Hand Gesture Detection - Rev #03
Hand Gesture Detection - Rev #03
0. Overview
- 지난 번 Conv3D를 이용한 Post( https://moonlight314.github.io/deep/learning/Hand_Gesture_Detection_Rev_02/ )에서 다룬 방식은 학습이 제대로 이루어 지지 않았습니다.
- 이번 Post에서는 동영상 각 Frame을 Image처럼 처리하고, Image에 Pre-Trained Model을 이용하여 Feature를 뽑은 다음, 이 Feature들을 RNN에 넣어서 Hand Gesture Detection을 진행해 보도록 하겠습니다.
- 전체적인 진행 방식은 아래와 같습니다.
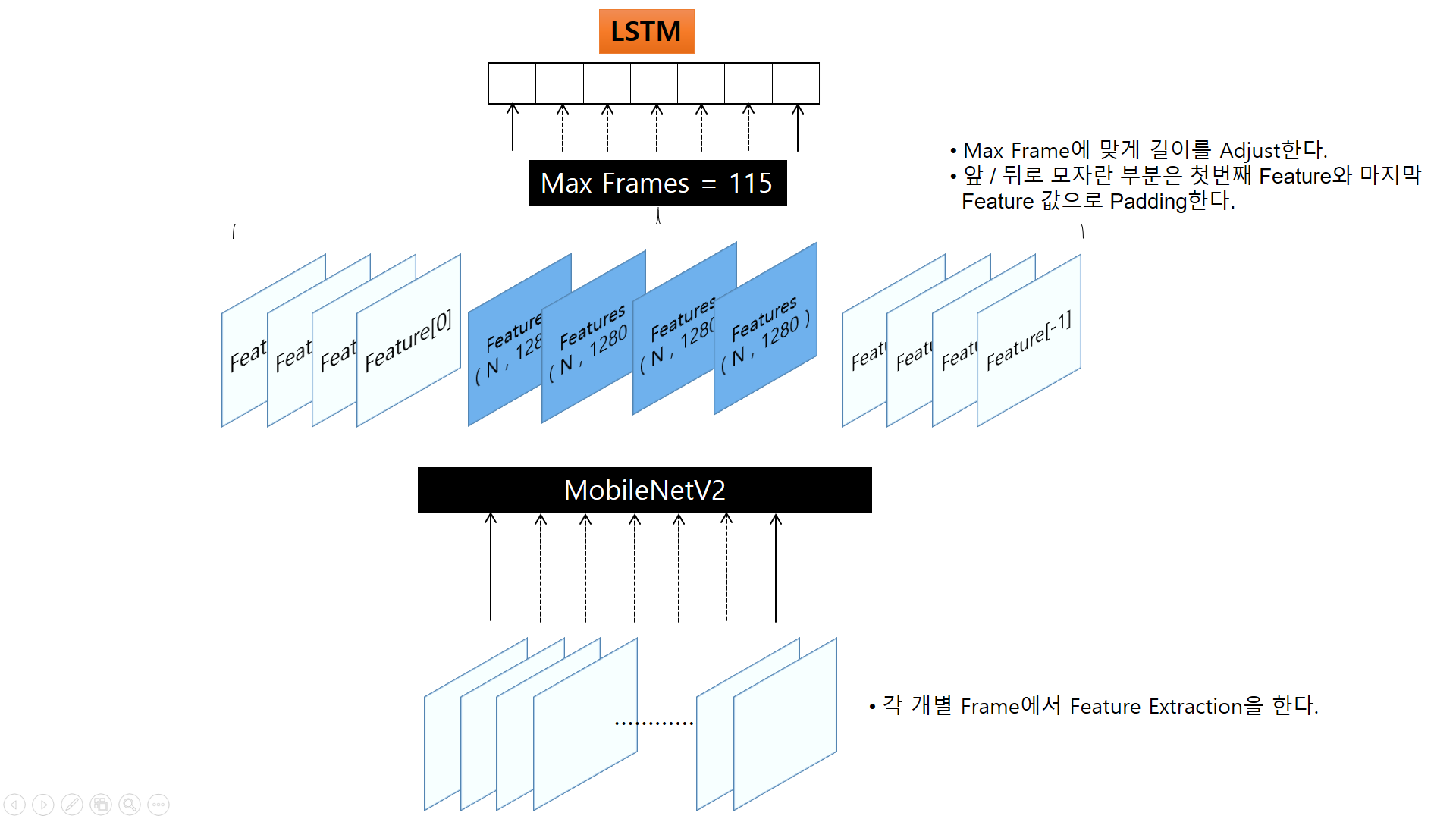
- Image에서 Feature를 Extract를 할 Pre-Trained Model로는 MobileNetV2를 사용하도록 하겠습니다.
1. Load Module
- 필요한 Module을 Load합니다.
- 특별한 Module은 없고, 늘 사용하던 Module들입니다.
import pandas as pd
import cv2 as cv
import numpy as np
from collections import deque
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
import tensorflow as tf
from tensorflow.keras.applications import MobileNetV2
from tensorflow.keras.applications.mobilenet_v2 import preprocess_input
from tensorflow.keras.models import Sequential , Model
from tensorflow.keras.layers import LSTM, Dense, Bidirectional , Dropout , BatchNormalization , GlobalAveragePooling2D
2. Feature Extractor
- 상수들을 정의합니다.
MAX_FRAME = 128
BATCH_SIZE = 32
EPOCHS = 5
DEST_SIZE = (160,160)
- 앞서 말했듯이 Feature Extractor로 MobileNetV2를 사용하도록 하겠습니다.
- Weight는 Imagenet용으로 초기화하고 Top은 날립니다.
- 1차원 Shape으로 만들기 위해 AveragePooling을 사용하고, Freeze 시킵니다.
- 이것으로 Image로 부터 Feature를 뽑아낼 준비는 끝났습니다.
def Feature_Extractor():
model = Sequential()
model.add( MobileNetV2(include_top = False,
input_shape=(160, 160, 3),
))
model.add(GlobalAveragePooling2D())
model.trainable = False
return model
3. RNN Model
- RNN Model도 앞선 Post에서와 유사하게 만들었습니다.
- 다만, Input Shape은 Feature Extractor의 Output을 감안하여 변형하였습니다.
def Make_RNN_Model():
model = Sequential()
model.add(Bidirectional( LSTM(512, return_sequences=True , activation='tanh'), input_shape=(MAX_FRAME , 1280)))
model.add(Bidirectional( LSTM(256, return_sequences=True , activation='tanh')))
model.add(Bidirectional( LSTM(64, return_sequences=False , activation='tanh')))
model.add(Dense(32, activation='relu'))
model.add(Dense(4, activation='softmax'))
return model
4. Generate Train Data
- 손 동작을 녹화한 Video File로 부터 Feature Extraction하고 모두 동일한 Frame Size로 Length를 맞추는 함수들입니다.
- Adjust_Length는 Feature의 Length가 Max Frame과 맞지 않은 경우 앞뒤로 Dummy Data를 붙여서 Length를 모두 동일하도록 해줍니다.
def Adjust_Length( data ):
# Dummy Data로 사용할 Feature
# 앞쪽은 가장 앞쪽으로 채우고, 뒤쪽은 가장 뒤쪽의 Data로 채운다.
front = data[0]
back = data[-1]
d = np.array(data)
data = deque(data)
length = d.shape[0]
for _ in range(int((MAX_FRAME - length)/2)):
data.append( back )
data.appendleft( front )
if len(data) != MAX_FRAME:
data.append( back )
aligned_data = np.array(data)
return aligned_data
- generate_train_data 함수는 실제 동영상 File을 읽어서 각 Frame을 Feature Extractor에 넣어 결과를 모은 후, 앞서 설명한 Adjust 과정을 거쳐 RNN Model의 입력에 넣을 수 있도록 Train Data를 생성하는 일을 합니다.
def generate_train_data( file_path , label , feature_extractor):
output = []
for f in file_path:
batch_frames = []
filename = f.replace("./Train_Data","C:/Users/csyi/Desktop/Hand_Gesture_Detection/Train_Data")
filename = filename.replace("'","")
cap = cv.VideoCapture( filename )
if cap.isOpened() == False:
print("Open Error")
data = deque([])
while( True ):
ret, frame = cap.read()
if ret == False:
break
frame = cv.resize( frame, dsize=DEST_SIZE, interpolation=cv.INTER_AREA )
frame = tf.keras.applications.mobilenet_v2.preprocess_input( frame )
batch_frames.append( frame )
batch_frames = np.reshape( np.array(batch_frames) , (-1,160,160,3))
ret = feature_extractor.predict_on_batch( batch_frames )
data = Adjust_Length( ret )
output.append(data)
output = np.reshape(np.array(output) , (-1,128,1280))
label = np.reshape(np.array(label) , (-1,4))
return output , label
- Feature Extractor인 MobileNetV2의 구조입니다.
# Load Feature Extractor
feature_extractor = Feature_Extractor()
feature_extractor.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
mobilenetv2_1.00_160 (Functi (None, 5, 5, 1280) 2257984
_________________________________________________________________
global_average_pooling2d (Gl (None, 1280) 0
=================================================================
Total params: 2,257,984
Trainable params: 0
Non-trainable params: 2,257,984
_________________________________________________________________
- RNN도 만들어 볼까요?
RNN_Model = Make_RNN_Model()
RNN_Model.compile( optimizer=tf.keras.optimizers.Adam(1e-3),
loss='categorical_crossentropy',
metrics=['categorical_accuracy']
)
- Meta Data File을 읽어옵니다.
# Load meta data file
meta = pd.read_csv("Meta_Data_220117_Rev_01.csv")
# Data File Path
file_path = meta['file_path'].tolist()
# Label
labels = meta['action'].tolist()
print(len(file_path) , len(labels))
389 389
- Label도 준비합니다.
le = LabelEncoder()
le_action = le.fit(labels)
le_action = le.transform(labels)
print(le.classes_)
y = tf.keras.utils.to_categorical(le_action, num_classes=4)
print(y)
['1_Finger_Click' '2_Fingers_Left' '2_Fingers_Right' 'Shake_Hand']
[[1. 0. 0. 0.]
[1. 0. 0. 0.]
[1. 0. 0. 0.]
...
[0. 0. 0. 1.]
[0. 0. 0. 1.]
[0. 0. 0. 1.]]
# Train / Test 나누기
X_train, X_test, y_train, y_test = train_test_split(file_path, y, test_size=0.25 , stratify = y)
tmp_val_data = []
tmp_val_target = []
- 대망의 Training Stage입니다.
- Feature Extractor에서 나온 값을 RNN의 Input으로 넣는 과정으로 진행됩니다.
for epoch in range(EPOCHS):
print("### Epoch : {0} ###\n\n".format(epoch))
for idx in range( 0 , len(X_train) , BATCH_SIZE):
tmp_train_data = []
tmp_target = []
batch_file_list = []
batch_target = []
for batch in range(BATCH_SIZE):
if idx+batch >= len(X_train):
break
batch_file_list.append( X_train[idx+batch] )
batch_target.append( y_train[idx+batch] )
train_data , target = generate_train_data( batch_file_list, batch_target , feature_extractor)
RNN_Model.fit( x = train_data,
y = target,
verbose=1)
# Eval.
print("### Evaluation... Epoch : {0} ###".format(epoch))
if len(tmp_val_data) == 0:
tmp_val_data , tmp_val_target = generate_train_data( X_test , y_test , feature_extractor)
ret = RNN_Model.evaluate(tmp_val_data , tmp_val_target )
### Epoch : 0 ###
1/1 [==============================] - 6s 6s/step - loss: 1.3582 - categorical_accuracy: 0.2188
1/1 [==============================] - 0s 246ms/step - loss: 1.6103 - categorical_accuracy: 0.2812
1/1 [==============================] - 0s 248ms/step - loss: 1.9793 - categorical_accuracy: 0.0938
1/1 [==============================] - 0s 246ms/step - loss: 1.2979 - categorical_accuracy: 0.4062
1/1 [==============================] - 0s 244ms/step - loss: 1.4777 - categorical_accuracy: 0.1875
1/1 [==============================] - 0s 247ms/step - loss: 1.3085 - categorical_accuracy: 0.2812
1/1 [==============================] - 0s 247ms/step - loss: 1.3324 - categorical_accuracy: 0.2188
1/1 [==============================] - 0s 247ms/step - loss: 1.2749 - categorical_accuracy: 0.4062
1/1 [==============================] - 0s 244ms/step - loss: 1.1534 - categorical_accuracy: 0.4375
1/1 [==============================] - 4s 4s/step - loss: 1.1634 - categorical_accuracy: 0.0000e+00
### Evaluation... Epoch : 0 ###
4/4 [==============================] - 2s 89ms/step - loss: 1.2826 - categorical_accuracy: 0.4592
### Epoch : 1 ###
1/1 [==============================] - 0s 246ms/step - loss: 1.2443 - categorical_accuracy: 0.4375
1/1 [==============================] - 0s 245ms/step - loss: 1.1586 - categorical_accuracy: 0.4688
1/1 [==============================] - 0s 243ms/step - loss: 1.0803 - categorical_accuracy: 0.6562
1/1 [==============================] - 0s 246ms/step - loss: 0.9259 - categorical_accuracy: 0.7812
1/1 [==============================] - 0s 243ms/step - loss: 0.9260 - categorical_accuracy: 0.5938
1/1 [==============================] - 0s 240ms/step - loss: 0.7924 - categorical_accuracy: 0.7500
1/1 [==============================] - 0s 244ms/step - loss: 0.6781 - categorical_accuracy: 0.8125
1/1 [==============================] - 0s 247ms/step - loss: 0.5861 - categorical_accuracy: 0.8438
1/1 [==============================] - 0s 238ms/step - loss: 0.5703 - categorical_accuracy: 0.8438
1/1 [==============================] - 0s 106ms/step - loss: 0.5877 - categorical_accuracy: 1.0000
### Evaluation... Epoch : 1 ###
4/4 [==============================] - 0s 88ms/step - loss: 0.8222 - categorical_accuracy: 0.6020
### Epoch : 2 ###
1/1 [==============================] - 0s 240ms/step - loss: 0.7703 - categorical_accuracy: 0.5938
1/1 [==============================] - 0s 239ms/step - loss: 0.6549 - categorical_accuracy: 0.8438
1/1 [==============================] - 0s 245ms/step - loss: 0.6331 - categorical_accuracy: 0.8438
1/1 [==============================] - 0s 242ms/step - loss: 0.5142 - categorical_accuracy: 0.8125
1/1 [==============================] - 0s 228ms/step - loss: 0.4535 - categorical_accuracy: 0.7812
1/1 [==============================] - 0s 251ms/step - loss: 0.3349 - categorical_accuracy: 0.8438
1/1 [==============================] - 0s 244ms/step - loss: 0.2939 - categorical_accuracy: 1.0000
1/1 [==============================] - 0s 243ms/step - loss: 0.3022 - categorical_accuracy: 1.0000
1/1 [==============================] - 0s 242ms/step - loss: 0.2264 - categorical_accuracy: 0.9688
1/1 [==============================] - 0s 107ms/step - loss: 0.1069 - categorical_accuracy: 1.0000
### Evaluation... Epoch : 2 ###
4/4 [==============================] - 0s 87ms/step - loss: 0.2742 - categorical_accuracy: 0.9184
### Epoch : 3 ###
1/1 [==============================] - 0s 249ms/step - loss: 0.2286 - categorical_accuracy: 0.9688
1/1 [==============================] - 0s 248ms/step - loss: 0.2914 - categorical_accuracy: 0.9688
1/1 [==============================] - 0s 241ms/step - loss: 0.2398 - categorical_accuracy: 1.0000
1/1 [==============================] - 0s 247ms/step - loss: 0.1969 - categorical_accuracy: 0.9688
1/1 [==============================] - 0s 242ms/step - loss: 0.1515 - categorical_accuracy: 1.0000
1/1 [==============================] - 0s 245ms/step - loss: 0.2328 - categorical_accuracy: 0.8438
1/1 [==============================] - 0s 248ms/step - loss: 0.1201 - categorical_accuracy: 1.0000
1/1 [==============================] - 0s 247ms/step - loss: 0.2063 - categorical_accuracy: 0.9375
1/1 [==============================] - 0s 241ms/step - loss: 0.0878 - categorical_accuracy: 1.0000
1/1 [==============================] - 0s 105ms/step - loss: 0.0248 - categorical_accuracy: 1.0000
### Evaluation... Epoch : 3 ###
4/4 [==============================] - 0s 87ms/step - loss: 0.1733 - categorical_accuracy: 0.9490
### Epoch : 4 ###
1/1 [==============================] - 0s 241ms/step - loss: 0.1172 - categorical_accuracy: 0.9688
1/1 [==============================] - 0s 243ms/step - loss: 0.1761 - categorical_accuracy: 0.9688
1/1 [==============================] - 0s 250ms/step - loss: 0.2952 - categorical_accuracy: 0.8750
1/1 [==============================] - 0s 244ms/step - loss: 0.1936 - categorical_accuracy: 0.9688
1/1 [==============================] - 0s 243ms/step - loss: 0.3419 - categorical_accuracy: 0.9062
1/1 [==============================] - 0s 244ms/step - loss: 0.1645 - categorical_accuracy: 0.9375
1/1 [==============================] - 0s 239ms/step - loss: 0.3557 - categorical_accuracy: 0.8438
1/1 [==============================] - 0s 253ms/step - loss: 0.1632 - categorical_accuracy: 0.9688
1/1 [==============================] - 0s 243ms/step - loss: 0.1602 - categorical_accuracy: 0.9688
1/1 [==============================] - 0s 107ms/step - loss: 0.0483 - categorical_accuracy: 1.0000
### Evaluation... Epoch : 4 ###
4/4 [==============================] - 0s 86ms/step - loss: 0.4784 - categorical_accuracy: 0.8469
- 다행히도 Training이 되네요. Train / Validation Data 모두에서 Loss / Acc.가 좋아지는 모습을 볼 수 있습니다.