Attention Mechanism
Attention Mechanism
-
Attention Mechanism은 2015년 Neural machine translation by jointly learning to align and translate 이라는 논문에서 최초로 소개되었습니다. Attention이라는 단어는 직접적으로 등장하지는 않았지만, ‘Align’이라는 단어가 사용되었습니다.
-
Machine Translation에서 큰 위력을 발휘하고 있는 Self-Attention, Transformer, BERT가 모두 Attention을 Base로 만들어진 개념들입니다.
-
이번에는 Attention Mechanism에 대해서 알아보도록 하겠습니다.
0. Seq2Seq Model vs Attention Mechanism
- 우선, 기존의 Seq2Seq Model과의 비교를 위해 간단하게 구조를 비교해 보도록 하겠습니다.
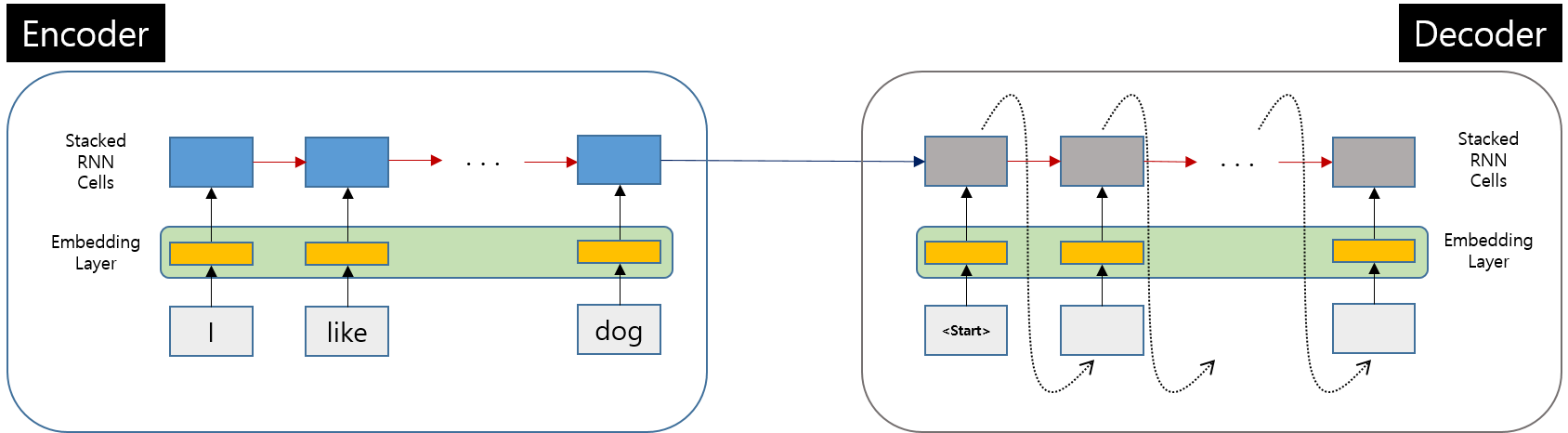
0.1. 기존 Seq2Seq Model
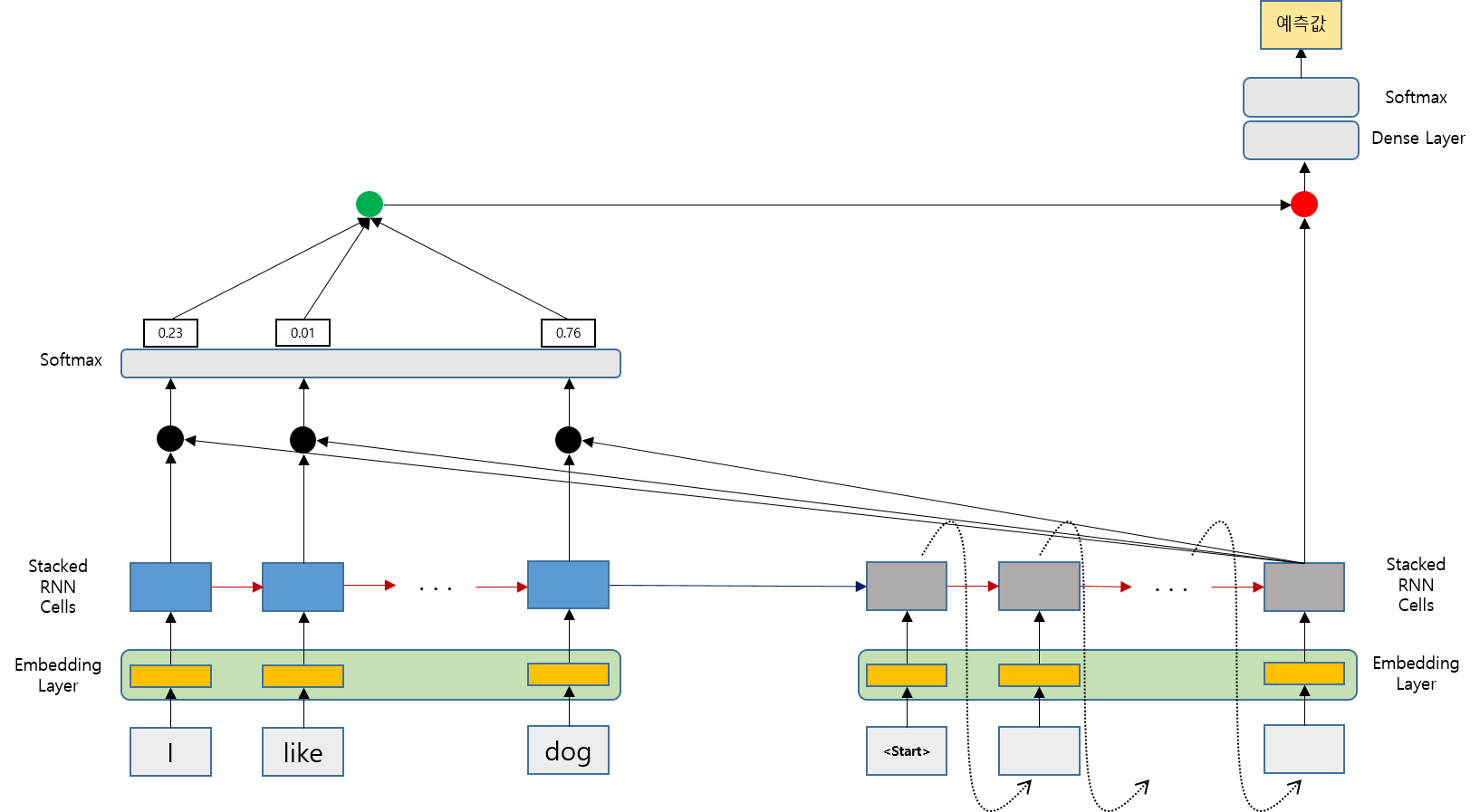
0.2. Attention Mechanism 적용 Model
-
기존 Seq2Seq Model에서 몇가지 값들이 추가된 것을 확인할 수 있습니다.
-
추가된 값들과 내용들에 대해서 하나씩 알아보도록 하겠습니다.
1. Attention Mechanism
-
기존 Seq2Seq Model에서 Decoder가 시점 t에서 출력 값을 얻기 위해 필요한 값은 t-1에서의 Hidden State와 t-1의 출력 값입니다.
-
Attention Mechanism에서는 여기에서 Attention Value가 추가로 필요합니다.
-
이제부터 Attention Value를 어떻게 구하는지 한 번 알아보도록 하겠습니다.
-
Attention Value는 아래와 같은 순서로 찾습니다. 각 값들에 대해서 하나씩 알아보죠
Attention Value는 다음 4가지 순서(값)을 계산하면서 값을 구할 수 있습니다.
1) Attention Score
2) Attention Distribution
3) Attention Value( Output )
4) Decoder Hidden State
2. Attention Score
-
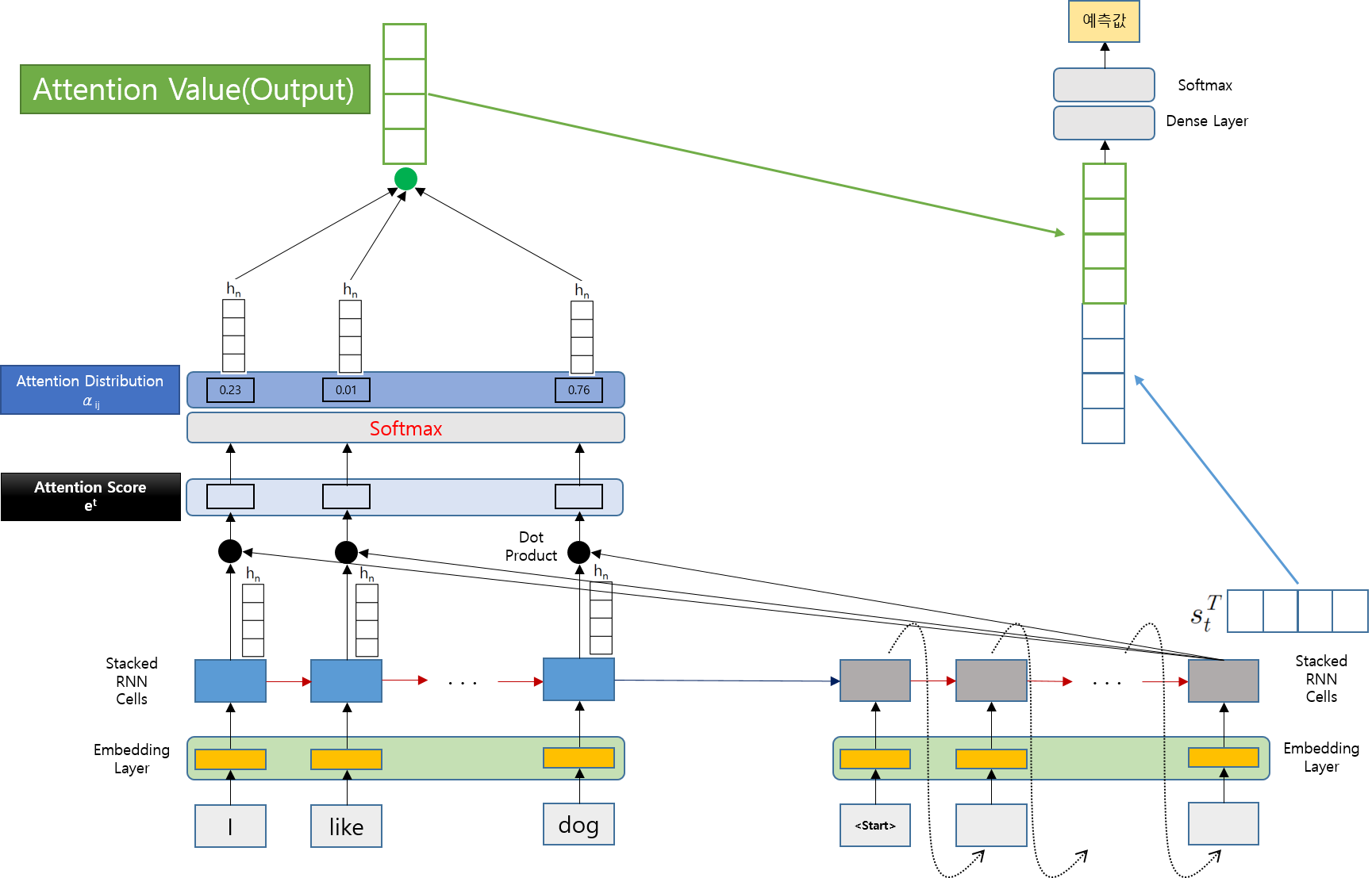
Attention Score란 Decoder가 t 시점에서 출력(예측값)을 얻기 위해 Encoder의 각 Hidden State가 현재 Decoder의 Hidden State와 얼마나 유사한 지를 나타내는 값이라고 보면 됩니다.
-
모든 Encoder의 Hidden State와 계산을 하기 때문에 하나의 Decoder Hidden State 값의 Attention Score의 값은 Encoder의 Hidden State 값의 개수와 동일합니다.
-
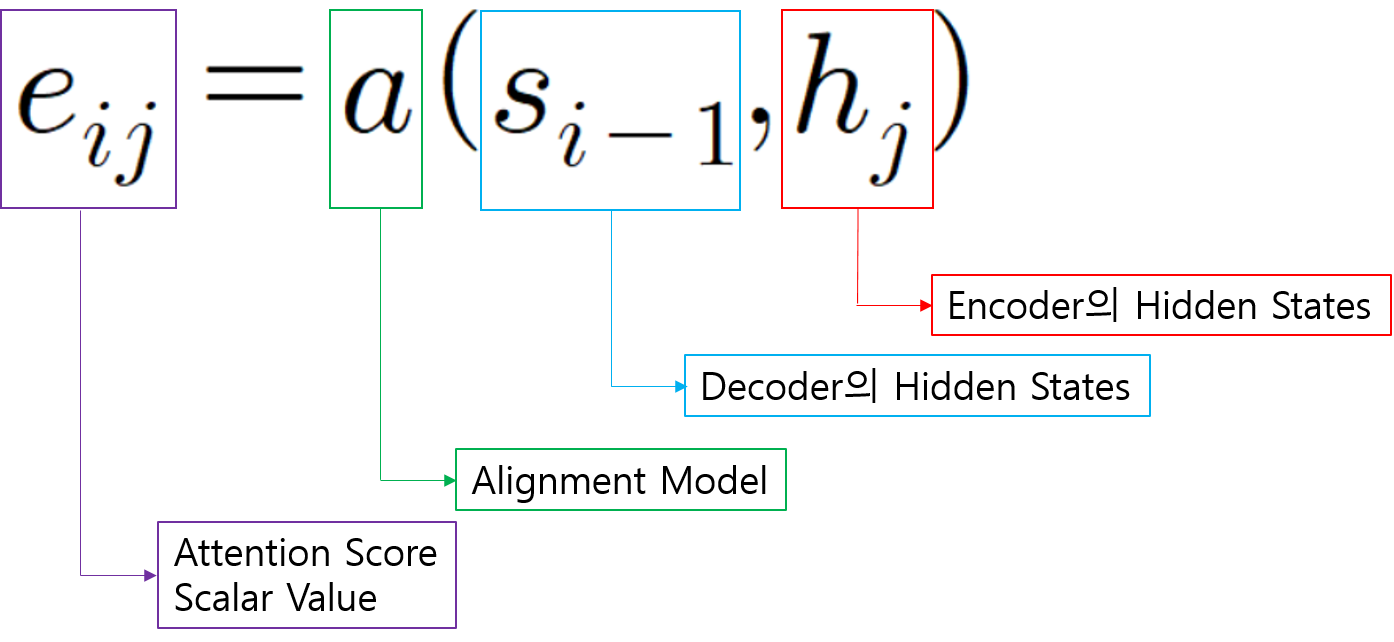
실제 Attention Score구하는 공식은 아래와 같습니다.
-
Attention Score의 모음 et = [ … … … … ]와 같은 형태의 Scalar 값의 모음이 될 것이다.
-
a(Alignment Model)은 Attention Score를 계산하는 방법이며, 이는 다양한 방법이 있을 수 있다.
-
다양한 Alignment Model(Attention Score)은 마지막에 소개해 드리겠습니다.
- 이번 글에서는 Dot Product를 이용하여 Attention Score를 계산하는 방법을 Alignment Model로 채택했다면, Attention Score는

가 될 것이고, Attention Score의 모음 et 는 다음과 같은 형태가 될 것입니다.

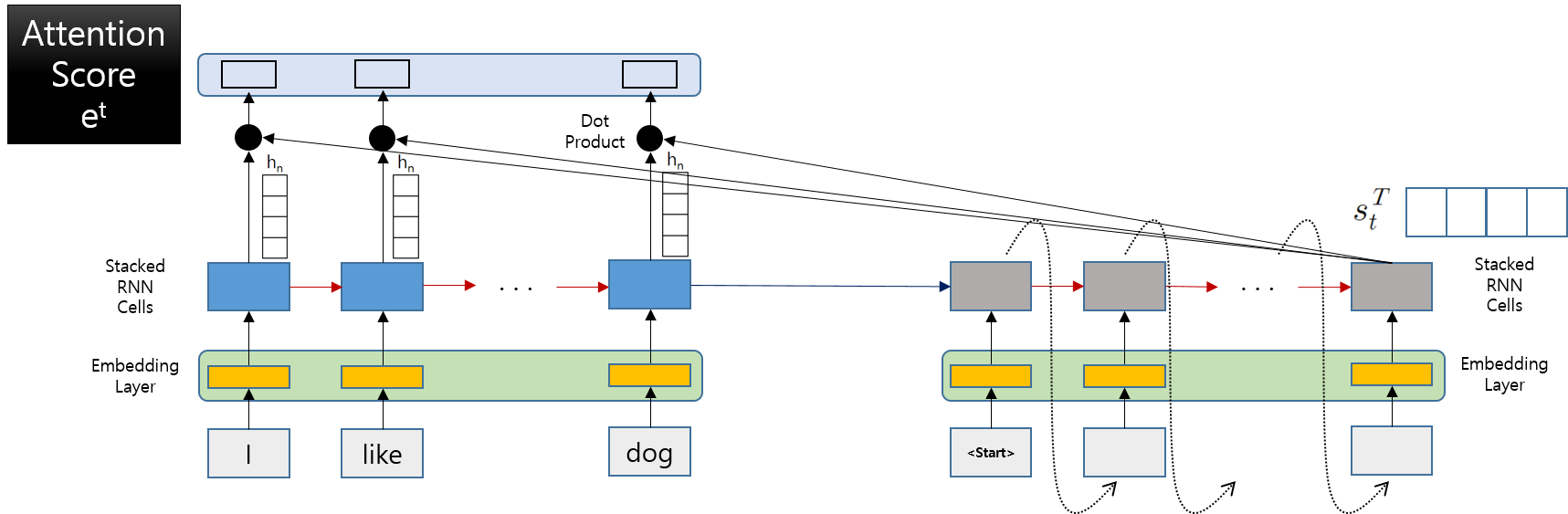
-
위 그림에서는 Attention Score를 Decoder의 마지막 단계의 값을 계산하는 과정에서 나타내고 있습니다.
-
실제로 Attention Score는 Decoder의 각 단계마다 계산을 하게 됩니다.
3. Attention Distribution
-
첫번째 Step에서 계산한 Attention Score를 softmax를 통과시켜서 각 값들의 비중을 계산하고, 최종적으로 Attention Distribution을 만듭니다.
-
계산된 값들은 합이 1이 되고, 이 값들이 바로 입력 시간 스텝에 대한 가중치, 즉 "시간의 가중치"가 됩니다.
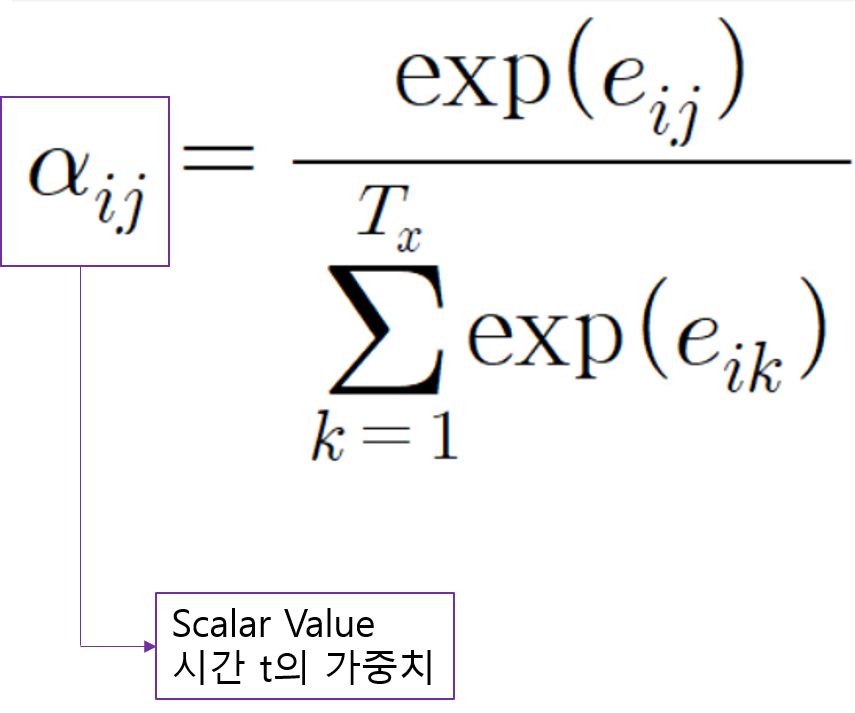
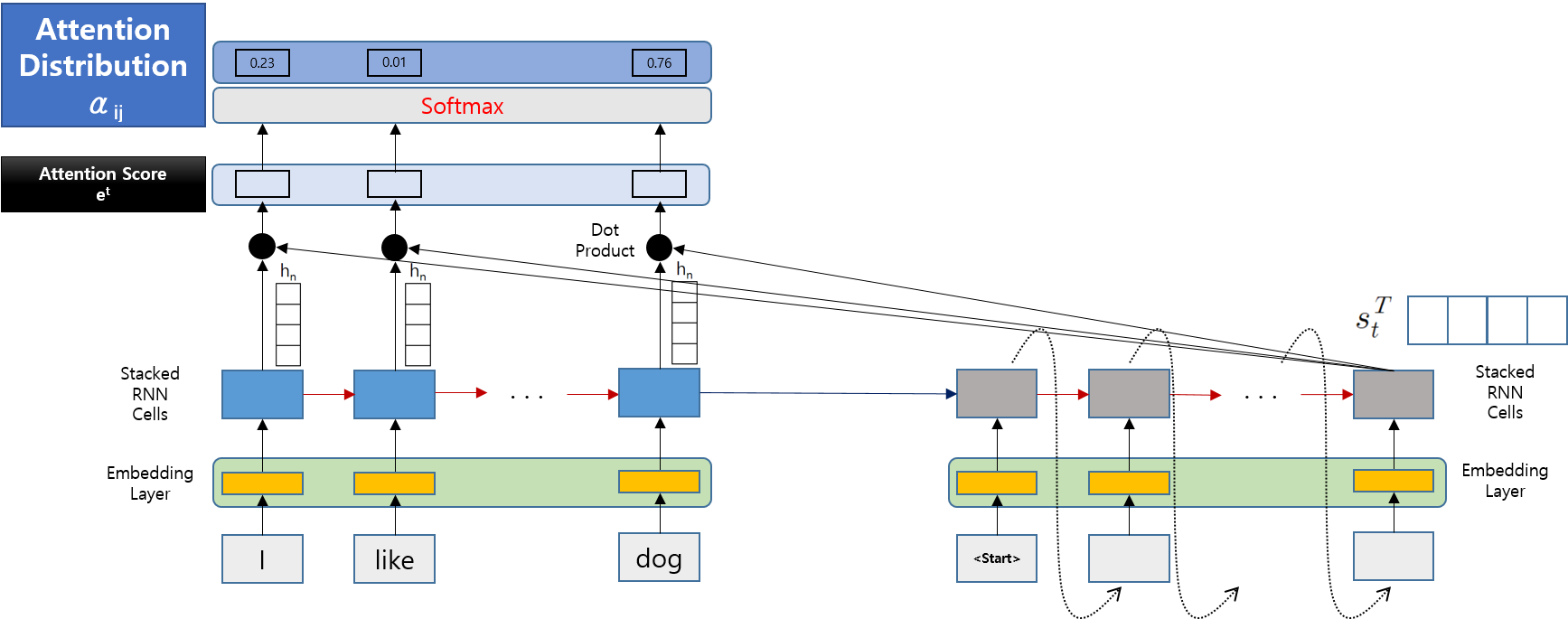
-
아래 그림은 Attention Distribution을 계산하는 위치를 나타낸 것입니다.
-
간단하게 Attention Score 값들을 Softmax하는 과정입니다.
4. Attention Value(Output)
-
이제 지금까지 계산한 결과를 하나의 값을 만드는 단계입니다.
-
앞에서 계산한 Attention Distribution과 Encoder의 Hidden State를 곱하고 각 값들을 모두 더하여 최종적으로 하나의 Vector를 계산합니다. 이를 Attention Value(Output)이라고 합니다.
-
이 값은 매 Decoding때마다 다르게 계산되므로 Seq2Se2 Model의 Fixed Length Context Vector의 문제를 해결할 수 있습니다.
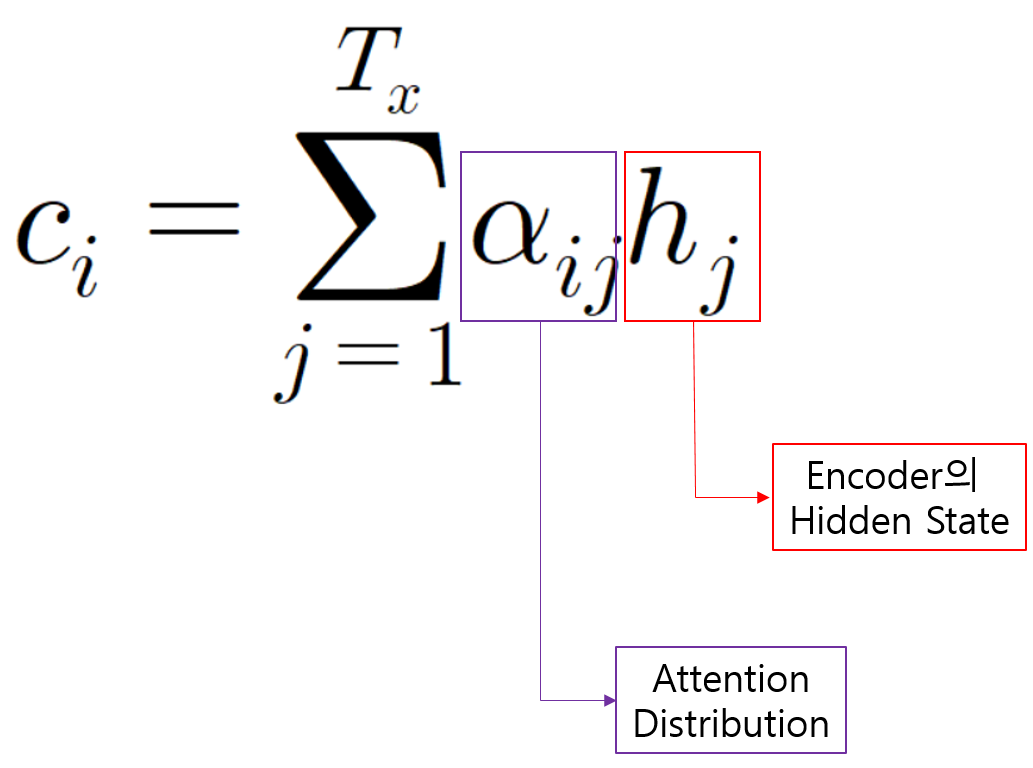
-
Attention Value와 Decoder의 Hidden State st를 Concatenate하여 새로운 st를 만듭니다.
-
새롭게 만들어진 st는 매 Step마다 Encoder의 상태를 반영하므로 Seq2Seq의 Context Vector보다 훨씬 더 예측을 잘하게 됩니다.
이것이 Attention Mechanism의 핵심입니다.
- 이를 Dense층을 통과시키고, 이 값을 Softmax하여 최종 출력값을 취합니다.
5. Decoder Hidden State 비교
-
Attention이 없는 기존 Model(Seq2Seq)에서는 Decoder의 Hidden State가 하나의 Fixed Length Context Vector만 참고하지만,
Attention Mechanism을 사용함으로써, Decoding 각 Step마다 Encoder의 정보를 참고할 수 있으므로 성능 향상을 이룹니다.


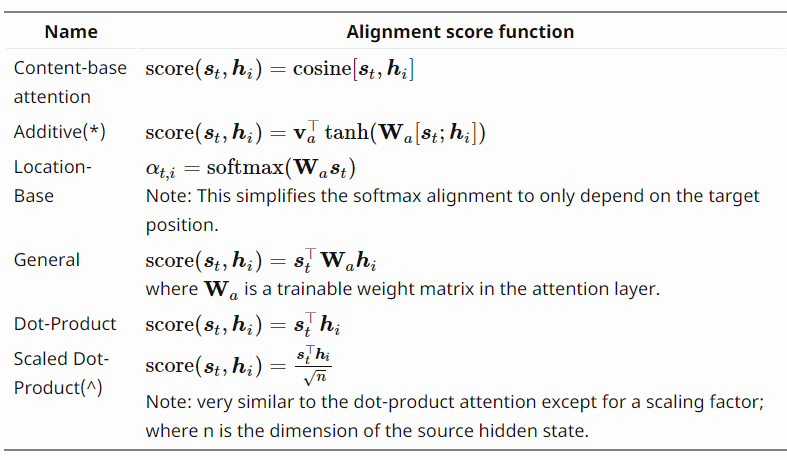
6. Attention Score Functions
- 이 자료에서 Attention Score를 구하는 방식으로 Dot Product를 예로 들었지만, 다양한 방식의 Attention Score 구하는 방법이 존재합니다.