TensorBoard
TensorBoard
- 이번 Post에서는 Tensorflow에서 제공하는 Visualization Tool인 Tensorboard의 사용법을 알아보도록 하겠습니다.
0. TensorBoard ?
- TensorBoard는 TensorFlow에서 제공하는 시각화 도구입니다.
- Model Train 중이나 Train이 끝난 후에 Model 학습의 진행 상황, 통계, 그래프 등을 시각적으로 확인할 수 있게 도와줍니다
- https://www.tensorflow.org/tensorboard/get_started
TensorBoard의 주요 기능은 다음과 같습니다
- Scalar Visualization
- 각 Epoch 또는 Iteration마다의 Loss , Accuracy 등의 값 변화를 Graph로 시각화해 학습의 진행 상황을 모니터링 할 수 있습니다사용량 등의 세부 정보를 제공합니다.
- Model Graph
- TensorFlow 계산 Graph를 시각적으로 표현하며, Graph의 각 Node를 클릭하여 세부 정보를 볼 수 있습니다.
- Histogram Visualization
- Weight, Bias 등의 분포를 Histogram으로 시각화하여 Model 내 변수의 변화 추이를 관찰할 수 있습니다.
- 시간에 따른 값들의 분포를 3D로 보여줍니다.
- 각 단계별로 값들이 어떻게 변경되는지를 x축(값의 범위), y축(빈도 또는 개수), z축(시간 또는 학습 단계)를 사용하여 시각적으로 표현합니다.
- Distribution Visualization
- y축은 값(예: Weight 또는 Activation Function Output)을, x축은 Train 단계 또는 시간을 나타냅니다.
- 각 Train 단계에서의 값들의 최소값, 최대값, 평균, 분위수 등의 통계적 요약 정보를 표시합니다.
- Image Visualization
- Image Data를 사용하는 경우, 학습 중에 생성되는 Image나 Feature Map을 직접 볼 수 있습니다.
- Embedding Projector
- 고차원의 Embedding을 3D 또는 2D 공간에 투사하여 시각화할 수 있습니다.
- PCA, t-SNE 등의 기법을 사용하여 Data Point간의 관계를 관찰할 수 있습니다.
- Profiling Tool
- Model의 Performance Optimization를 돕기 위해 각 연산에 걸리는 시간이나 메모리 사용량 등의 세부 정보를 제공합니다.
1. 사용법
-
TensorBoard는 단순히 Model Train시 중요 지표를 보여주는 것 이상으로 다양한 기능을 지원하지만, 이번 Post에서는 간단하게만 알아보도록 하겠습니다.
-
아래 Code는 Early Stopping Callback 설명에 사용했던 예제입니다.
-
Early Stopping( Link ) 기능은 빼고, TensorBoard 기능을 넣어서 Test해 보도록 하죠
-
MNIST Dataset의 Classification Example로 실제로 Tensorboard를 어떻게 사용하는지 확인해 보도록 하겠습니다.
- 필요한 Package를 Load합니다.
import tensorflow as tf
import tensorflow_datasets as tfds
import os
from tensorflow.keras.callbacks import TensorBoard
- Train에 사용할 2개의 Dataset을 MNIST로 만듭니다.
(ds_train, ds_test), ds_info = tfds.load(
'mnist',
split=['train', 'test'],
shuffle_files=True,
as_supervised=True,
with_info=True,
)
print(type(ds_train))
<class 'tensorflow.python.data.ops.dataset_ops.PrefetchDataset'>
- Image를 Preprocessing해서 Label과 같이 Return해주는 Mapping 함수를 만듭니다.
def normalize_img(image, label):
return tf.cast(image, tf.float32) / 255., label
- Train & Val. Dataset을 만듭니다. 좀 전에 만든 Mapping Function을 적용해 줍니다.
dataset_train = ds_train.map(normalize_img)
dataset_train = ds_train.batch(128)
dataset_test = ds_test.map(normalize_img)
dataset_test = ds_test.batch(128)
- Model 구조는 Simplie하게 만들어 줍시다.
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10)
])
- 작성한 Model을 Optimizer와 Loss Function 등을 정의해서 Compile해 줍니다.
model.compile(
optimizer=tf.keras.optimizers.Adam(0.006),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
-
이제 Tensorboard Callback을 추가해 보도록 하겠습니다.
- Tensorboard Parameters
- log_dir : 정보들을 저장할 위치를 지정합니다.
- histogram_freq : 몇 Epoch마다 Historgram을 Update할 지를 결정합니다.
- 아래의 예제는 ‘Logs’라는 Folder에 Histogram을 1 Epoch마더 정보를 저장하라는 의미입니다.
log_dir = os.path.join('Logs')
tb_callback = TensorBoard(log_dir=log_dir , histogram_freq=1)
- 이제 fit()을 호출할 때, callback=[] 이라는 Parameter에 사용할 Callback들을 추가해 주면 됩니다.
- 이번 Post에서는 앞서 선언한 Tensorboard Callback(tb_callback)을 추가해 줍니다.
history = model.fit(
dataset_train,
epochs=100,
validation_data=dataset_test,
callbacks=[tb_callback]
)
print(len(history.history['loss']))
Epoch 1/100
469/469 [==============================] - 4s 4ms/step - loss: 6.0013 - sparse_categorical_accuracy: 0.7898 - val_loss: 0.6480 - val_sparse_categorical_accuracy: 0.8295
Epoch 2/100
469/469 [==============================] - 1s 3ms/step - loss: 0.5175 - sparse_categorical_accuracy: 0.8734 - val_loss: 0.4707 - val_sparse_categorical_accuracy: 0.8874
Epoch 3/100
469/469 [==============================] - 2s 3ms/step - loss: 0.3890 - sparse_categorical_accuracy: 0.9046 - val_loss: 0.4084 - val_sparse_categorical_accuracy: 0.9015
Epoch 4/100
469/469 [==============================] - 2s 4ms/step - loss: 0.3320 - sparse_categorical_accuracy: 0.9186 - val_loss: 0.3221 - val_sparse_categorical_accuracy: 0.9260
Epoch 5/100
469/469 [==============================] - 2s 4ms/step - loss: 0.3067 - sparse_categorical_accuracy: 0.9238 - val_loss: 0.3473 - val_sparse_categorical_accuracy: 0.9226
Epoch 6/100
469/469 [==============================] - 2s 4ms/step - loss: 0.3395 - sparse_categorical_accuracy: 0.9192 - val_loss: 0.3618 - val_sparse_categorical_accuracy: 0.9220
Epoch 7/100
469/469 [==============================] - 2s 4ms/step - loss: 0.3485 - sparse_categorical_accuracy: 0.9153 - val_loss: 0.4092 - val_sparse_categorical_accuracy: 0.9088
Epoch 8/100
469/469 [==============================] - 2s 3ms/step - loss: 0.3737 - sparse_categorical_accuracy: 0.9110 - val_loss: 0.4341 - val_sparse_categorical_accuracy: 0.9040
Epoch 9/100
469/469 [==============================] - 1s 3ms/step - loss: 0.3818 - sparse_categorical_accuracy: 0.9110 - val_loss: 0.4817 - val_sparse_categorical_accuracy: 0.9027
Epoch 90/100
469/469 [==============================] - 2s 3ms/step - loss: 0.5932 - sparse_categorical_accuracy: 0.8407 - val_loss: 2.8667 - val_sparse_categorical_accuracy: 0.8430
Epoch 91/100
469/469 [==============================] - 2s 3ms/step - loss: 0.5844 - sparse_categorical_accuracy: 0.8405 - val_loss: 2.2455 - val_sparse_categorical_accuracy: 0.8493
Epoch 92/100
469/469 [==============================] - 2s 3ms/step - loss: 0.5381 - sparse_categorical_accuracy: 0.8478 - val_loss: 2.2708 - val_sparse_categorical_accuracy: 0.8375
Epoch 93/100
469/469 [==============================] - 2s 3ms/step - loss: 0.5758 - sparse_categorical_accuracy: 0.8428 - val_loss: 2.2519 - val_sparse_categorical_accuracy: 0.8330
Epoch 94/100
469/469 [==============================] - 2s 4ms/step - loss: 0.5538 - sparse_categorical_accuracy: 0.8389 - val_loss: 2.2266 - val_sparse_categorical_accuracy: 0.8556
Epoch 95/100
469/469 [==============================] - 2s 4ms/step - loss: 0.5231 - sparse_categorical_accuracy: 0.8549 - val_loss: 2.2041 - val_sparse_categorical_accuracy: 0.8387
Epoch 96/100
469/469 [==============================] - 2s 4ms/step - loss: 0.5309 - sparse_categorical_accuracy: 0.8523 - val_loss: 1.8817 - val_sparse_categorical_accuracy: 0.8488
Epoch 97/100
469/469 [==============================] - 2s 4ms/step - loss: 0.5543 - sparse_categorical_accuracy: 0.8489 - val_loss: 2.2095 - val_sparse_categorical_accuracy: 0.8420
Epoch 98/100
469/469 [==============================] - 2s 4ms/step - loss: 0.5450 - sparse_categorical_accuracy: 0.8445 - val_loss: 2.8616 - val_sparse_categorical_accuracy: 0.8561
Epoch 99/100
469/469 [==============================] - 2s 4ms/step - loss: 0.5727 - sparse_categorical_accuracy: 0.8471 - val_loss: 2.3409 - val_sparse_categorical_accuracy: 0.8386
Epoch 100/100
469/469 [==============================] - 2s 4ms/step - loss: 0.5674 - sparse_categorical_accuracy: 0.8422 - val_loss: 2.3284 - val_sparse_categorical_accuracy: 0.8505
100
2. Tensorboard 시작하기
- Tensorboard를 시작하기 위해서는 Train 도중이나 종료한 후에 Tensorboard Callback 정의시에 지정한 Folder가 있는 위치에서 아래와 같이 명령어를 입력합니다.

-
tensorboard 명령어를 입력하고, –logdir 파라미터 뒤에 Histogram이 저장된 Folder를 입력합니다.
-
위와 같이 출력이 나온 후에, Web Browser를 열고, 주소 입력란에 “localhost:6006” 이라고 입력해 줍니다.
- 그러면, 아래와 같은 UI가 나오면서 Tensorboard가 실행되는 모습을 볼 수 있습니다.
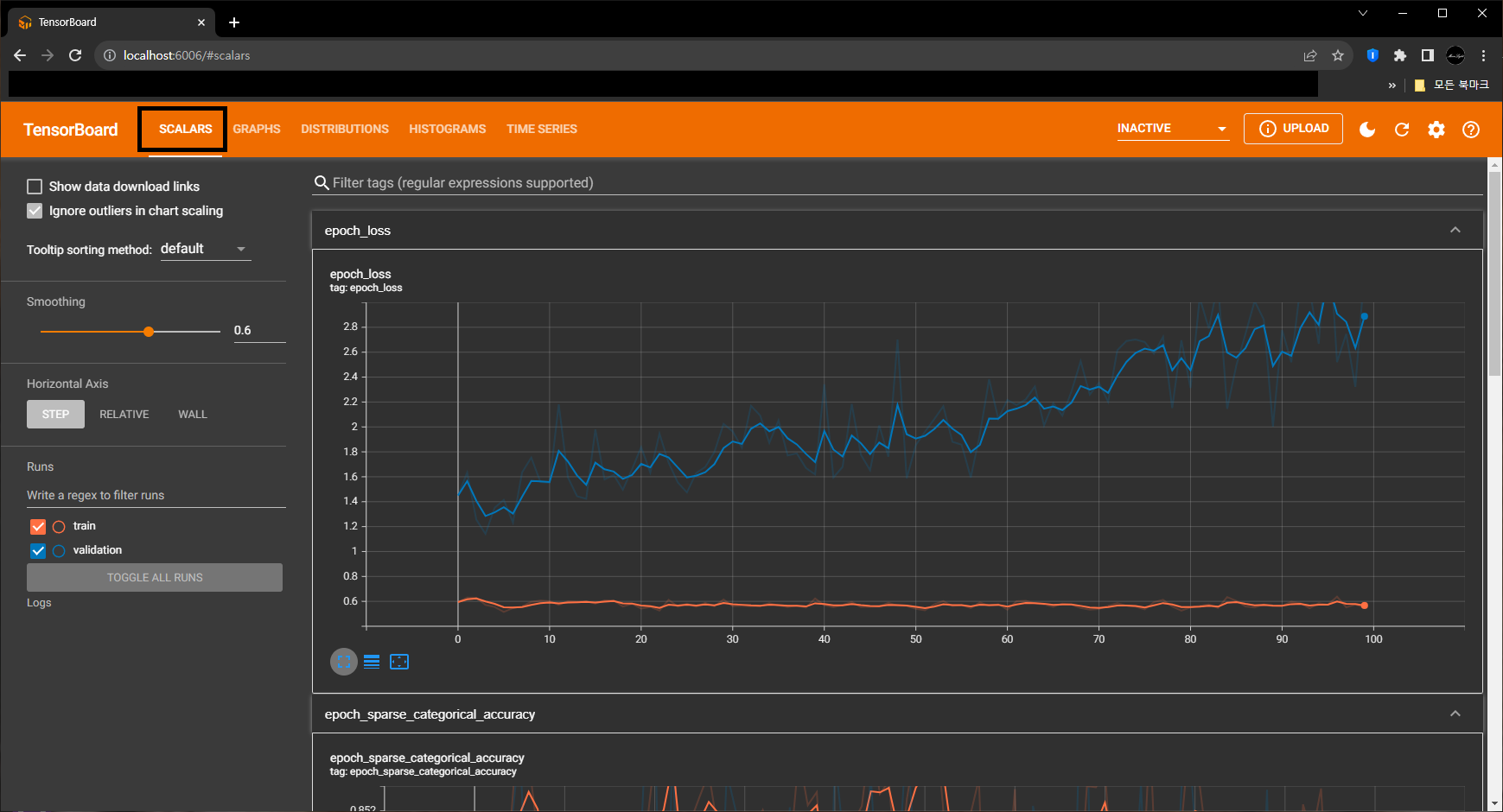
- 먼저, 아래는 ‘Scalars’ Tab의 모습이며, Epoch마다 loss / Accuracy와 같은 Train 지표들이 출력됩니다.
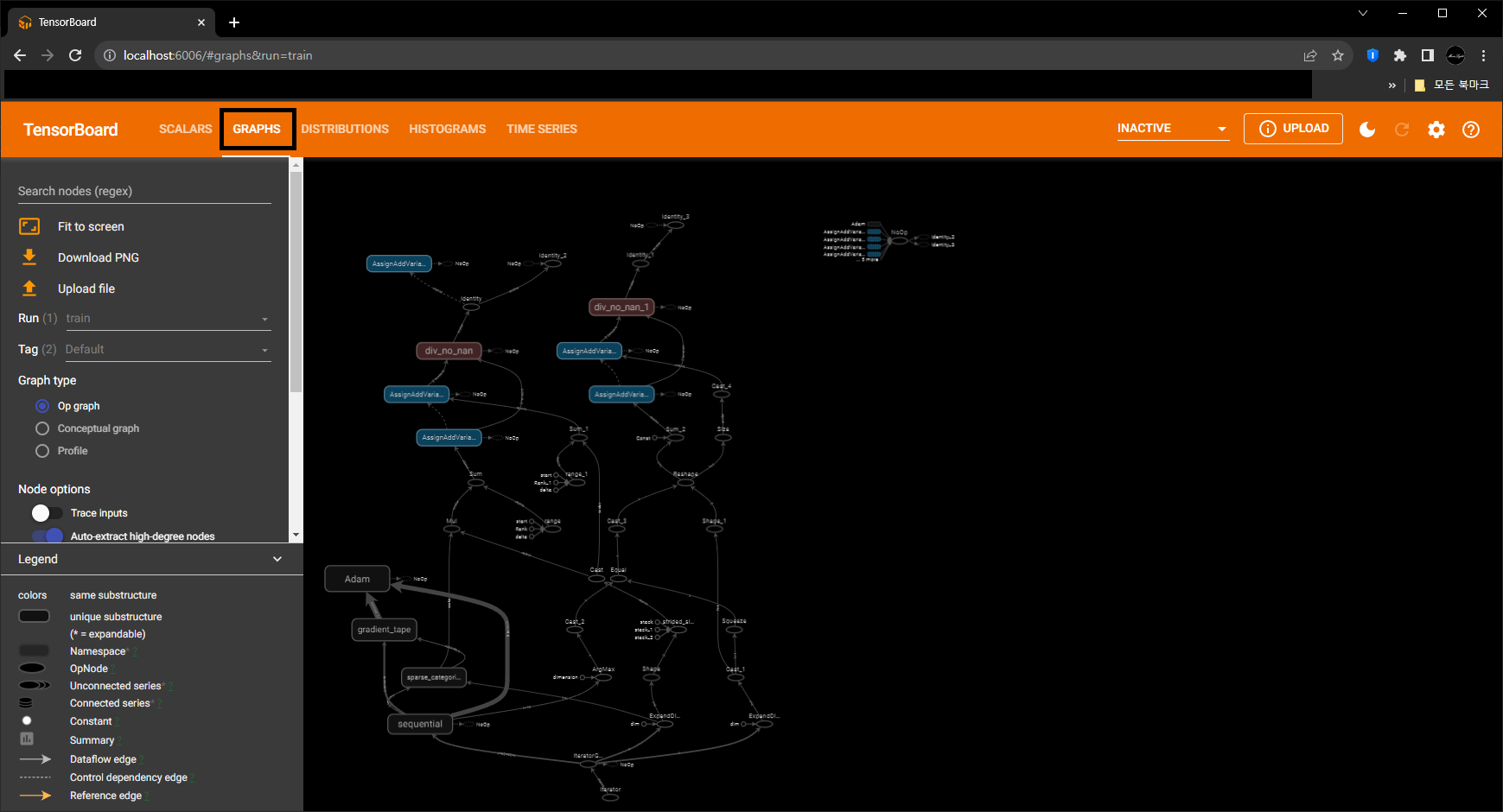
- ‘GRAPHS’ Tab에는 Model의 구조를 Graph 형태로 보여줍니다.
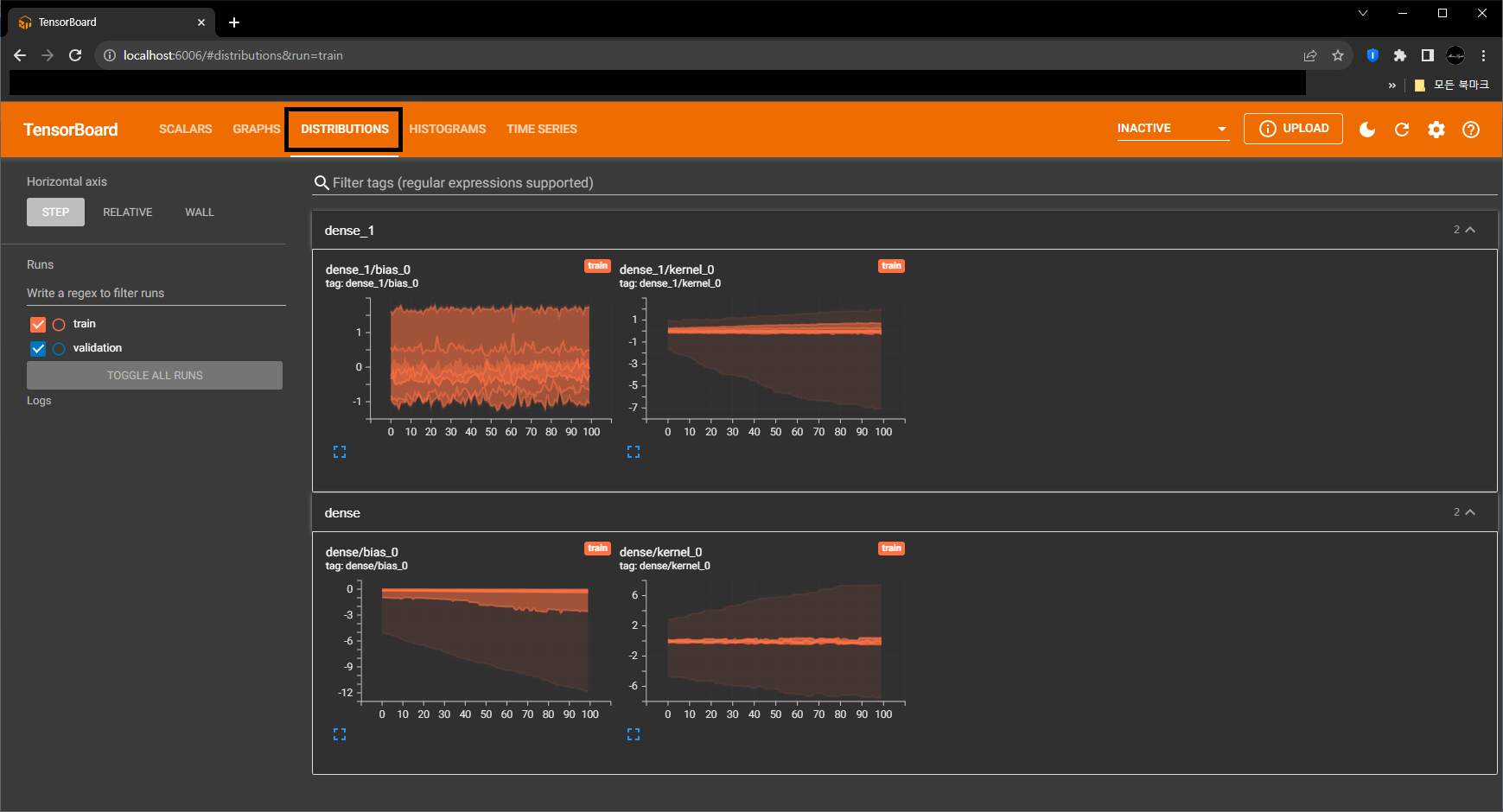
- Model Tensor 값의 분포를 2D 형태로 보여줍니다.
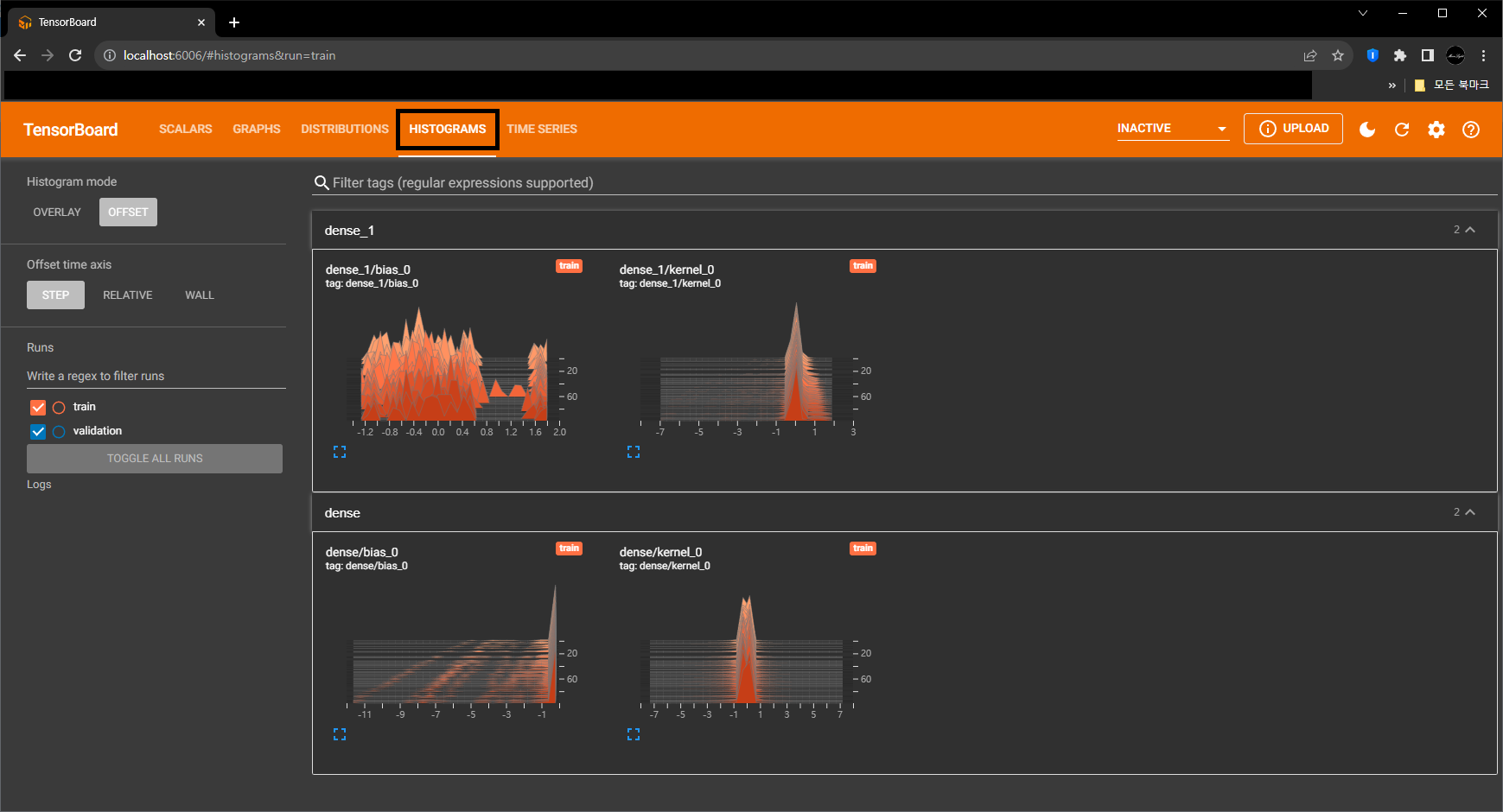
- Model Tensor 값의 분포를 3D 형태로 보여줍니다.
-
이번 Post에서는 Tensorboard의 기능과 사용법을 간단하게 알아보았습니다.
-
글을 읽으시는 분들에게 조금이나마 도움이 되었으면 좋겠네요.
-
글 읽어 주셔서 감사합니다.