서)을 생성 할 수도 있습니다.
7. Question Answering Model ( Q&A 모델 )
7.1. 개요
-
Question answering은 “정보 검색 및 자연 언어 처리 (NLP)”분야의 컴퓨터 과학 분야로, 인간이 제기 한 질문에 대해 자연 언어로 자동 응답하는 시스템입니다.
-
일반적으로 Question Answering Model은 지식 기반의 구조화된 DB에서 응답을 구성하여 인간에게 답변합니다.
-
최근 NLP Model은 다양한 Text Generation Model 및 Dataset으로 성능을 더욱 향상시키고 있습니다.
8. Named Entity Recognition - NER ( 개체명 인식 )
8.1. 개요
-
Named Entity Recognition (NER, 개체명 인식 )은 Text에서 특정 요소를 찾아서 인식하는 정보 추출의 중요한 하위 영역입니다.
-
기술이 발전하고 있음에도 여전히 이 분야에서는 두드러진 성과가 없는 편이다.
-
NER 분야의 연구에 중요한 부정적 측면은 이 분야는 사람의 손으로 Feature들을 가공해야 하며, Domain-Specific한 지식이 매우 중요하다는 점입니다.
9. Speech Recognition system ( 음성인식 )
9.1. 개요
-
Speech recognition 은 컴퓨터 과학 및 전산 언어학의 서브 필드로 컴퓨터에서 음성 언어를 Text로 인식하고 번역 할 수 있는 방법론과 기술을 말합니다.
-
컴퓨터 과학, 언어학 및 컴퓨터 공학 분야의 지식과 연구가 연관되어 있습니다.
-
Speech recognition 은 사람의 특정 음성을 분석하고 이를 사용하여 해당 사람의 음성 인식을 미세 조정하여 정확도를 높이고 있습니다.
-
Training이 필요하지 않는 시스템을 “화자 독립형”시스템이라고 하며 Training이 필요한 시스템을 "화자 의존적"이라고합니다.
-
음성 인식 응용 시스템에는 음성 다이얼링 (예 : "콜홈"), 통화 라우팅 (예 : "수집 전화를 걸고 싶습니다"), 가정용 기기 제어, 주요 단어 검색 (예 : 특정 단어가있는 팟 캐스트 찾기)과 같은 음성 사용자 인터페이스가 포함됩니다. ), 간단한 데이터 입력 (예 : 신용 카드 번호 입력), 구조화 된 문서 준비 (예 : 방사선 보고서), 발언자 특성 결정, 음성-Text 처리 (예 : 워드 프로세서 또는 이메일)와 같은 예가 있습니다.
-
Voice recognition 또는 speaker identification이라는 것은 말하는 내용이 아니라 말하는 사람을 식별하는 것을 말합니다.
-
말하는 사람을 인식하면 특정 사람의 음성에 대해 훈련 된 시스템에서 음성 번역 작업을 단순화하거나 보안 프로세스의 일부로 화자의 신원을 인증 또는 확인하는 데 사용할 수 있습니다.
10. Text Summarization ( 문서 요약 )
10.1. 개요
-
Text Summarization은 Text의 핵심 정보 내용과 전반적인 의미를 유지하면서 간결하고 유용한 요약을 작성하는 작업입니다.
-
요약은 Text를 더 짧은 버전으로 압축하여 초기 Text의 크기를 줄이면서 동시에 주요 정보 요소와 내용의 의미를 보존하는 작업입니다.
-
수동 Text Summarization 은 시간이 많이 걸리고 일반적으로 힘든 작업이므로 작업의 자동화가 점점 인기를 얻고 있으므로 학술 연구에 대한 강력한 동기가 됩니다.
10.2. 종류
- Text Summarization에는 크게 다음과 같은 2종류로 나누어진다.
- Extractive Summarization
- Abstractive Summarization
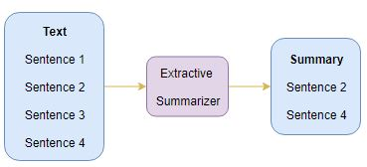
Extractive Summarization
- 요약문의 문장이나 문구를 원래의 Text에서 아무런 변형이나 수정없이 그대로 가져와서 요약문으로 사용하는 요약방식입니다.
Abstractive Summarization
-
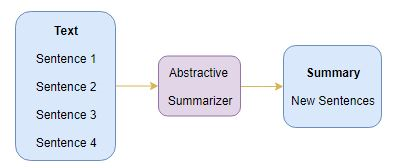
Abstractive Summarization은 원래의 문장에서 새로운 문장을 만들어 내고 이것을 요약문으로 사용하는 방식입니다.
-
앞서 소개드린 Extractive Summarization은 원래 있던 문장을 선택하여 그대로 사용하지만, Abstractive Summarization은 원래 문장의 뜻을 이해하고 추가적으로 새로운 단어 / 문구를 생성하여야 하기 때문에 훨씬 더 고난이도의 작업임을 알 수 있습니다.
11. 다양한 NLP Project들
-
아래의 Link에서는 여기에 소개해드린 주제 이외에도 다양한 NLP Project와 더불어 NLP 뿐만 아니라 다양한 분야의 Deep Learning 활용 SOTA(State-Of-The-Art) Solution 들이 일목요연하게 소개되어 있습니다.
https://paperswithcode.com/area/natural-language-processing
12. Text 분석 API들
-
마지막으로 아래 Link는 다양한 NLP Task에서 활용할 수 있는 Service들을 소개해 놓은 Blog를 소개해 드리겠습니다.
https://blog.api.rakuten.net/top-10-best-text-analytics-apis/