Hand Gesture Detection - Rev #02
Hand Gesture Detection - Rev #02
0. Overview
- 이번 Post에서는 지난 Post(Hand Gesture Detection - Rev#01)에서 사용했던 방법과 약간 다른 방법을 사용해 보도록 하겠습니다.
- 이번에 적용할 방법은 3D Convolution을 이용한 방법입니다.
- 영상은 각 Frame의 연속적인 모음이며, 이런 형태의 자료 구조에 기존 2D Conv.가 아닌 3D Conv.를 적용할 수 있습니다.
-
3D Conv.를 이해하기 위한 글입니다.
-
3D Conv.를 이용한 행동 인식 관련 글
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=khm159&logNo=222027509486
https://22-22.tistory.com/74
- 영상을 특정 Frame 수로 묶고, 이를 3D Conv.에 넣어서 나온 Feature들의 값을 RNN의 입력으로 넣고 최종적으로 RNN 출력으로 Hand Gesture Detection을 수행하는 방법으로 진행합니다.
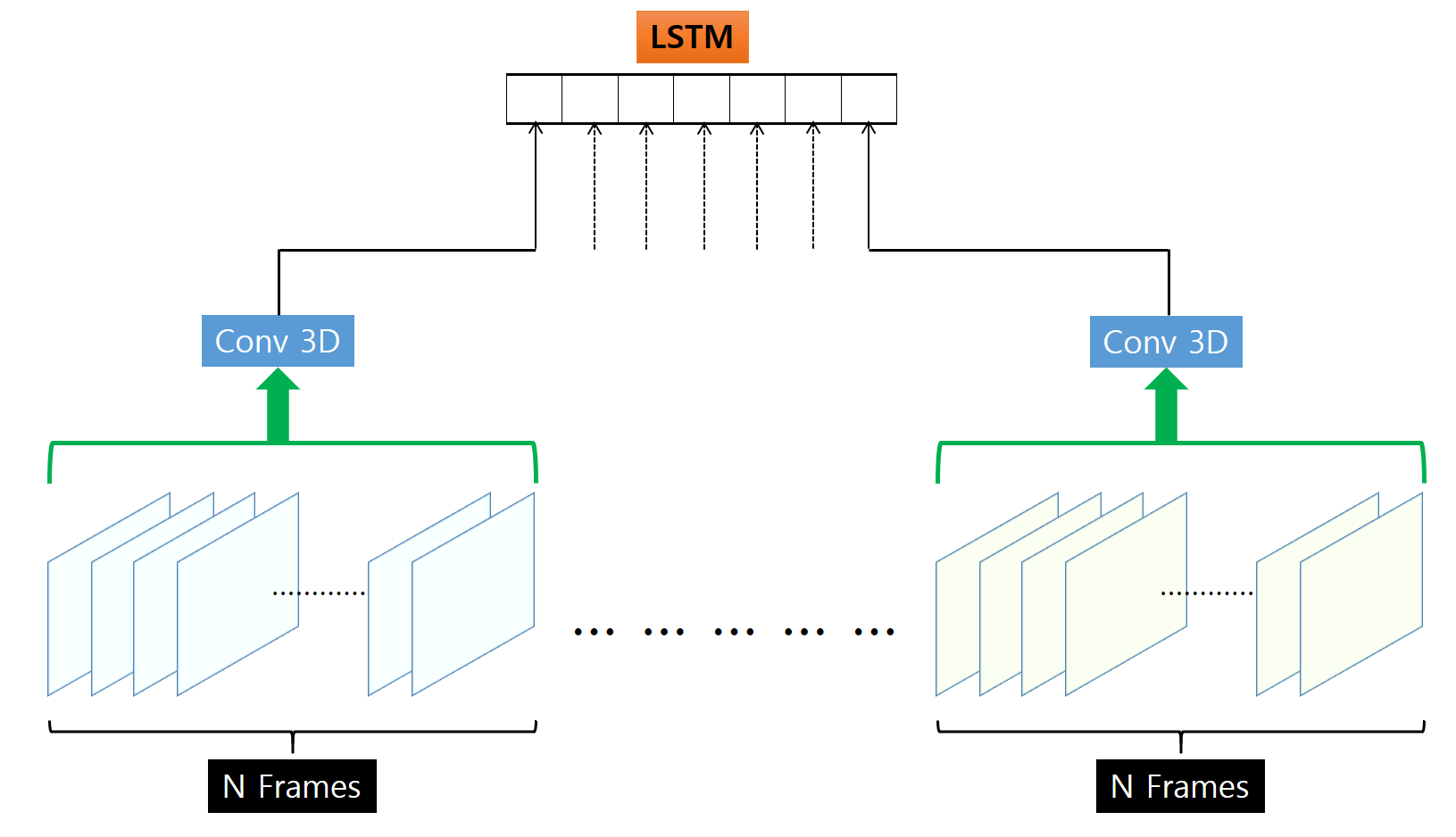
1. Pre-Trained C3D
- Conv. 3D도 Conv. 2D 처럼 특정 Dataset에서 학습된 Pre-Trained Model이 있습니다.
-
이번에 사용할 Pre-Trained C3D Model은 아래 Link에서 가져왔습니다.
- 이 Pre-Trained C3D Model을 선택한 이유는, 1) Keras를 사용하였고 2) Model 구조가 공개되어 있고 3) 해당 Model 구조의 Trained Weight를 구할 수 있기 때문입니다.
- 이 Model의 Train에 사용된 Dataset은 Sports1M Dataset입니다.
- Sports1M dataset은 1,133,158개의 영상으로 구성되어 있고, 총 487개의 종류로 구성되어 있습니다.
- 저는 이 Dataset으로 Train된 Weight를 Load하여 Feature Extractor로 사용할 예정입니다.
2. Load Module
- Conv. 3D를 사용하기 위해서 Conv3D / MaxPooling3D / ZeroPadding3D 와 같은 Module을 Import합니다.
import numpy as np
import tensorflow as tf
import pandas as pd
from collections import deque
import cv2 as cv
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from tensorflow.keras.models import Sequential , Model
from tensorflow.keras.layers import LSTM, Dense, Bidirectional , Dropout , BatchNormalization , Conv3D , MaxPooling3D , Flatten , ZeroPadding3D , Input
- 이 Pre-Trained Model의 Input Shape은 (16, 112, 112, 3)입니다.
- 하나의 Image가 3 Channel (112 x 112)이며 이런 Image가 16개 한 묶음으로 Conv 3D의 Input으로 넣겠다는 뜻입니다.
- 이 Pre-Trained Model을 그대로 사용하기 위해서는 이 Input Shape을 바꿀 수 없습니다. 만약 Input Shape을 바꾸고자 한다면 Sports1M dataset으로 새롭게 정의한 Input Shape & Model Structure로 다시 Train을 해야 합니다.
- 하지만, 저 방대한 양의 Dataset을 다시 학습하는것은 현실적으로 힘든 일이므로, Input Shape을 그대로 사용하도록 하겠습니다.
- MAX_FRAME은 영상의 길이를 동일하게 해야하는데, 그 길이를 나타내는 값입니다. 짧으면 앞/뒤로 Padding합니다.
DEST_SIZE = (112 , 112)
MAX_FRAME = 128
BATCH_SIZE = 8
FRAME_SIZE = 16
EPOCHS = 5
- 아래의 Network이 Feature Extractor로 사용할 Conv. 3D의 구조입니다.
def C3Dnet(nb_classes, input_shape):
input_tensor = Input(shape=input_shape)
# 1st block
x = Conv3D(64, [3,3,3], activation='relu', padding='same', strides=(1,1,1), name='conv1')(input_tensor)
x = MaxPooling3D(pool_size=(1,2,2), strides=(1,2,2), padding='valid', name='pool1')(x)
# 2nd block
x = Conv3D(128, [3,3,3], activation='relu', padding='same', strides=(1,1,1), name='conv2')(x)
x = MaxPooling3D(pool_size=(2,2,2), strides=(2,2,2), padding='valid', name='pool2')(x)
# 3rd block
x = Conv3D(256, [3,3,3], activation='relu', padding='same', strides=(1,1,1), name='conv3a')(x)
x = Conv3D(256, [3,3,3], activation='relu', padding='same', strides=(1,1,1), name='conv3b')(x)
x = MaxPooling3D(pool_size=(2,2,2), strides=(2,2,2), padding='valid', name='pool3')(x)
# 4th block
x = Conv3D(512, [3,3,3], activation='relu', padding='same', strides=(1,1,1), name='conv4a')(x)
x = Conv3D(512, [3,3,3], activation='relu', padding='same', strides=(1,1,1), name='conv4b')(x)
x= MaxPooling3D(pool_size=(2,2,2), strides=(2,2,2), padding='valid', name='pool4')(x)
# 5th block
x = Conv3D(512, [3,3,3], activation='relu', padding='same', strides=(1,1,1), name='conv5a')(x)
x = Conv3D(512, [3,3,3], activation='relu', padding='same', strides=(1,1,1), name='conv5b')(x)
x = ZeroPadding3D(padding=(0,1,1),name='zeropadding')(x)
x= MaxPooling3D(pool_size=(2,2,2), strides=(2,2,2), padding='valid', name='pool5')(x)
# full connection
x = Flatten()(x)
x = Dense(4096, activation='relu', name='fc6')(x)
x = Dropout(0.5)(x)
x = Dense(4096, activation='relu', name='fc7')(x)
x = Dropout(0.5)(x)
output_tensor = Dense(nb_classes, activation='softmax', name='fc8')(x)
model = Model(input_tensor, output_tensor)
return model
- 위에서 정의한 C3D Net을 이용하여 Model을 만들고, Pre-Trained Weight를 Load합니다.
- 마지막 Dense Layer는 제외하고, Weight를 고정해서 Feature Extractor로 사용합니다.
def Feature_Extractor():
C3D_net = C3Dnet(487, (16, 112, 112, 3))
# 위에서 정의한 C3D Net을 이용하여 Model을 만들고, Pre-Trained Weight를 Load합니다.
C3D_net.load_weights("./C3D_Sport1M_weights_keras_2.2.4.h5")
# 마지막 Dense Layer는 제외하고, Weight를 고정해서 Feature Extractor로 사용합니다.
model = Model(C3D_net.input , C3D_net.layers[-2].output )
model.trainable = False
return model
- C3D Feature Extractor에서 나온 값들은 RNN의 Input으로 들어갑니다.
- C3D Feature Extractor의 Output Shape은 4096이고, 이것은 Batch Size만큼 모아서 RNN의 Input으로 넣어줍니다.
def Make_Sequential_Model():
model = Sequential()
model.add(Bidirectional( LSTM(1024, return_sequences=True , activation='tanh'), input_shape=(8,4096)))
model.add(Bidirectional( LSTM(256, return_sequences=True , activation='tanh')))
model.add(Bidirectional( LSTM(64, return_sequences=False , activation='tanh')))
model.add(Dense(32, activation='relu'))
model.add(Dense(4, activation='softmax'))
return model
- 아래 Adjust_Length는 각 Data 영상마다 다른 Frame 길이를 일정한 길이로 맞추는 함수입니다.
- MAX_FRAME(=128)로 맞추되, 모자란 길이는 영상 앞뒤로 Zero Padding합니다.
def Adjust_Length( data ):
# 목적은 ( MAX_FRAME , 112 , 112 , 3) 형태로 만드는 것
zero = np.zeros_like( data[0] )
d = np.array(data)
length = d.shape[0]
for _ in range(int((MAX_FRAME - length)/2)):
data.append( zero )
data.appendleft( zero )
if len(data) != MAX_FRAME:
data.append( zero )
aligned_data = np.array(data)
return aligned_data
- 아래 generate_train_data 함수는 영상을 읽어서 MAX FRAME으로 길이를 맞춘 다음에 C3D Feature Extractor에 넣어서 RNN Input으로 사용할 수 있도록 만들어줍니다.
def generate_train_data( file_path , label , feature_extractor):
filename = file_path.replace("./Train_Data","C:/Users/Moon/Desktop/Hand_Gesture_Detection/Train_Data")
filename = filename.replace("'","")
cap = cv.VideoCapture( filename )
# 값들을 255로 나누기
if cap.isOpened() == False:
print("Open Error")
data = deque([])
while( True ):
ret, frame = cap.read()
if ret == False:
break
frame = cv.resize( frame, dsize=DEST_SIZE, interpolation=cv.INTER_AREA )
data.append( frame )
# Frame 수를 모두 동일하게 맞춥니다.
data = Adjust_Length( data )
data = data / 255
output = []
# Shape을 C3D Input Shape에 맞춥니다.
data = np.reshape(data, (-1 , FRAME_SIZE , 112,112,3) )
# C3D Feature Extractor에 넣어서 Feature를 뽑아냅니다.
output = feature_extractor.predict_on_batch( data )
output = np.reshape(np.array(output) , (-1,4096))
return output , label
- 사용할 C3D Feature Extactor의 전체 구조는 아래와 같습니다.
# Load C3D Feature Extractor
feature_extractor = Feature_Extractor()
feature_extractor.summary()
Model: "model_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 16, 112, 112, 3)] 0
_________________________________________________________________
conv1 (Conv3D) (None, 16, 112, 112, 64) 5248
_________________________________________________________________
pool1 (MaxPooling3D) (None, 16, 56, 56, 64) 0
_________________________________________________________________
conv2 (Conv3D) (None, 16, 56, 56, 128) 221312
_________________________________________________________________
pool2 (MaxPooling3D) (None, 8, 28, 28, 128) 0
_________________________________________________________________
conv3a (Conv3D) (None, 8, 28, 28, 256) 884992
_________________________________________________________________
conv3b (Conv3D) (None, 8, 28, 28, 256) 1769728
_________________________________________________________________
pool3 (MaxPooling3D) (None, 4, 14, 14, 256) 0
_________________________________________________________________
conv4a (Conv3D) (None, 4, 14, 14, 512) 3539456
_________________________________________________________________
conv4b (Conv3D) (None, 4, 14, 14, 512) 7078400
_________________________________________________________________
pool4 (MaxPooling3D) (None, 2, 7, 7, 512) 0
_________________________________________________________________
conv5a (Conv3D) (None, 2, 7, 7, 512) 7078400
_________________________________________________________________
conv5b (Conv3D) (None, 2, 7, 7, 512) 7078400
_________________________________________________________________
zeropadding (ZeroPadding3D) (None, 2, 9, 9, 512) 0
_________________________________________________________________
pool5 (MaxPooling3D) (None, 1, 4, 4, 512) 0
_________________________________________________________________
flatten (Flatten) (None, 8192) 0
_________________________________________________________________
fc6 (Dense) (None, 4096) 33558528
_________________________________________________________________
dropout (Dropout) (None, 4096) 0
_________________________________________________________________
fc7 (Dense) (None, 4096) 16781312
_________________________________________________________________
dropout_1 (Dropout) (None, 4096) 0
=================================================================
Total params: 77,995,776
Trainable params: 0
Non-trainable params: 77,995,776
_________________________________________________________________
- RNN Model을 만들고, Compile까지 합니다.
# Make RNN Model
seq_model = Make_Sequential_Model()
seq_model.summary()
seq_model.compile( optimizer=tf.keras.optimizers.Adam(1e-3),
loss='categorical_crossentropy',
metrics=['categorical_accuracy']
)
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
bidirectional (Bidirectional (None, 8, 2048) 41951232
_________________________________________________________________
bidirectional_1 (Bidirection (None, 8, 512) 4720640
_________________________________________________________________
bidirectional_2 (Bidirection (None, 128) 295424
_________________________________________________________________
dense (Dense) (None, 32) 4128
_________________________________________________________________
dense_1 (Dense) (None, 4) 132
=================================================================
Total params: 46,971,556
Trainable params: 46,971,556
Non-trainable params: 0
_________________________________________________________________
- Train에 사용할 영상 정보를 가지고 있는 CSV File을 Load합니다.
# Load meta data file
meta = pd.read_csv("Meta_Data_220117_Rev_01.csv")
# Data File Path
file_path = meta['file_path'].tolist()
# Label
labels = meta['action'].tolist()
- Train에 사용하기 위해 Target을 One-Hoe Encoding합니다.
le = LabelEncoder()
le_action = le.fit(labels)
le_action = le.transform(labels)
print(le.classes_)
y = tf.keras.utils.to_categorical(le_action, num_classes=4)
print(y)
['1_Finger_Click' '2_Fingers_Left' '2_Fingers_Right' 'Shake_Hand']
[[1. 0. 0. 0.]
[1. 0. 0. 0.]
[1. 0. 0. 0.]
...
[0. 0. 0. 1.]
[0. 0. 0. 1.]
[0. 0. 0. 1.]]
# Train / Test 나누기
X_train, X_test, y_train, y_test = train_test_split(file_path, y, test_size=0.25 , stratify = y)
- 이번에 사용한 방법은 Feature Extract를 할 때, 즉, Data Generator에서 사용해야 할 함수가 Tensorflow Model이고 Feature Extract를 할 때 GPU를 사용하기 때문에 기존의 방식대로 datagen이나 tf.dataset을 사용할 수가 없었습니다.
- 대신, datagen이나 tf.dataset과 동일한 동작을 하는 함수를 만들어서 Train을 했습니다.
tmp_val_data = []
tmp_val_target = []
for epoch in range(EPOCHS):
print("### Epoch : {0} ###\n\n".format(epoch))
# Batch Size 만큼 읽어서 Train 시킵니다.
for idx in range( 0 , len(X_train) , BATCH_SIZE):
tmp_train_data = []
tmp_target = []
for batch in range(BATCH_SIZE):
if idx+batch >= len(X_train):
break
# 영상을 읽어서 C3D 에서 Feature를 뽑아내서, RNN에 넣을 수 있는 구조로 만드는 역할까지 합니다.
train_data , target = generate_train_data( X_train[ idx+batch ], y_train[ idx+batch ] , feature_extractor)
tmp_train_data.append( train_data )
tmp_target.append( target )
train_data = np.reshape(tmp_train_data, (-1,8,4096))
target = np.reshape(tmp_target, (-1,4))
# 만들어진 Data로 RNN을 Train 합니다.
seq_model.fit( x = train_data,
y = target,
verbose=1)
# 1 Epoch이 끝날때 마다, Evaluation합니다.
print("### Evaluation... Epoch : {0} ###".format(epoch))
if len(tmp_val_data) == 0:
for idx in range( 0 , len(X_test)):
train_data , target = generate_train_data( X_test[ idx ], y_test[ idx ] , feature_extractor)
tmp_val_data.append( train_data )
tmp_val_target.append( target )
tmp_val_data = np.reshape(tmp_val_data, (-1,8,4096))
tmp_val_target = np.reshape(tmp_val_target, (-1,4))
ret = seq_model.evaluate(tmp_val_data , tmp_val_target )
### Epoch : 0 ###
1/1 [==============================] - 4s 4s/step - loss: 1.4279 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 16ms/step - loss: 1.1928 - categorical_accuracy: 0.2500
1/1 [==============================] - 0s 31ms/step - loss: 2.4987 - categorical_accuracy: 0.2500
1/1 [==============================] - 0s 16ms/step - loss: 1.5794 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 19ms/step - loss: 1.4461 - categorical_accuracy: 0.3750
1/1 [==============================] - 0s 16ms/step - loss: 1.5991 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 31ms/step - loss: 1.5265 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 31ms/step - loss: 1.4167 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 16ms/step - loss: 1.3157 - categorical_accuracy: 0.3750
1/1 [==============================] - 0s 16ms/step - loss: 1.4203 - categorical_accuracy: 0.2500
1/1 [==============================] - 0s 31ms/step - loss: 1.3069 - categorical_accuracy: 0.2500
1/1 [==============================] - 0s 16ms/step - loss: 1.2287 - categorical_accuracy: 0.5000
1/1 [==============================] - 0s 31ms/step - loss: 1.4218 - categorical_accuracy: 0.2500
1/1 [==============================] - 0s 31ms/step - loss: 1.4587 - categorical_accuracy: 0.2500
1/1 [==============================] - 0s 31ms/step - loss: 1.5761 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 16ms/step - loss: 1.4586 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 207ms/step - loss: 1.4610 - categorical_accuracy: 0.2500
1/1 [==============================] - 0s 31ms/step - loss: 1.3884 - categorical_accuracy: 0.3750
1/1 [==============================] - 0s 24ms/step - loss: 1.2640 - categorical_accuracy: 0.7500
1/1 [==============================] - 0s 16ms/step - loss: 1.3346 - categorical_accuracy: 0.5000
1/1 [==============================] - 0s 16ms/step - loss: 1.3762 - categorical_accuracy: 0.2500
1/1 [==============================] - 0s 31ms/step - loss: 1.3078 - categorical_accuracy: 0.5000
1/1 [==============================] - 0s 16ms/step - loss: 1.5419 - categorical_accuracy: 0.0000e+00
1/1 [==============================] - 0s 31ms/step - loss: 1.4597 - categorical_accuracy: 0.0000e+00
1/1 [==============================] - 0s 31ms/step - loss: 1.4766 - categorical_accuracy: 0.0000e+00
1/1 [==============================] - 0s 16ms/step - loss: 1.3807 - categorical_accuracy: 0.2500
1/1 [==============================] - 0s 25ms/step - loss: 1.4251 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 20ms/step - loss: 1.4114 - categorical_accuracy: 0.3750
1/1 [==============================] - 0s 31ms/step - loss: 1.4339 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 31ms/step - loss: 1.3666 - categorical_accuracy: 0.3750
1/1 [==============================] - 0s 16ms/step - loss: 1.3910 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 16ms/step - loss: 1.3994 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 31ms/step - loss: 1.3798 - categorical_accuracy: 0.3750
1/1 [==============================] - 0s 31ms/step - loss: 1.3840 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 25ms/step - loss: 1.3743 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 23ms/step - loss: 1.3717 - categorical_accuracy: 0.3750
1/1 [==============================] - 0s 16ms/step - loss: 1.3426 - categorical_accuracy: 0.3333
### Evaluation... Epoch : 0 ###
4/4 [==============================] - 1s 15ms/step - loss: 1.3886 - categorical_accuracy: 0.2449
### Epoch : 1 ###
1/1 [==============================] - 0s 16ms/step - loss: 1.4295 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 16ms/step - loss: 1.4374 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 16ms/step - loss: 1.3764 - categorical_accuracy: 0.2500
1/1 [==============================] - 0s 24ms/step - loss: 1.4013 - categorical_accuracy: 0.2500
1/1 [==============================] - 0s 16ms/step - loss: 1.4067 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 16ms/step - loss: 1.3601 - categorical_accuracy: 0.3750
1/1 [==============================] - 0s 19ms/step - loss: 1.3763 - categorical_accuracy: 0.2500
1/1 [==============================] - 0s 31ms/step - loss: 1.3745 - categorical_accuracy: 0.3750
1/1 [==============================] - 0s 16ms/step - loss: 1.3852 - categorical_accuracy: 0.3750
1/1 [==============================] - 0s 16ms/step - loss: 1.4130 - categorical_accuracy: 0.2500
1/1 [==============================] - 0s 16ms/step - loss: 1.3867 - categorical_accuracy: 0.2500
1/1 [==============================] - 0s 32ms/step - loss: 1.3688 - categorical_accuracy: 0.5000
1/1 [==============================] - 0s 22ms/step - loss: 1.3879 - categorical_accuracy: 0.2500
1/1 [==============================] - 0s 16ms/step - loss: 1.3773 - categorical_accuracy: 0.2500
1/1 [==============================] - 0s 24ms/step - loss: 1.4118 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 31ms/step - loss: 1.4176 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 31ms/step - loss: 1.3929 - categorical_accuracy: 0.2500
1/1 [==============================] - 0s 16ms/step - loss: 1.3985 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 31ms/step - loss: 1.3917 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 16ms/step - loss: 1.3851 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 16ms/step - loss: 1.3856 - categorical_accuracy: 0.3750
1/1 [==============================] - 0s 23ms/step - loss: 1.3634 - categorical_accuracy: 0.2500
1/1 [==============================] - 0s 16ms/step - loss: 1.4412 - categorical_accuracy: 0.0000e+00
1/1 [==============================] - 0s 24ms/step - loss: 1.4104 - categorical_accuracy: 0.0000e+00
1/1 [==============================] - 0s 16ms/step - loss: 1.4243 - categorical_accuracy: 0.0000e+00
1/1 [==============================] - 0s 16ms/step - loss: 1.3787 - categorical_accuracy: 0.2500
1/1 [==============================] - 0s 31ms/step - loss: 1.4098 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 16ms/step - loss: 1.4090 - categorical_accuracy: 0.3750
1/1 [==============================] - 0s 31ms/step - loss: 1.4331 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 16ms/step - loss: 1.3639 - categorical_accuracy: 0.3750
1/1 [==============================] - 0s 31ms/step - loss: 1.3925 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 31ms/step - loss: 1.4002 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 16ms/step - loss: 1.3794 - categorical_accuracy: 0.2500
1/1 [==============================] - 0s 16ms/step - loss: 1.3549 - categorical_accuracy: 0.3750
1/1 [==============================] - 0s 31ms/step - loss: 1.3650 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 31ms/step - loss: 1.4002 - categorical_accuracy: 0.3750
1/1 [==============================] - 0s 16ms/step - loss: 1.3729 - categorical_accuracy: 0.6667
### Evaluation... Epoch : 1 ###
4/4 [==============================] - 0s 12ms/step - loss: 1.3856 - categorical_accuracy: 0.2551
### Epoch : 2 ###
1/1 [==============================] - 0s 16ms/step - loss: 1.3870 - categorical_accuracy: 0.0000e+00
1/1 [==============================] - 0s 24ms/step - loss: 1.4109 - categorical_accuracy: 0.0000e+00
1/1 [==============================] - 0s 31ms/step - loss: 1.3826 - categorical_accuracy: 0.3750
1/1 [==============================] - 0s 24ms/step - loss: 1.3858 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 16ms/step - loss: 1.3837 - categorical_accuracy: 0.2500
1/1 [==============================] - 0s 26ms/step - loss: 1.3802 - categorical_accuracy: 0.3750
1/1 [==============================] - 0s 16ms/step - loss: 1.3820 - categorical_accuracy: 0.3750
1/1 [==============================] - 0s 25ms/step - loss: 1.3900 - categorical_accuracy: 0.2500
1/1 [==============================] - 0s 16ms/step - loss: 1.3886 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 16ms/step - loss: 1.4054 - categorical_accuracy: 0.0000e+00
1/1 [==============================] - 0s 16ms/step - loss: 1.3768 - categorical_accuracy: 0.2500
1/1 [==============================] - 0s 31ms/step - loss: 1.3766 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 31ms/step - loss: 1.3871 - categorical_accuracy: 0.2500
1/1 [==============================] - 0s 16ms/step - loss: 1.3805 - categorical_accuracy: 0.3750
1/1 [==============================] - 0s 16ms/step - loss: 1.4101 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 31ms/step - loss: 1.4109 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 16ms/step - loss: 1.3949 - categorical_accuracy: 0.2500
1/1 [==============================] - 0s 16ms/step - loss: 1.3958 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 31ms/step - loss: 1.3859 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 16ms/step - loss: 1.3833 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 31ms/step - loss: 1.3930 - categorical_accuracy: 0.3750
1/1 [==============================] - 0s 31ms/step - loss: 1.3689 - categorical_accuracy: 0.2500
1/1 [==============================] - 0s 16ms/step - loss: 1.4251 - categorical_accuracy: 0.0000e+00
1/1 [==============================] - 0s 31ms/step - loss: 1.4059 - categorical_accuracy: 0.0000e+00
1/1 [==============================] - 0s 16ms/step - loss: 1.4201 - categorical_accuracy: 0.0000e+00
1/1 [==============================] - 0s 31ms/step - loss: 1.3859 - categorical_accuracy: 0.2500
1/1 [==============================] - 0s 31ms/step - loss: 1.3959 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 16ms/step - loss: 1.4012 - categorical_accuracy: 0.3750
1/1 [==============================] - 0s 16ms/step - loss: 1.4116 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 16ms/step - loss: 1.3717 - categorical_accuracy: 0.3750
1/1 [==============================] - 0s 24ms/step - loss: 1.3894 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 31ms/step - loss: 1.3987 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 38ms/step - loss: 1.3775 - categorical_accuracy: 0.2500
1/1 [==============================] - 0s 25ms/step - loss: 1.3585 - categorical_accuracy: 0.5000
1/1 [==============================] - 0s 16ms/step - loss: 1.3677 - categorical_accuracy: 0.6250
1/1 [==============================] - 0s 17ms/step - loss: 1.3944 - categorical_accuracy: 0.3750
1/1 [==============================] - 0s 23ms/step - loss: 1.3685 - categorical_accuracy: 0.6667
### Evaluation... Epoch : 2 ###
4/4 [==============================] - 0s 12ms/step - loss: 1.3856 - categorical_accuracy: 0.2551
### Epoch : 3 ###
1/1 [==============================] - 0s 16ms/step - loss: 1.3893 - categorical_accuracy: 0.0000e+00
1/1 [==============================] - 0s 31ms/step - loss: 1.4143 - categorical_accuracy: 0.0000e+00
1/1 [==============================] - 0s 31ms/step - loss: 1.3831 - categorical_accuracy: 0.3750
1/1 [==============================] - 0s 31ms/step - loss: 1.3842 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 16ms/step - loss: 1.3842 - categorical_accuracy: 0.2500
1/1 [==============================] - 0s 16ms/step - loss: 1.3797 - categorical_accuracy: 0.3750
1/1 [==============================] - 0s 31ms/step - loss: 1.3829 - categorical_accuracy: 0.3750
1/1 [==============================] - 0s 31ms/step - loss: 1.3905 - categorical_accuracy: 0.2500
1/1 [==============================] - 0s 16ms/step - loss: 1.3872 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 16ms/step - loss: 1.4039 - categorical_accuracy: 0.0000e+00
1/1 [==============================] - 0s 16ms/step - loss: 1.3741 - categorical_accuracy: 0.2500
1/1 [==============================] - 0s 31ms/step - loss: 1.3768 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 16ms/step - loss: 1.3870 - categorical_accuracy: 0.2500
1/1 [==============================] - 0s 31ms/step - loss: 1.3819 - categorical_accuracy: 0.3750
1/1 [==============================] - 0s 31ms/step - loss: 1.4091 - categorical_accuracy: 0.2500
1/1 [==============================] - 0s 16ms/step - loss: 1.4069 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 16ms/step - loss: 1.3958 - categorical_accuracy: 0.2500
1/1 [==============================] - 0s 16ms/step - loss: 1.3925 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 16ms/step - loss: 1.3795 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 31ms/step - loss: 1.3811 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 16ms/step - loss: 1.3911 - categorical_accuracy: 0.3750
1/1 [==============================] - 0s 31ms/step - loss: 1.3675 - categorical_accuracy: 0.2500
1/1 [==============================] - 0s 31ms/step - loss: 1.4254 - categorical_accuracy: 0.0000e+00
1/1 [==============================] - 0s 31ms/step - loss: 1.4062 - categorical_accuracy: 0.0000e+00
1/1 [==============================] - 0s 16ms/step - loss: 1.4198 - categorical_accuracy: 0.0000e+00
1/1 [==============================] - 0s 31ms/step - loss: 1.3862 - categorical_accuracy: 0.2500
1/1 [==============================] - 0s 16ms/step - loss: 1.3952 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 16ms/step - loss: 1.4000 - categorical_accuracy: 0.3750
1/1 [==============================] - 0s 31ms/step - loss: 1.4099 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 16ms/step - loss: 1.3722 - categorical_accuracy: 0.3750
1/1 [==============================] - 0s 16ms/step - loss: 1.3896 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 16ms/step - loss: 1.3988 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 31ms/step - loss: 1.3776 - categorical_accuracy: 0.2500
1/1 [==============================] - 0s 31ms/step - loss: 1.3588 - categorical_accuracy: 0.3750
1/1 [==============================] - 0s 16ms/step - loss: 1.3686 - categorical_accuracy: 0.6250
1/1 [==============================] - 0s 31ms/step - loss: 1.3951 - categorical_accuracy: 0.3750
1/1 [==============================] - 0s 16ms/step - loss: 1.3699 - categorical_accuracy: 0.6667
### Evaluation... Epoch : 3 ###
4/4 [==============================] - 0s 12ms/step - loss: 1.3855 - categorical_accuracy: 0.2551
### Epoch : 4 ###
1/1 [==============================] - 0s 16ms/step - loss: 1.3872 - categorical_accuracy: 0.0000e+00
1/1 [==============================] - 0s 16ms/step - loss: 1.4132 - categorical_accuracy: 0.0000e+00
1/1 [==============================] - 0s 31ms/step - loss: 1.3838 - categorical_accuracy: 0.3750
1/1 [==============================] - 0s 16ms/step - loss: 1.3830 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 31ms/step - loss: 1.3833 - categorical_accuracy: 0.2500
1/1 [==============================] - 0s 31ms/step - loss: 1.3807 - categorical_accuracy: 0.3750
1/1 [==============================] - 0s 16ms/step - loss: 1.3836 - categorical_accuracy: 0.3750
1/1 [==============================] - 0s 31ms/step - loss: 1.3912 - categorical_accuracy: 0.2500
1/1 [==============================] - 0s 31ms/step - loss: 1.3869 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 16ms/step - loss: 1.4028 - categorical_accuracy: 0.0000e+00
1/1 [==============================] - 0s 31ms/step - loss: 1.3733 - categorical_accuracy: 0.2500
1/1 [==============================] - 0s 31ms/step - loss: 1.3774 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 16ms/step - loss: 1.3869 - categorical_accuracy: 0.2500
1/1 [==============================] - 0s 16ms/step - loss: 1.3826 - categorical_accuracy: 0.3750
1/1 [==============================] - 0s 31ms/step - loss: 1.4081 - categorical_accuracy: 0.2500
1/1 [==============================] - 0s 16ms/step - loss: 1.4050 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 31ms/step - loss: 1.3958 - categorical_accuracy: 0.2500
1/1 [==============================] - 0s 16ms/step - loss: 1.3913 - categorical_accuracy: 0.2500
1/1 [==============================] - 0s 16ms/step - loss: 1.3777 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 31ms/step - loss: 1.3806 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 31ms/step - loss: 1.3910 - categorical_accuracy: 0.3750
1/1 [==============================] - 0s 31ms/step - loss: 1.3682 - categorical_accuracy: 0.2500
1/1 [==============================] - 0s 31ms/step - loss: 1.4230 - categorical_accuracy: 0.0000e+00
1/1 [==============================] - 0s 31ms/step - loss: 1.4052 - categorical_accuracy: 0.0000e+00
1/1 [==============================] - 0s 31ms/step - loss: 1.4184 - categorical_accuracy: 0.0000e+00
1/1 [==============================] - 0s 16ms/step - loss: 1.3869 - categorical_accuracy: 0.2500
1/1 [==============================] - 0s 16ms/step - loss: 1.3935 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 31ms/step - loss: 1.3988 - categorical_accuracy: 0.3750
1/1 [==============================] - 0s 31ms/step - loss: 1.4071 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 31ms/step - loss: 1.3734 - categorical_accuracy: 0.3750
1/1 [==============================] - 0s 16ms/step - loss: 1.3892 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 16ms/step - loss: 1.3984 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 16ms/step - loss: 1.3776 - categorical_accuracy: 0.2500
1/1 [==============================] - 0s 31ms/step - loss: 1.3597 - categorical_accuracy: 0.3750
1/1 [==============================] - 0s 31ms/step - loss: 1.3694 - categorical_accuracy: 0.1250
1/1 [==============================] - 0s 16ms/step - loss: 1.3947 - categorical_accuracy: 0.3750
1/1 [==============================] - 0s 31ms/step - loss: 1.3703 - categorical_accuracy: 0.6667
### Evaluation... Epoch : 4 ###
4/4 [==============================] - 0s 12ms/step - loss: 1.3855 - categorical_accuracy: 0.2551
- 결론적으로 Train이 잘 되지 않습니다.
- 원인을 추측해 보자면, 동영상을 Frame 단위로 나눠서 Conv. 3D를 활용한 Feature 분류는 그렇게 좋은 성능을 내지 못하는 것으로 보입니다.
- Conv. 3D 구조의 문제인지 Conv. 3D가 동영상에는 잘 맞지 않는 것인지는 확실히 모르겠습니다.