U-Net : Convolutional Networks for Biomedical Image Segmentation
이번 Post에서는 U-Net에 관해서 알아보도록 하겠습니다.
0. Introduction
U-Net은 2015년 Olaf Ronneberger, Philipp Fischer, Thomas Brox의 “U-Net_Convolutional Networks for Biomedical Image Segmentation”이라는 Paper에 처음 소개되었으며,
효율적인 구조와 성능은 특히 적은 양의 Train Data로도 우수한 분할 결과를 얻을 수 있게 하며,
Paper 제목에서도 유추할 수 있듯이, Data가 부족하거나 비싼 의료 분야에서 특히 두각을 나타냈습니다.
1. 사용 예
U-Net의 강점은 배경과 객체를 분리하는데 특화된 모델이고 또한 특히 적은 양의 Train Data로도 우수한 분할 결과를 얻을 수 있다는 강점으로 인해 다음과 같은 영역에서 많이 사용됩니다.
1.0. 의료 이미지 분석
U-Net은 특히 MRI, CT 스캔 등의 의료 이미지에서 조직 유형이나 병변을 정밀하게 분할하는 데 사용됩니다. 이를 통해 의사들은 질병 진단, 수술 계획, 치료 효과 평가 등에 중요한 정보를 얻을 수 있습니다.
1.1. 위성 이미지 처리
위성 이미지에서 도로, 건물, 물체, 자연 풍경 등을 정확하게 분할하여 지도 제작, 환경 모니터링, 도시 계획 등에 사용됩니다.
1.2. 자동차 운전 보조
자동차의 카메라로부터 얻은 이미지를 분석하여 도로, 보행자, 다른 차량 등을 분할함으로 써 자동차가 환경을 인식하고 안전하게 주행하도록 돕습니다.
2. Structure
U-Net은 기본적으로 컨볼루션 신경망(Convolutional Neural Network, CNN)을 주로 활용한 Network 구조입니다.
전체적인 구조는 아래와 같이 ‘U’자 모양을 하고 있기 때문에 이름이 U-Net입니다.
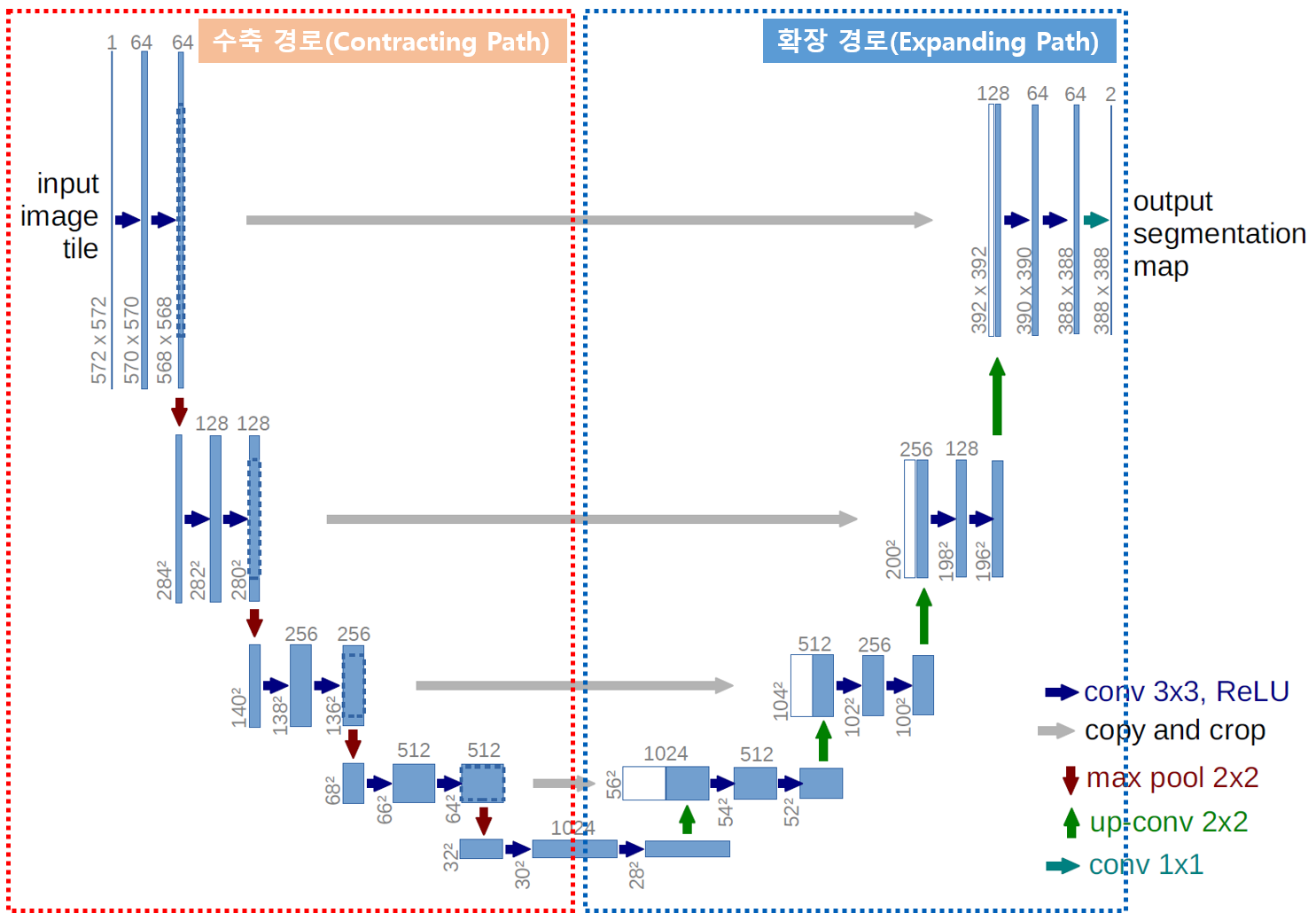
2.0. 수축 경로 (Contracting Path)
위 그림에서 왼쪽 빨간색 영역을 말하며, 이 부분은 전형적인 Convolutional Neural Network 구조를 따릅니다.
여러 개의 Convolutional Layer와 Max Pooling Layer가 포함되어 있어 입력 이미지의 특징을 추출합니다.
각 Convolutional 연산 후에는 ReLU Activation Function이 적용됩니다.
Max Pooling을 통해 Feature Map의 크기가 줄어들며, 이 과정에서 이미지의 공간적 차원이 축소됩니다.
2.1. 확장 경로 (Expanding Path)
위 그림에서 오른쪽 파란색 영역을 말하며, 확장 경로에서는 Transposed Convolution Layer를 사용하여 Feature Map의 크기를 점차 확대합니다.
수축 경로에서 추출된 Feature Map의 각 레벨은 확장 경로에서 적절한 Transposed Convolution Layer를 통해 점차적으로 원래 크기로 복원됩니다.
확장 경로의 각 단계에서는 해당 단계의 Convolution 출력과 수축 경로에서의 대응되는 Feature Map을 연결(concatenate) 합니다.
이를 통해 네트워크는 위치 정보를 보존하고, 더 정확한 분할을 가능하게 합니다.
2.2. Skip Connection
위 그림에서 왼쪽에서 오른쪽으로 연결되는 회색 화살표를 보실 수 있으실 겁니다.
이것은 Skip Connection을 의미하며, Skip Connection을 통해서 수축 경로의 Feature Map을 확장 경로의 적절한 Layer와 직접 연결함으로써, 네트워크가 깊어져도 세밀한 위치 정보를 유지할 수 있습니다.
3. Operations
U-Net의 입력부터 최종 출력인 Output Segmentation Map’을 얻기까지의 각 단계마다 어떤 연산을 거치는 알아보도록 하겠습니다.
3.0. Operation Symbols
구체적인 연산을 알아보기 전에, 그림에서 사용하는 색깔별 화살표가 의미하는 것을 알아야 쉽게 따라갈 수 있을 것 같습니다.

1) 파란색 오른쪽 화살표
일반적인 Convolutional Layer를 나타내며, Kernel Size는 3x3, Stride 1, Padding은 0이 적용되었습니다.
2) 회색 오른쪽 화살표
Skip Connection을 나타냅니다. Crop & Copy 순서로 적용되는데, 왼쪽의 값 Dimension과 오른쪽에 붙여 넣을 Dimension의 크기가 달라서 왼쪽 중간 부분을 잘라서(Crop) 오른쪽에 붙여 넣습니다.(Copy) 왼쪽 부분에 잘 안 보이지만, 파란색으로 점선이 그려져 있는데, 이 부분을 Crop 한다는 의미입니다.
3) 갈색 아래쪽 화살표
2x2 크기의 Max Pooling을 수행한다는 의미입니다. 2x2 Max Pooling이기 때문에 Dimension이 반으로 줄어듭니다.
4) 위쪽 초록색 화살표
Transposed Convolution 연산입니다.
5) 오른쪽 청록색 화살표
1x1 Convolution 연산을 나타냅니다.
3.1. Input & Convolution Layer
Input Image부터 살펴보도록 하겠습니다. Paper에 나온 수치 그대로 사용해서 살펴보도록 하겠습니다.
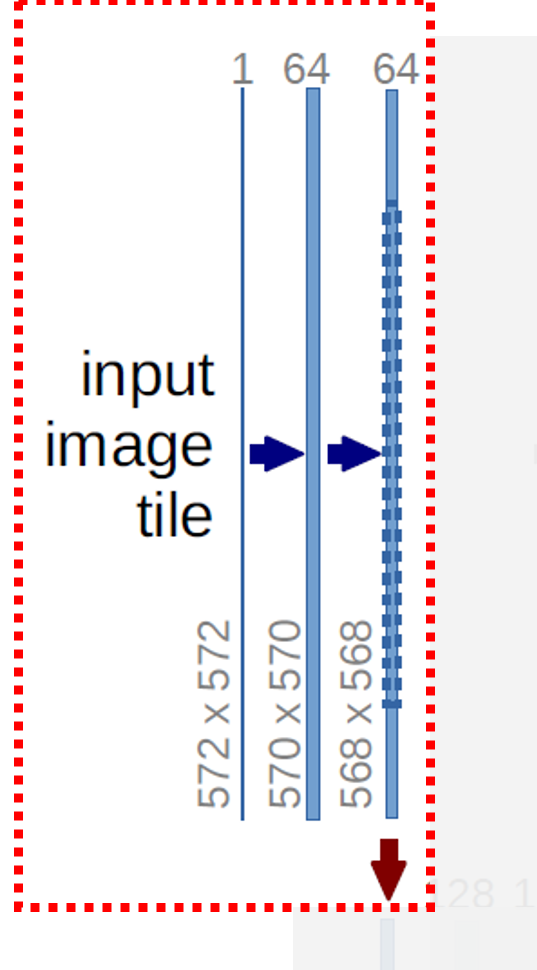
Input Image Size는 572x572입니다. 이 Image를 64개의 3x3 Kernel의 Convolutional Layer를 2번 거쳐서 568x568 Size의 Feature Map 64개를 만듭니다.
Padding이 없기 때문에 아래 위로 1 Pixel만큼 크기가 줄어드는 것을 알 수 있습니다.
오른쪽 64개의 Feature Map에서 중간 영역에 표시된 파란색 점선 부분은 이후에 적용될 Skip Connection에서 Crop & Copy에 사용될 영역입니다.
이후에 설명하도록 하겠습니다.
3.2. Max Pooling
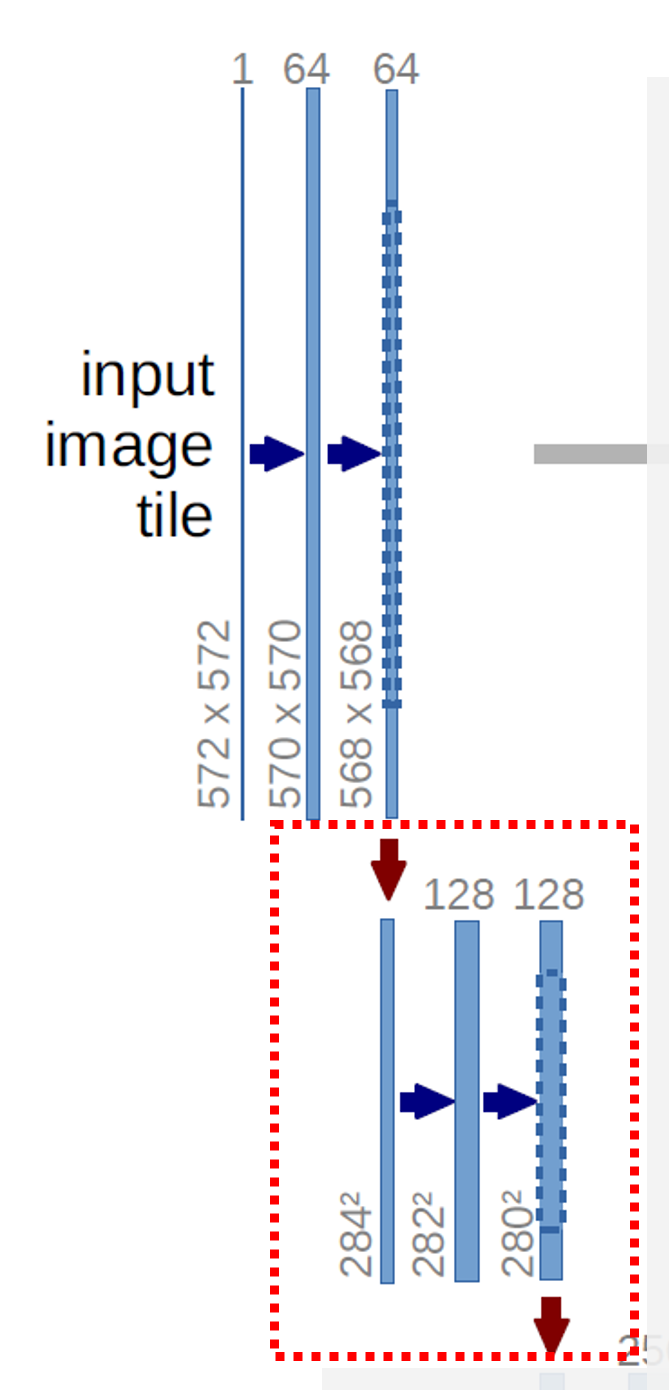
568x568 Size의 Feature Map 64개를 2x2 Max Pooling을 합니다. ( 아래 방향 빨간색 화살표는 2x2 Max Pooling을 의미합니다. )
2x2이기 때문에 크기가 반으로 줄어들어서 284x284가 되는 것을 확인할 수 있습니다.
여기에 이전과 마찬가지로 128개의 3x3 Kernel의 Convolutional Layer를 2번 거쳐서 280x280 Size의 Feature Map 128개를 만듭니다.
3.3. Repeat

위와 같은 3x3 Kernel의 Convolutional Layer & Max Pooling 과정을 Feature Map Size가 28x28x1024가 될 때까지 반복합니다.
3.4. Transposed Convolution & Skip Connection
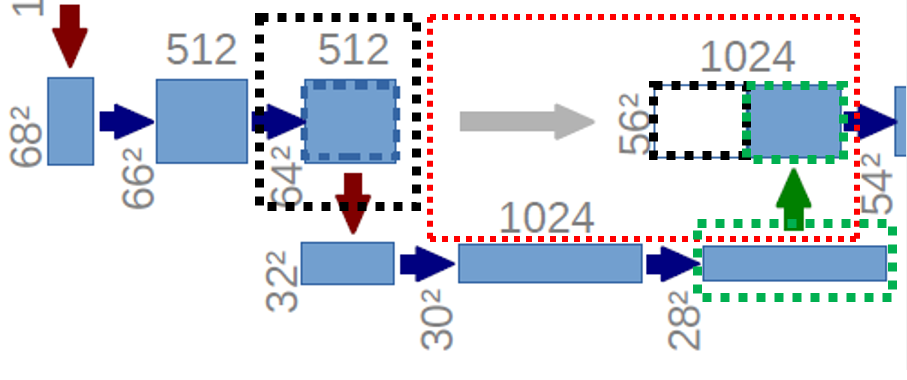
여기서부터는 확장 경로 (Expanding Path)에 속합니다.
확장 경로 (Expanding Path)에서는 Transposed Convolution 연산과 Skip Connection으로 Feature Map에서 원래 크기의 Image로 복원하는 과정을 담고 있습니다.
위 그림에서 초록색 점선 부분은 수축 경로에서 최종적으로 생성된 28x28x1024 크기의 Feature Map입니다.
여기에 Transposed Convolution을 적용하면 56x56x512 크기의 새로운 Feature Map이 만들어집니다.
추가로, 검은색 점선 부분은 수축 경로에서 64x64x512 부분의 중간 부분을 Crop 해서 56x56x512 크기만큼 잘라낸 부분을 Skip Connection으로
Transposed Convolution 연산의 결과와 Concatenate 합니다.
그럼, 결과적으로 56x56x1024 크기의 Feature Map이 만들어집니다.
3.5. Repeat
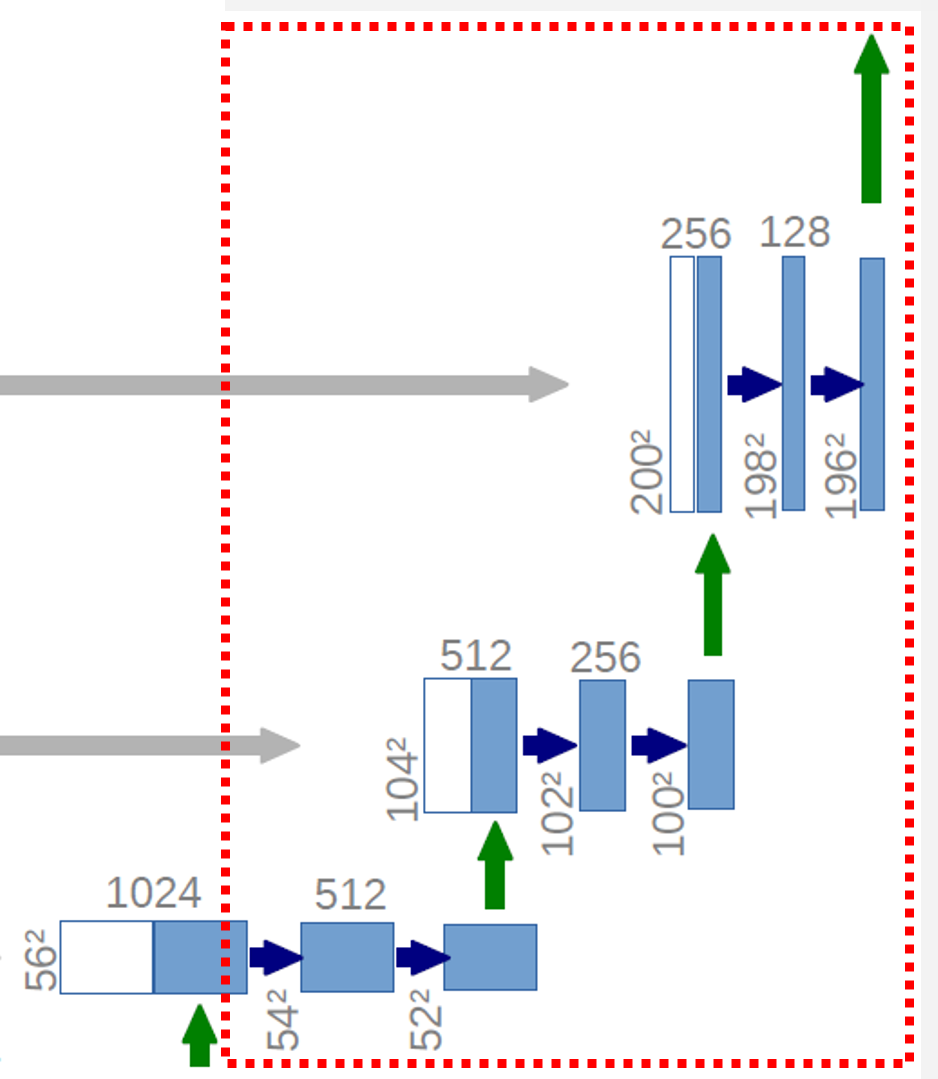
이제부터는 3x3 Kernel Convolutional Layer 2번 반복, Transposed Convolution & Skip Connection을 반복합니다.
3.6. Output Segmentation Map
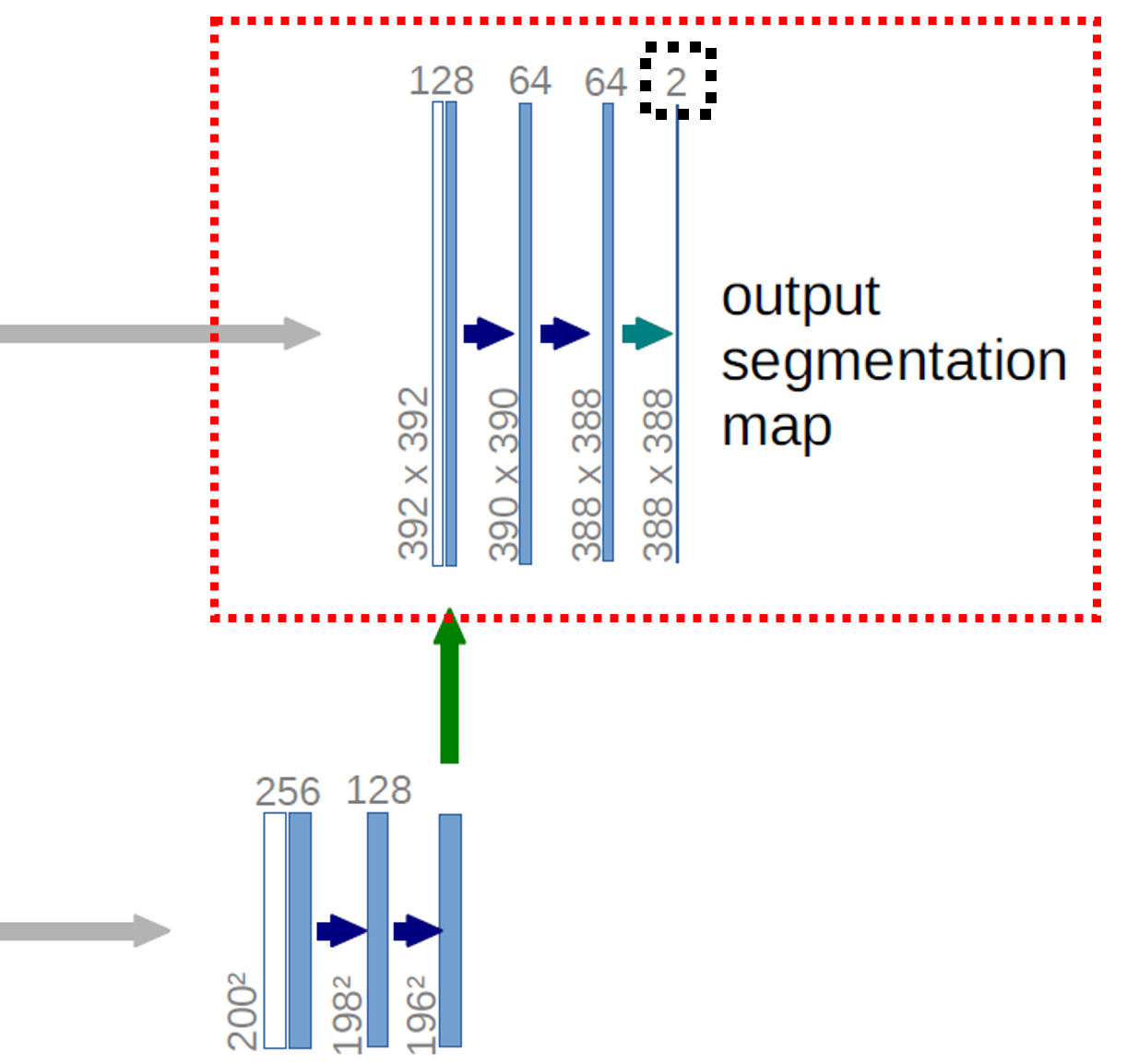
Transposed Convolution을 적용한 결과가 392x392가 되면 이제는 3x3 Kernel Convolutional Layer를 2번 거친 후에
최종적으로 Output Segmentation Map을 생성합니다.
Output Segmentation Map을 생성하는 방법은 그림에서 보는 바와 같이 388x388x64 크기의 Feature Map에 1x1 Convolution 연산을 적용하여
원하는 만큼의 Channel Depth를 만들어 내면 됩니다.
Paper에서는 Channel Depth를 2로 만든 예제를 보여주고 있습니다만, 이 값은 1x1 Convolution 연산의 Paramter를 어떻게 하느냐에 따라서 원하는 만큼 만들 수 있습니다.
3.7. Channel Depth of Output Segmentation Map
Channel Depth의 수는 이 U-Net이 분류하고자 하는 객체의 수를 나타낸다고 보시면 됩니다.
예를 들어, 이 U-Net이 사과, 배, 딸기 그리고 배경을 구분하도록 Train 되었다면,
4가지 객체를 분류할 수 있어야 하므로, Channel Depth는 4가 되어야 합니다.
Paper에서 최종 Output Segmentation Map는 388x388x2의 크기를 가지며, Paper에서 예로 든 U-Net Model은 입력 Image에서 2가지를 구분하도록 Train 되었다고 생각할 수 있습니다.
388x388 크기의 Image에서 같은 위치의 Pixel은 Channel Depth의 수만큼 값을 가진다고 생각할 수 있습니다.
이 값들을 Softmax 취하면 확률을 구할 수 있고, 해당 Pixel이 어떤 객체에 포함되는지를 확률 값으로 구할 수 있습니다.
이런 식으로 모든 Pixel 값들의 확률 값을 구하면 입력 Image에서 어떤 객체가 어디에 있는지 구분하는 Model을 만들 수 있는 것입니다.
4. U-Net Train
앞서 U-Net이 어떤 구조로 되어 있고, 어떻게 최종 결과인 Output Segmentation Map을 생성하는지와 이 Output Segmentation Map을 어떻게 해석하는지에 대해서 알아보았습니다.
그렇다면, 만약 우리가 실제로 U-Net을 Train 시키고 싶다면 어떤 준비를 해야 할까요?
앞에서 예로 설명한 사과, 배, 딸기 그리고 배경을 구분하는 U-Net Model을 만들고 싶다고 가정해 봅시다.
우선 Train에 사용할 Image Dataset을 구해야 합니다. 하나의 사진에 사과, 배, 딸기가 있는 많은 사진들이 필요하겠죠.
그리고, 각각의 Image의 각 Pixel에 해당 Pixel이 어떤 객체에 해당하는지 Labeling을 해야 합니다.(…)
U-Net의 출력은 각 Pixel이 어떤 객체인지에 대한 확률값을 가지고 있으므로, 이를 Backpropagation으로 학습을 하기 위해서는
이러한 Dataset 준비를 해야 하는 것입니다.
제 생각에는 U-Net의 구조와 구현 자체는 상당히 심플하고 쉬우나, Train을 위한 Dataset 준비가 가장 귀찮을 것 같다는 생각이 드네요.
5. vs YOLO
| U-Net | YOLO | |
|---|---|---|
| 목적 | 의료 이미징과 같은 분야에서 픽셀 수준의 이미지 세그멘테이션을 수행하기 위해 설계되었습니다.각 픽셀에 대해 정확한 클래스 레이블을 할당하며, 매우 세밀한 세그멘테이션 결과를 제공합니다. | 실시간 객체 감지를 목표로 개발된 모델로, 이미지 내 객체의 위치와 클래스를 신속하게 탐지할 수 있습니다.각 이미지를 한 번만 보고(You Only Look Once) 여러 객체를 감지하며, 그 결과를 바운딩 박스로 표시합니다. |
| 장점 | 스킵 연결과 대칭 구조 덕분에 세부적인 텍스처와 경계를 잘 포착하고, 적은 양의 데이터로도 효과적으로 학습할 수 있습니다. | 매우 빠른 속도로 동작하며, 비디오 스트림과 같은 실시간 처리에 적합합니다. 다수의 객체를 효과적으로 감지할 수 있습니다. |
| 적용 분야 | 주로 의료 영상 분석, 위성 이미지 세그멘테이션, 과학 연구 등에서 사용됩니다. | 보안 감시, 자율 주행 차량, 산업 자동화 등에서 널리 사용됩니다. |
성능 비교
세그멘테이션 vs. 객체 감지: U-Net은 픽셀 수준의 세그멘테이션에 최적화되어 있어 정밀한 영역 분할에 뛰 어난 반면, YOLO는 객체의 위치와 클래스를 빠르게 감지하는 데 초점을 맞춥니다.
정확성과 속도
U-Net은 세밀한 정보가 중요한 분야에서 높은 정확성을 제공하는 반면, YOLO는 처리 속도가 매우 빠르며, 실시간 반응이 요구되는 환경에서 유용합니다.
따라서, 두 모델 중 어느 것이 “더 좋다”고 말하기보다는, 각기 다른 작업과 요구 사항에 맞게 적절히 선택하는 것이 중요합니다. 픽셀 수준의 세밀한 분석이 필요하면 U-Net을, 빠른 객체 감지가 중요하면 YOLO를 선택하는 것이 적합합니다.
6. Summary
이상으로 U-Net에 대한 소개, 구조, 설명, 비교, 장단점 등을 알아보았습니다.
구조는 심플한 편이지만, Train 시키기에는 조금 번거로움이 있는 Architecture인 것 같네요.
도움이 되셨다면 좋겠네요.
그럼, 다음에 또 만나요~!